The part of mathematics in which letters and other general symbols are used to represent numbers and quantities in formula and equations.
Ex: (x + y) · z = (x · z) + (y · z).
The main application of relational algebra is providing a theoretical foundation for relational databases, particularly query languages for such databases.
Relational algebra is a formal system for manipulating relations.
Operands of this algebra are relations.
Operations of this algebra include the usual set operations (since relations are sets of tuples), and special operations defined for relations
selection
projection
join
The Relational Model
Data and relationships are represented by a collection of tables.
Each table has a number of columns with unique names, e.g. customer, account.
Example of a Relation
Attribute Types
The set of allowed values for each attribute is called the domain of the attribute
Attribute values are (normally) required to be atomic; that is, indivisible
The special valuenull is a member of every domain
The null value causes complications in the definition of many operations
There are five major components in the database system environment and their interrelationships are.
Hardware
Software
Data
Users
Procedures
Hardware:
The hardware is the actual computer system used for keeping and accessing the database.
Conventional DBMS hardware consists of secondary storage devices, usually hard disks, on which the database physically resides.
Databases run on a range of machines, from Microcomputers to large mainframes.
Software:
The software is the actual DBMS.
All requests from users for accessing to the database are handled by the DBMS.
One general function provided by the DBMS is thus the shielding of database users from complex hardware-level detail.
The DBMS allows the users to communicate with the database. In a sense, it is the mediator between the database and the users.
The DBMS controls the access and helps to maintain the consistency of the data. Utilities are usually included as part of the DBMS. Some of the most common utilities are report writers and application development.
Data :
It is the most important component of DBMS environment from the end users point of view.
The database contains the operational data and the meta data, the ‘data about data‘(a set of data that describes and gives information about other data).
Users :
There are a number of users who can access or retrieve data on demand using the applications and interfaces provided by the DBMS.
The users of a database system can be classified in the following groups, depending on their degrees of expertise or the mode of their interactions with the DBMS. The users can be:
Naive Users
Online Users
Application Programmers
Sophisticated Users
Data Base Administrator (DBA)
Users
Naive Users:
Naive Users are those users who need not be aware of the presence of the database system or any other system supporting their usage.
Naive users are end users of the database who work through a menu driven application program, where the type and range of response is always indicated to the user.
Online Users :
Online users are those who may communicate with the database directly via an online terminal or indirectly via a user interface and application program.
These users are aware of the presence of the database system and may have acquired a certain amount of expertise with in the limited interaction permitted with a database.
Sophisticated Users :
Such users interact with the system without writing programs.
Instead, they form their requests in database query language. Each query is submitted to a processor whose function is to breakdown DML statement into instructions that the storage manager understands.
Application Programmers:
Professional programmers are those who are responsible for developing application programs or user interface.
The application programs could be written using general purpose programming language or the commands available to manipulate a database.
Database Administrator:
The database administrator (DBA) is the person or group in charge for implementing the database system within an organization.
The DBA has all the system privileges allowed by the DBMS and can assign (grant) and remove (revoke) levels of access (privileges) to and from other users.
DBA is also responsible for the evaluation, selection and implementation of DBMS package.
Components of the Database System Environment
Procedures:
Procedures refer to the instructions and rules that govern the design and use of the database.
The users of the system and the staff that manage the database require documented procedures on how to use or run the system.
Procedures:
These may consist of instructions on how to:
Log on to the DBMS.
Use a particular DBMS facility or application program.
Start and stop the DBMS.
Make backup copies of the database.
Handle hardware or software failures.
Change the structure of a table, reorganize the database across multiple disks, improve performance, or archive data to secondary storage.
A DBMS must provide appropriate languages and interfaces for each category of users to express database queries and updates.
Database Languages are used to create and maintain database on computer.
There are large numbers of database languages like Oracle, MySQL, MS Access, dBase, FoxPro etc.
Database Languages: Refers to the languages used to interact with databases, such as SQL (Structured Query Language).
Data-Definition: Involves commands used to define and modify database structures, like creating or altering tables.
Create Table Test (
Title Varchar2(20));
Create Table Test: An SQL command to create a new table named “Test”.Title Varchar2(20): Specifies a column named “Title” with a data type of VARCHAR2 and a maximum length of 20 characters.
Data-Manipulation: Commands used to manipulate data within the database, such as inserting, updating, or deleting records.
Update: An SQL command used to modify existing records in a table. Insert: An SQL command used to add new records to a table. Delete: An SQL command used to remove records from a table. Query: Refers to the process of requesting data from a database, typically using SELECT statements.
Data-Control: Commands related to controlling access to the data, such as granting or revoking permissions. GRANT Connect, Resource TO xUser: An SQL command to grant specific privileges (Connect and Resource) to a user named “xUser”.
Data Definition Language (DDL)
SQL statements commonly used in Oracle and MS Access can be categorized as
Data Definition Language (DDL),
Data Control Language (DCL)
Data Manipulation Language (DML).
Data Definition Language specify the database schema.
It is a language that allows the users to define data and their relationship to other types of data.
It is mainly used to create databases, data dictionary and tables within databases.
It is also used to specify the structure of each table, set of associated values with each attribute, integrity constraints, security and authorization information for each table and physical storage structure of each table on disk.
The following table gives an overview about usage of DDL statements in SQL
S.No
Need & Usage
He SQL DDL statement
1
Create schema objects
Create
2
Alter schema objects
Alter
3
Delete schema objects
Drop
4
Rename schema objects
Rename
DDL Example:
Example: create tableinstructor ( IDchar(5), name varchar(20), dept_name varchar(20), salarynumeric(30)
)
Instructor Table
ID
Name
Department
Salary
22222
Einstein
Physics
95000
12121
Wu
Finance
90000
32343
El Said
History
60000
45565
Katz
Comp. Sci.
75000
98345
Kim
Elec. Eng.
80000
76766
Crick
Biology
72000
10101
Srinivasan
Comp. Sci.
65000
58583
Califieri
History
62000
83821
Brandt
Comp. Sci.
92000
15151
Mozart
Music
40000
33456
Gold
Physics
87000
76543
Singh
Finance
80000
Department Table
Depthname
Building
Budget
Comp. Sci.
Taylor
100000
Biology
Watson
90000
Elec. Eng.
Taylor
85000
Music
Packard
80000
Finance
Painter
120000
History
Painter
50000
Physics
Watson
70000
Write SQL code for creating the following
CREATE TABLE department (
dept_name CHAR(20),
building CHAR(15),
budget NUMERIC(12,2)
);
This SQL statement defines a table named department with three columns:
dept_name of type CHAR(20)
building of type CHAR(15)
budget of type NUMERIC(12,2)
Data Manipulation Language (DML)
It is a language that provides a set of operations to support the basic data manipulation operations on the data held in the databases.
It allows users to insert, update, delete and retrieve data from the database.
The part of DML that involves data retrieval is called a query language.
Two classes of DML languages
Procedural – user specifies what data is required and how to get those data
Declarative (nonprocedural) – user specifies what data is required without specifying how to get those data
SQL is the most widely used query language
The following table gives an overview about the usage of DML statements in SQL:
SQL DML Statements and Their Usage
S. No
Need and Usage
The SQL DML Statement
1
Remove rows from tables or views
DELETE
2
Add new rows of data into table or view
INSERT
3
Retrieve data from one or more tables
SELECT
4
Change column values in existing rows of a table or view
UPDATE
SQL: widely used non-procedural language
Example: Find the name of the instructor with ID 22222
select name from instructor whereinstructor.ID = ‘22222’
Example: Find the ID and building of instructors in the Physics dept.
select instructor.ID, department.building from instructor, department where instructor.dept_name =
department.dept_name and department.dept_name = ‘Physics’
Finds the names of all instructors in the History department.
Finds the names of all instructors in the History department.
SELECT instructor.name
FROM instructor
WHERE instructor.dept_name = ‘History’;
In this corrected query:
instructor.dept_name is used instead of instructor.dept.name to correctly reference the department name column.
Find the instructor ID and department name of all instructors associated with a department with budget of greater than $95,000.
SELECT instructor.ID, department.dept_name
FROM instructor
JOIN department ON instructor.dept_name = department.dept_name
WHERE department.budget > 95000;
In this version:
The JOIN clause is used to explicitly join the instructor and department tables on the dept_name column.
The WHERE clause filters the results to include only those departments with a budget greater than 95000.
Data Control Language (DCL)
DCL statements control access to data and the database using statements such as GRANT and REVOKE.
A privilege can either be granted to a User with the help of GRANT statement.
The privileges assigned can be SELECT, ALTER, DELETE, EXECUTE, INSERT, INDEX etc.
In addition to granting of privileges, you can also revoke (taken back) it by using REVOKE command.
The following table gives an overview about the usage of DCL statements in SQL:
Privileges and Data Dictionary Usage
S. No.
Need and Usage
Age
1
Grant and take away privileges and roles
Grant
2
Add a comment to the data dictionary
Comment
Database Language
In practice, the data definition and data manipulation languages are not two separate languages. Instead they simply form parts of a single database language such as Structured Query Language (SQL).
SQL represents combination of DDL ,DML and DCL, as well as statements for constraints specification and schema evaluation.
A Database Management System (DBMS) is a collection of interrelated data and a set of programs to access those data.
Database management systems (DBMS) are computer software applications that interact with the user, other applications, and the database itself to capture and analyze data.
Purpose of Database Systems
The collection of data, usually referred to as the database , contains information relevant to an enterprise.
The primary goal of a DBMS is to provide a way to store and retrieve database information that is both convenient and efficient.
A general-purpose DBMS is designed to allow the definition, creation, querying, update, and administration of databases.
Some application of DBMS
Enterprise Information:
◦ Sales: For customer, product, and purchase information.
◦ Accounting : For payments, receipts, account balances, assets and other Accounting information.
◦ Human resources: For information about employees, salaries, payroll taxes, and for generation of paychecks.
◦ Manufacturing: For management of the supply chain and for tracking production of items in factories, inventories of items in warehouses and stores, and orders for items.
Online retailers: For sales data noted above plus online order tracking, generation of recommendation lists, and maintenance of online product evaluations.
Banking and Finance
◦ Banking: For customer information, accounts, loans, and banking transactions.
◦ Credit card transactions : For purchases on credit cards and generation of monthly statements.
◦ Finance: For storing information about holdings, sales, and purchases of financial instruments such as stocks and bonds; also for storing real-time market data to enable online trading by customers and automated trading by the firm.
Universities : For student information, course registrations, and grades (in addition to standard enterprise information such as human resources and accounting).
Airlines: For reservations and schedule information. Airlines were among the first to use databases in a geographically distributed manner.
Telecommunication : For keeping records of calls made, generating monthly bills, maintaining balances on prepaid calling cards, and storing information about the communication networks.
University Database Example
Application program examples
Add new students, instructors, and courses
Register students for courses, and generate class rosters
Assign grades to students, compute grade point averages (GPA) and generate transcripts
In the early days, database applications were built directly on top of file systems.
File-processing system
A file processing system is a collection of files and programs that access/modify these files. Typically, new files and programs are added over time (by different programmers) as new information needs to be stored and new ways to access information are needed.
This typical file-processing system is supported by a conventional operating system.
The system stores permanent records in various files,
It needs different application programs to extract records from, and add records to, the appropriate files.
Disadvantages File-processing system
Major disadvantages of file processing system
Data redundancy and inconsistency .
Difficulty in accessing data.
Data isolation.
Integrity problems .
Atomicity problems
Concurrent-access anomalies.
Security problem
Drawbacks of using file systems
Data redundancy and inconsistency
Multiple file formats, duplication of information in different files
Difficulty in accessing data
Need to write a new program to carry out each new task
Data isolation — multiple files and formats
Integrity problems
Integrity constraints (e.g., account balance > 0) become “buried” in program code rather than being stated explicitly
Hard to add new constraints or change existing ones
Atomicity of updates
Failures may leave database in an inconsistent state with partial updates carried out
Example: Transfer of funds from one account to another should either complete or not happen at all
Concurrent access by multiple users
Concurrent access needed for performance
Uncontrolled concurrent accesses can lead to inconsistencies
Example: Two people reading a balance (say 100) and updating it by withdrawing money (say 50 each) at the same
Security problems
Hard to provide user access to some, but not all, data
Database systems offer solutions to all the above problems
Vi e w o f D a t a
A major purpose of a database system is to provide users with an abstract view of the data.
That is, the system hides certain details of how the data are stored and maintained.
Levels of Abstraction
Since many database-system users are not computer trained, developers hide the complexity from users through several levels of abstraction, to simplify users interactions with the system.
Physical level: The lowest level of abstraction describes how the data are stored. The physical level describes complex low-level data structures in detail.
Logical level: The next-higher level of abstraction describes what data are stored in the database, and what relationships exist among those data. The logical level thus describes the entire database in terms of a small number of relatively simple structures. Database administrators, who must decide what information to keep in the database, use the logical level of abstraction.
View level: The highest level of abstraction describes only part of the entire database. The view level of abstraction exists to simplify their interaction with the system. The system may provide many views for the same database.
Physical level: describes how a record (e.g., customer) is stored.
Logical level: describes data stored in database, and the relationships among the data.
typeinstructor = record
ID : string; name : string; dept_name : string; salary : integer;
end;
View level: application programs hide details of data types. Views can also hide information (such as an employee’s salary) for security purposes.
View of Data
+——————-+ +——————-+ +——————-+
| View 1 | | View 2 | … | View n |
+——————-+ +——————-+ +——————-+
| | |
v v v
+————————————————————-+
| Logical Level |
| – Entities |
| – Relationships |
| – Constraints |
+————————————————————-+
|
v
+————————————————————-+
| Physical Level |
| – Storage Structures |
| – Access Methods |
| – Indexing |
+————————————————————-+
An architecture for a database system
Instances and Schemas
Schema – The overall design of the database is called database schema. In short “the logical structure of the database”
Example: The database consists of information about a set of customers and accounts and the relationship between them
Physical schema: database design at the physical level
Logical schema: database design at the logical level
Subschema: database design at the view level which describe different views of the database.
Instance – The collection of information stored in the database at a particular moment is called an instance of the database. In short “the actual content of the database at a particular point in time”.
Physical Data Independence – the ability to modify the physical schema without changing the logical schema
Applications depend on the logical schema
In general, the interfaces between the various levels and components should be well defined so that changes in some parts do not seriously influence others.
ate an entirely 1 …………………………………… diet (2nd paragraph 3rd and 4th line)
1st and 2nd paragraph,
1st paragraph,resemblance to a dog. … dark brown stripes over its back, beginning at the rear of the body and extending onto the tail.
2nd paragraph, In terms of feeding, it was exclusively carnivorous(eat others animal meat),
Q2. Scent
• probably depended mainly on 2 …………………………………… when hunting (2nd paragraph line 6,7) During long-distance chases (=when hunting), thylacines were likely to have relied more on(= depended) scent than any other sense.
Q3. Pouch
• young spent first months of life inside its mother’s 3 ………………………………….. .
In paragraph 3 line 3 &4, Newborns crawled into the pouch on the belly of their mother, and attached themselves to one of the four teats, remaining there for up to three months.
Q4. fossil
last evidence in mainland Australia is a 3, 100-year-old 4 ………………………………….. .
The most recent, well-dated occurrence of a thylacine on the mainland is a carbon-dated fossil from Murray Cave in Western Australia, which is around 3, 100 years old.
Q5. habitat
• reduction in 5 …………………………………… and available sources of food were partly responsible for decline in Tasmania.
In paragraph 5. it is likely that various other factors also contributed to the decline and eventual extinction of the species. These include competition with wild dogs introduced by European settlers, loss of habitat(reduction in habitat) along with the disappearance of prey species(=reduction in .. and available sources of food)
Q6 (True) Significant numbers of thylacines were killed by humans from the 1830s onwards.
In paragraph 5, which began in the 1830s and continued for a century, is generally attributed to the relentless efforts of sheep farmers and bounty hunters** with shotguns.
Q 7(False) Several thylacines were born in zoos during the late 1800s.
In paragraph 6th first 2 lines, There was only one successful attempt to breed a thylacine in captivity(=zoo), at Melbourne Zoo in 1899. This was despite the large numbers that went through some zoos
Q8 (Not Given) John Gould’s prediction about the thylacine surprised some biologists.
In paragraph 6, line 3 to last, The famous naturalist John Gould foresaw(=prediction) the thylacine’s demise when he published his Mammals of Australia between 1848 and 1863, writing, ‘The numbers of this singular animal will speedily diminish, extermination will have its full sway, and it will then, like the wolf of England and Scotland, be recorded as an animal of the past.’ NO information about to feel surprise.
Q9 (False)In the early 1900s, many scientists became worried about the possible extinction of the thylacine.
In 7th paragraph first 2 lines, However, there seems to have been little public pressure to preserve the thylacine, nor was much concern expressed by scientists at the decline(extinction) of this species in the decades that followed.
Q10 (Not Given) T. T. Flynn’s proposal to rehome(find new home) captive(in case) thylacines on an island proved to be impractical.
In 7th paragraph, line no 3 and 4, notable exception was T.T. Flynn, Professor of Biology at the University of Tasmania. In 1914, he was sufficiently concerned about the scarcity of the thylacine to suggest that some should be captured and placed on a small island(rehome). But there is no information about “proved to be impractical or not”
Q11(False) There were still reasonable numbers of thylacines in existence when a piece of legislation protecting the species during their breeding season was passed.
In 7th paragraph line 4,5 & 6, But it was not until 1929, with the species on the very edge(small/minor) of extinction, that Tasmania’s Animals and Birds Protection Board passed a motion protecting thylacines only for the month of December, which was thought to be their prime breeding season
Q12 (True) From 1930 to 1936, the only known living thylacines were all in captivity.
In 7th paragraph ,line 8th, The last known wild thylacine to be killed was shot by a farmer in the north-east of Tasmania in 1930, leaving just captive specimens. Official protection of the species by the Tasmanian government was introduced in July 1936
Q13 (Not Given) Attempts to find living thylacines are now rarely made.
In 8th paragraph, There have been numerous expeditions and searches for the thylacine over the years, none of which has produced definitive evidence that thylacines still exist. The species was declared extinct by the Tasmanian government in 1986.
No information wheather these Attempts are now made or not.
READING PASSAGE 2 Palm oil
Q14. examples of a range of potential environmental advantages of oil palm tree cultivation
In paragraph F, 1st paragragh deforestation argument isn’t as straightforward as it seems. Oil palm plantations produce at least four(4 times increase) and potentially up to ten times more(10 times increase) oil per hectare than soybean, rapeseed, sunflower or other competing oils. (BY this environmental benefit). Deforestation is reduced.
In 2nd paragragh, palm tree captures more amount of carbon thus reduce the climate change.
Q15 description of an organisation which controls the environmental impact of palm oil production
In G, 1st line, the Roundtable on Sustainable Palm Oil (RSPO),
5th line The RSPO insists upon(controls) no virgin forest clearing, transparency and regular assessment of carbon stocks, among other criteria(environmental impact).
Q16 examples of the widespread global use of palm oil
In paragragh A, Palm oil is an edible oil derived from the fruit of the African oil palm tree, and is currently the most consumed vegetable oil in the world. It’s almost certainly in the soap we wash with in the morning, the sandwich we have for lunch, and the biscuits we snack
Q17 reference to a particular species which could benefit the ecosystem of oil palm plantations
In pararagh H, New research at Ellwood’s lab hints at one plant which might make all the difference. The bird’s nest fern (Asplenium nidus)(particular species) grows..
Last four line.. reintroducing the bird’s nest fern into oil palm plantations could potentially allow these areas to recover their biodiversity, providing a home for all manner of species, from fungi and bacteria, to invertebrates such as insects, amphibians, reptiles and even mammals
Q18 figures illustrating the rapid expansion of the palm oil industry
In B, last 3 lines, From a mere two million tonnes of palm oil being produced annually globally 50 years ago, there are now around 60 million tonnes produced every single year, a figure looking likely to double or even triple by the middle of the century.
Writer says, 2 million to 60 million production increased.
Q19 an economic justification for not opposing the palm oil industry
In paragragh E first 2 lines, One response to the boycott movement(an economic justification) has been the argument for the vital role palm oil plays in lifting many millions of people in the developing world out of poverty
Q20 examples of creatures badly affected by the establishment of oil palm plantations
In paragragh C, Endangered species – most famously the Sumatran orangutan, but also rhinos, elephants, tigers, and numerous other fauna – have suffered from the unstoppable spread of oil palm plantations.
Q 21 & 22 Which TWO statements are made about the Roundtable on Sustainable Palm Oil (RSPO)?
A Its membership has grown steadily over the course of the last decade.
In G paragragh, Over the past decade or so, an agreement has gradually been reached regarding standards that producers of palm oil have to meet in order for their product to be regarded as officially ‘sustainable’
Here discussed about an argument no membership mention so A incorrect.
B It demands that certified producers be open and honest about their practices.
The RSPO insists upon(producer should regularly doing carbon stocks and not cutting trees) no virgin forest clearing, transparency and regular assessment of carbon stocks, among other criteria.
So, B correct
C It took several years to establish its set of criteria for sustainable palm oil certification.
In G, Over the past decade or so, an agreement has gradually been reached regarding standards that producers of palm oil have to meet in order for their product to be regarded as officially ‘sustainable. So C correct.
D Its regulations regarding sustainability are stricter than those governing other industries.
E It was formed at the request of environmentalists concerned about the loss of virgin forests.
NO information given for regarding any regulations sustanibality(D) or the request of environment(E)
Ans. B,C
Q 23 solid
One advantage of palm oil for manufacturers is that it stays …………………………………… even when not refrigerated. IN paragragh A, line 4&5,the writer says that it remain solid even at room temperature(not refrigerated).
Q 24 Sumatran orangutan
The …………………………………… is the best known of the animals suffering habitat loss as a result of the spread of oil palm plantations.
In paragragh C, all as a direct result of land clearing to establish oil palm tree monoculture on an industrial scale, particularly in Malaysia and Indonesia. Endangered species – most famously(best known) the Sumatran orangutan
Q25 carbon stocks
As one of its criteria for the certification of sustainable palm oil, the RSPO insists that growers check …………………………………… on a routine basis.
In paragragh G line 5th & 6th , The RSPO insists upon no virgin forest clearing, transparency and regular assessment(check) of carbon stocks, among other criteria.
Q26 biodiversity
Ellwood and his researchers are looking into whether the bird’s nest fern could restore …………………………………… in areas where oil palm trees are grown.
READING PASSAGE 3: Building the Skyline: The Birth and Growth of Manhattan’s Skyscrapers
In paragragh H line 7th & 6th , Ellwood believes that reintroducing the bird’s nest fern into oil palm plantations could potentially allow these areas to recover their biodiversity.
Q27 What point does Shester make about Barr’s book in the first paragraph?
A It gives a highly original explanation for urban development.
In paragragh 1st line 6,7, is a compilation of chapters commenting(not explain) on different aspects of NewYork’s urban development. So A incorrect.
B Elements of Barr’s research papers are incorporated throughout the book.
In paragragh 1st last 2 lines, as the latter chapters incorporate aspects of Barr’s related research papers. That is writer not incorporate throughout the paper only corporate last chapters.
as the latter chapters incorporate aspects of Barr’s related research papers.
C Other books that are available on the subject have taken a different approach.
No information in 1st paragragh about other books
D It covers a range of factors that affected the development of New York.
In line 2 writer mention, The book combines(Covers) geology, history, economics, and a lot of data= a range of factors.
So D correct
Q28 How does Shester respond to the information in the book about tenements?
A She describes the reasons for Barr’s interest.
In 3rd paragragh no reasons for Barr’s interest so A incorrect.
B She indicates a potential problem with Barr’s analysis.
Potential Problem: Line 6&7, the writer says, , no skyscraper interested in performing “slum clearance’” which is the main problem
Bar’s analysis in last lines 4, no skyscraper developer was interested in performing the necessary “slum clearance’ is a problem . …. while more expensive foundations would not.
So, B correct ans.
C She compares Barr’s conclusion with that of other writers.
NO information about Barr’s conclusion, So, C incorrect.
D She provides details about the sources Barr used for his research.
NO information about details sources of his research. So, D incorrect
Q29 What does Shester say about chapter six of the book?
A It contains conflicting data(6th line= Chapter six then presents data on building height throughout the 20th century).
In 4th lines says, Chapter six present data on building height, but there is no information about conflicting data, SO A incorrect.
B It focuses too much on possible trends.
No information about focuses too much on possible trends so B incorrect.
C It is too specialised for most readers(=it is probably more technical(too specialised) than would be preferred by a general audience(readers).).
So, C correct ans.
D It draws on research that is out of date(While less technical(in passage too specialized/new) than the research paper on which the chapter(six) is based).
So, D incorrect.
Q30 What does Shester suggest about the chapters focusing on the 1920s building boom?
A The information should have been organised differently.
In 8th paragragh no information about organizing of information is mentiontioned, therefore option A is incorrent
B More facts are needed about the way construction was financed(= 2nd last line writer says “”finds that supply and demand factors(financing) explain much of the development(construction)”.) that mean much factors explained about the construction so shester doesn’t need to suggest any more facts. SO incorrect
C The explanation that is given for the building boom is unlikely(=last 3rd line, writer mention, He uses data to assess the viability of these two explanations). That means explanations given for building boom is not unlikely cause data use to explain the given information.
SO C incorrect.
D Some parts will have limited appeal to certain people.
In paragragh 8, first 2 & 3 lines,” Chapter eight contains(some parts) lengthy discussions of urban economic theory that may serve as a distraction(limited appeal) to readers primarily interested(limited peaple).” it means that some parts of the book has lengthy discussions due to which it might not be appealing to certain people, therefore D is correct answer.
Q31 What impresses Shester the most about the chapter on land values?
A) the broad time period that is covered (Last paragragh 2nd line= In the final chapter (chapter 10), Barr discusses another of his empirical papers that estimates Manhattan land values from the mid-19th century to the present day.) here a broad time period on land values mentioned but no information about impress shester or not. So A incorrect.
B the interesting questions that Barr asks (=4th line “Barr assesses (Q)’whether skyscrapers are a cause or an effect of high land values” ) but no information either interesting questions or not.
C the nature of the research into the topic(= 2nd & 3rd lines, ” The data work that went into these estimations is particularly impressive”)
data work=topic(land values)
went into estimations=research
it means that the nature of research on data work impresses Shester the most, so C correct
D the recommendations Barr makes for the future (In 4th & 5th lines, it is said that “He (Bar) finds(finding) that changes in land values predict future building height”, but there is no information whether Shester was impressed with it or not. Therefore D incorrect.
Q32 ( NO ) The description in the first chapter of how New York probably looked from the air in the early 1600s lacks interest.
In 2nd paragragh first two lines,” The description in the first chapter”=Barr begins chapter one ; “how New York probably looked from the air”= might have looked from the sky; “the early 1600s lacks interest”=fascinating account of how the New York landscape in 1609;
From these lines it clear New York look interesting(fascinating).
Q33 (YES) Chapters two and three prepare the reader well for material yet to come.
In the 3rd paragragh;” Chapters two and three take the reader up to the Civil War (1861- 1865), with chapter two focusing on the early development of land and the implementation of a grid system in 1811. Chapter three focuses on land use before the Civil War. Both chapters are informative and well researched and set the stage for the economic analysis that comes later in the book.”
It is clear that, Both chapters(two & three) set the stage(prepare the reader) for the economic analysis(materials) that comes later in the book(yet to come). It means the information in both chapters prepare the reader for more materials that comes later in the book.
Q34 (Not Given)The biggest problem for many nineteenth-century New York immigrant neighbourhoods was a lack of amenities.
In the 4th paragragh, No problem is mentioned for 19th century immigrant neighbourhoods.
Q
35(NO) In the nineteenth century, New York’s immigrant neighbourhoods tended to concentrate around the harbour.
In the 4th paragraph,” In the nineteenth century, New York’s immigrant neighbourhoods” = the location of neighborhoods and tenements in the late 19th century.” concentrate around the harbour.” = Most of these enclaves were located on the least valuable land, between the industries located on the waterfront and the wealthy neighborhoods bordering Central Park.
in last 3 lines, it is mentioned that New York’s immigrant were located on least valuable land, between the industries and wealthy neighborhoods (not around the harbour)
Q 36 H
In chapter seven, Barr indicates how the lack(absence) of bedrock close to the surface(=Chapter seven tackles the ‘bedrock myth’, the assumption that the absence of bedrock close to the surface between Downtown and Midtown New York ) does not explain why skyscrapers are absent from(= for skyscrapers not being built between the two urban centers.) 36 …………………………………… .
In 7th paragraph first 3 line, the lack(absence) of bedrock close to the surface not explain why skyscrapers are absent(not being built) from(between the two urban centers(two specific areas(downtown & Midtown New York)) ).
Q 37 D
He points out that although the cost of foundations increases when bedrock is deep below the surface(7th paragraph line 3 &4 = Barr argues that while deeper bedrock does increase foundation costs, these costs were neither prohibitively high), this cannot be regarded as 37 ……………………………………
in 7th paragraph 3rd & 4th paragraph, the writer says, that while deeper bedrock does increase foundation cost, hese cost were not prohibitively high.
Prohibitively high cost means although deeper bedrock increases the foundation costs, these costs cannt be consided as extra costs.
Q38 I
,especially when compared to 38 . ………………………………….. .
In 7th paragraph 4th & 5th lines, the writer says that “nor were they large compared to the overall cost of building a skyscraper(total expenditure).
Q39 B
A particularly enjoyable part of the chapter was Barr’s account of how foundations(7th paragraph 5th & 6th lines = What I enjoyed the most about this chapter was Barr’s discussion of how foundations are actually built.) are built. He describes not only how 39 …………………………………… are made possible by the use of caissons(7th line=What I enjoyed the most about this chapter was Barr’s discussion of how foundations are actually built.),
In 6th & 7th lines, the writer says that “he describes the use of caissons, which enable workers to dig down for considerable distances
dig down= deep excavations.
Q40 F
but he also discusses their 40 …………………………………….( 7th paragraph last 2 lines, technological history discusses not only how caissons work, but also the dangers involved(associated risks)). The chapter is well researched but relatively easy to understand.
Q1 (False) (Many Madagascan forests are being destroyed by attacks from insects.)
Madagascar’s forests are being converted to agricultural land at a rate of one percent every year. Much of this destruction is fuelled by the cultivation of the country’s main staple crop: rice. And a key reason for this destruction is that insect pests are destroying vast quantities of what is grown by local subsistence farmers, leading them to clear forest to create new paddy fields.
This means destruction occurred by farmers not insects.
Q2 (False) Loss of habitat has badly affected insectivorous bats in Madagascar.
In paragraph 1 the last few lines, the result is devastating habitat and biodiversity loss on the island, but not all species are suffering. In fact, some of the island’s insectivorous bats are currently thriving and this has important implications for farmers and conservationists alike.
Thrive= prosper, heighten, gain, flourish, improve
Q3 NOT GIVEN (Ricardo Rocha has carried out studies of bats in different parts of the world)
In paragraph 2 the last few lines, Rocha’s new study shows that several species of bats are giving Madagascar’s rice farmers a vital pest control service by feasting on plagues of insects.
Nothing about mention Rocha’s worldwide studies.
Q 4 (TRUE) Habitat modification has resulted in indigenous bats in Madagascar becoming useful to farmers.
In paragraph 3, Bats comprise roughly one-fifth of all mammal species in Madagascar and thirty-six recorded bat species are native to the island, making it one of the most important regions for conservation of this animal group anywhere in the world.
In paragraph 4, Co-leading an international team of scientists, Rocha found that several species of indigenousbats are taking advantage of habitat modification to hunt insects swarming above the country’s rice fields. They include the Malagasy mouse-eared bat, Major’s long-fingered bat, the Malagasy white-bellied free-tailed bat and Peters’ wrinkle-lipped bat.
Q5 NOT GIVEN
The Malagasy mouse-eared bat is more common than other indigenous bat species in Madagascar.
In paragraph 4 last few lines,. They include the Malagasy mouse-eared bat, Major’s long-fingered bat, the Malagasy white-bellied free-tailed bat and Peters’ wrinkle-lipped bat.
Here is no compare in passage.
Q6 (TRUE)Bats may feed on paddy swarming caterpillars and grass webworms.
In paragraph 4, We found that six species of bat are preying on rice pests, including the paddy swarming caterpillar and grass webworm.
Q7 droppings
In paragraph 7 the last line, They next used DNA barcoding techniques to analyse droppings collected from bats at the different sites.
Q8 coffee
In paragraph 8 the last few lines, the bats were consuming pests of other crops, including the black twig borer (which infests coffee plants), the sugarcane cicada, the macadamia nut-borer, and the sober tabby (a pest of citrus fruit)
Consuming = use, eat
Q9. mosquitoes
In paragraph 10 the last few lines, Rocha and his team found evidence that Malagasy bats feed not just on crop pests but also on mosquitoes – carriers of malaria, Rift Valley fever virus and elephantiasis – as well as blackflies, which spread river blindness.
Use for explanation.
Q10. protein
In paragraph 11 the first few lines Rocha points out that the relationship is complicated. When food is scarce, bats become a crucial source of protein for local people.
Q11. unclean
Same In paragraph 11 “And as well as roosting in trees, the bats sometimes roost in buildings, but are not welcomed there because they make them unclean.
Q12 culture
Same In paragraph 11 ,At the same time, however, they are associated with sacred caves and the ancestors, so they can be viewed as beings between worlds, which makes them very significant in the culture of the people.
Q13 houses
Same In paragraph 11 last few lines. Rocha says, ‘With the right help, we hope that farmers can promote this mutually beneficial relationship by installing bat houses.’
READING PASSAGE 2 Does education fuel economic growth?
Q14 an explanation of the need for research to focus on individuals with a fairly consistent income
From paragraph E line 2 to 5, the writer has explained the need for research to look at individuals consistant income.“an explanation of the need for research” = it is time ‘to ask the (big questions=to find out)’. “focus on individuals with a fairly consistent income = This involves following the lives of different people with the same level of wealth over a period of time. If wealth is constant(consistent income), it is possible to discover(to focus) whether education was, for example, linked to the cultivation of new crops, or to the adoption of industrial innovations like sewing machines. research
Q15 examples of the sources the database has been compiled from
From paragraph A, line 3 to 6, “database has been compiled from ”=a huge database about the lives of southwest German villagers between 1600 and 1900 has been compiled by a team led by Professor Sheilagh Ogilvie.” examples of the sources”= It includes court records, guild ledgers, parish registers, village censuses, tax lists and – the most recent addition – 9,000 handwritten inventories listing over a million personal possessions belonging to ordinary women and men across three centuries.
Q16 an account of one individual’s refusal to obey an order
From paragraph D, line 3 to 6, “an account of one individual’s”=The database also reveals the case of Juliana Schweickherdt, a 50-year-old spinster living in the small Black Forest community of Wildberg, “refusal to obey an order”=reprimanded(disaaproved) in 1752 by the local weavers’ guild for ‘weaving cloth and combing wool, counter to the guild ordinance(community regulations)’. When Juliana continued taking jobs reserved for male guild
Q17 a reference to a region being particularly suited to research into the link between education and economic growth
In paragraph F, “a reference to a region”= German-speaking central Europe, “particularly suited to research into”= German-speaking central Europe, “the relationship(=link) between education and economic growth is far from straightforward(=not easy to understand)”=link between education and economic growth
Q18 examples of the items included in a list of personal possessions
In paragraph c line 2 to 6, “list of personal possessions”=belongings of women and men at marriage, remarriage and death. “examples of the items”= From badger skins to Bibles, sewing machines to scarlet bodices – the villagers’ entire worldly goods are included. Inventories of agricultural equipment and craft tools reveal economic activities; ownership of books and educationrelated objects like pens and slates suggests how people learned.
Q 19 descendants
Paragraph D, “The database that Ogilvie and her team has compiled”=Ogilvie and her team have been building the vast database,” The database that Ogilvie and her team has compiled”= full demographic reconstruction of the people who lived in these two German communities.” as well as those of their 19 …………………………………… ,over a 300-year period”= and their descendants(heir) – across 300 years
Q20 sermon
Paragraph D, Ana Regina and Magdalena Riethmullerin were reprimanded(chastise) while they should have been paying attention to(listening)= Ana Regina and Magdalena Riethmiillerin, who were chastised in 1707 for reading books in church instead of listening to the sermon.”
Q21 fine
Paragraph D, There was also Juliana Schweickherdt, who came to the notice of the weavers’ guild in the year 1752 for breaking guild rules.”= reprimanded in 1752 by the local weavers’ guild for ‘weaving cloth and combing wool, counter to the guild ordinance.
“As a punishment, she was later given a”= she was summoned before the guild court and told (to pay a fine=as a punishment).
Q22 skills
Paragraph D, “Cases like this illustrate how the guilds could prevent”= The dominance of guilds, (held back=prevent) even the simplest industrial innovation, “stop skilled people from working”= prevented people from using their skills.
Q23 Which TWO of the following statements does the writer make about literacy rates in Section B?
Very little research has been done into the link between high literacy rates and improved earnings(=line 3 & 4,But, if you look back through history, there’s no evidence that having a high literacy rate made a country industrialise earlier). So A incorrect
Literacy ratesin Germany between 1600 and 1900 were very good.(=line 3 Between 1600 and 1900, line 6.During this period, Germany and Scandinavia had excellent literacy rates) So B correct
There is strong evidence that high literacy rates in the modern world result in economic growth. (= ‘Modern cross-country analyses have also struggled to find evidence that education causes economic growth, even though there is plenty of evidence that growth increases education). So C incorrect
England is a good example of how high literacy rates helped a country industrialise.(line 4 to 6= Between 1600 and 1900, England had only mediocre(very Low) literacy rates by European standards, yet its economy grew fast and it was the first country to industrialise) So D incorrect
Economic growth can help to improve literacy rates.(Passage last line= even though there is plenty of evidence that growth increases education) So E correct
Ans 23 & 24: B,E.
Q 25 Which TWO of the following statements does the writer make in Section F about guilds in German-speaking Central Europe between 1600 and 1900?
A They helped young people to learn a skill (line 3 & 4 No information). So A incorrect
B They were opposed to people moving to an area for work(last 2 line =In villages throughout the region, guilds blocked labour migration.). So B correct
C They kept better records than guilds in other parts of the world(in line 6,local guilds and merchant associations were extremely powerful but no but there no information either they kept better records than others). So C incorrect
D They opposed practices that threatened their control over a trade(line 6&7= local guilds and merchant associations were extremely powerful and legislated against(=opposed practices) anything that undermined their monopolies). So D correct
E They predominantly consisted of wealthy merchants(No information wheather merchants wealthy or not). So E incorrect
Ans 25, 26= B,D
READING PASSAGE 3: Timur Gareyev – blindfold chess champion
Q27 a reference to earlier examples of blindfold chess
In paragraph D,” earlier examples of blindfold chess”= blindfold chess seems to call for superhuman skill. But displays of the feat go back centuries. The first recorded game in Europe was played in 1Q3th-century Florence(1stearlier examples of blindfold chess). In 194 7, the Argentinian grandmaster Miguel Najdorf(C) played 45 simultaneous games in his mind.
Ans: D
Q28 an outline of what blindfold chess involves
In paragraph E line Q2 to 4, “what blindfold chess involves”=The nature of the game is to run through possible moves in the mind to see how they play out. From this, regular players develop a memory for the patterns the pieces make, the defences and attacks. That is writer mention this game involves in possible moves in mind, where player develop a pattern, defence, attack etc.
Ans. E
Q29 a claim that Gareyev’s skill is limited to chess
In paragraph F, “Gareyev’s skill is limited to chess” =The scientists first had Gareyev perform some standard memory tests. These assessed his ability to hold numbers, pictures and words in mind. One classic test measures how many numbers a person can repeat, both forwards and backwards, soon after hearing them. Most people manage about seven. ‘He was not exceptional on any of these standard tests,’ said Rissman. ‘We didn’t find anything other than playing chess that he seems to be supremely gifted at.’
In lines Q2 to 4 of paragraph, writer says that gareyev performed some memory tests but we didn’t find anything else other than playing chess that he seems to be supremely gifted. It means that gareyebs skill is limited to chess only.
Ans: F
Q30 why Gareyev’s skill is of interest to scientists
In paragraph B,” Gareyev’s skill is of interest to scientists”= But Gareyev’s prowess has drawn interest from beyond the chess-playing community. In the hope of understanding how he and others like him can perform such mental feats, researchers at the University of California in Los Angeles (UCLA) called him in for tests. This means scientist wants to know how others like Gareyev’s can perform such game.Ans: H
Q31 an outline of Gareyev’s priorities
In paragraph H, “Gareyev’s priorities”=For the world record attempt, Gareyev hopes to play 47 blindfold games at once in about 16 hours(1stpriority). most important part of blindfold chess for me is that I have found the one thing that I can fully dedicate myself to. He will….the. most important part of blindfold chess for me is that I have found the one thing that I can fully dedicate myself to(Q2nd priority).Ans:B
Q32 a reason why the last part of a game may be difficult
In paragragh E list few lines, “last part of a game may be difficult”=But the ends of games are taxing(Too difficult) too, as exhaustion sets in. When Gareyev is tired, his recall can get patchy(irregular,inconsistant). He sometimes makes moves based on only a fragmented memory(irregularly sequence of memory) of the pieces’ positions. Ans: E
Q33(False) In the forthcoming games, all the participants will be blindfolded.
In paragraph A, “In the forthcoming games”= Next month, a chess player named Timur Gareyev will take on nearly 50 opponents. “all the participants will be blindfolded”= While his challengers will play the games as normal, Gareyev himself will be blindfolded. Its clear that except Gareyes, all are normal(notblindfolded).
Q34 (Not given) Gareyev has won competitions in BASE jumping.
In paragraph A line 6, “won competitions in BASE jumping” = he gets his kicks(enjoyment) from the adventure sport of BASE jumping. No information for competitions on BASE jumping.
Q35 (Not Given)UCLA is the first university to carry out research into blindfold chess players.
In paragraph B, UCLA is the first university, research into blindfold chess players = (line Q3&4) researchers at the University of California in Los Angeles (UCLA) called him in for tests. They now have their first results. There is no mention that UCLA is the first research to carry out that research.
Q36 (True)Good chess players are likely to be able to play blindfold chess.
In paragraph B “Good chess players”=(line 5 end) most accomplished(good) players,” likely to be able to play blindfold chess”= (line 4 & 5)’The ability to play a game of chess with your eyes closed is not a far reach( not a great thing) that means they able to play blindfold.
Q37 Memory
In paragraph F 1st line, “The researchers(Scientist) started by testing Gareyev’s Q37 …………………………………… ;” = The scientists first had Gareyev perform some standard memory tests.
Q38 Numbers
In paragraph F, Q2nd & Q3rd line “for example, he was required to recall a string of Q38 …………………………………… in order and also in reverse order.” = One classic test(Example) measures how many numbers a person can repeat, both forwards and backwards.
Q39 communication
Although his performance was normal, scans showed an unusual amount of Q39 …………………………………… within the areas of Gareyev’s brain that are concerned with = (in F, line 9 & 10) results are tentative and as yet unpublished, the scans found much greater than average(unusual amount) communication between parts of Gareyev’s brain that make up what is.
Q40 visual
In G paragraph, line Q3 &4, “In addition, the scans raised the possibility of unusual strength in the parts of his brain that deal with 40 …………………………………… input”= Initial results suggest that the areas of his brain that process visual images – such as chess boards – may have stronger links to other brain regions, and so be more powerful than normal(unusual strength).
1. ………………………. to direct the tunneling Answer: posts
– First paragraph, 3 line. “They introduced the qanat method of tunnel construction, which consisted of placing posts over a hill in a straight line, to ensure that the tunnel kept to its route.” The meaning of “to ensure that the tunnel kept to its route” is that tunnel should go into the right direction.
2. water runs into a …………………….. used by local people Answer: canal
– First paragraph, 7 line. “Once the tunnel was completed, it allowed water to ow from top of a hillside down towards a canal, which supplied water for human use.” Human use = local people.
3. vertical shafts to remove earth and for……………………….. Answer: ventilation
– First paragraph, 6 line. “The excavated soil was taken up to the surface using the shafts, which also provided ventilation.”
4. ………………………… made of wood or stone
Answer: lid
– Second paragraph, 3rd line. The shafts were equipped with handholds and footholds to help those climbing in and out of them and were covered with a wooden or stone lid.”
5. …………………… attached to plumb line Answer: weight
– Second paragraph, 5th line. “Romans hung a plumb line from a rod placed across the top of each shaft and made sure that the weight at the end of it hung in the centre of the shaft.”
6. handholds and footholds used for……………………. Answer: climbing
– Second paragraph, 3rd line. “The shafts were equipped with handholds and footholds to help those climbing in and out of them.”
Questions 7-10. TRUE/ FALSE/ NOT GIVEN
7. The counter-excavation method completely replaced the qanat method in the 6 century BCE. Answer: FALSE
– Third paragraph’s first 3 lines. “It was used to cut through high mountains when the qanat method was not practical alternative.” It means when qanat method was not useful, then counter-excavation method was used. So counter-excavation method did not completely replaced qanat method. So FALSE.
8. Only experienced builders were employed to construct a tunnel using the counter-excavation method. Answer: NOT GIVEN
– In third paragraph, from 3rd line to 5th line, they talk about knowledge, skill, and planning needed for counter excavation. But not anywhere they said only experienced were employed to construct tunnels using counter-excavation method. So NOT GIVEN.
9. The information about a problem that occurred during the construction of the Saldae aqueduct system was found in ancient book. Answer: False
– Third paragraph’s last four lines. In these lines, they said that inscription was written on the side of 428-meter tunnel that describes how two teams of builders missed each other in the mountain. The problem is written on side of the cave not in any ancient book. So FALSE. (Inscription + written or carved on something)
10. The mistake made by the builders of the Saldae aqueduct system was that the two parts of the tunnel failed to meet. Answer: True
– Third paragraph’s second-last line. “Teams of builders missed each other in the mountain and how the later construction of a lateral link between both corridors corrected the initial error.” Clearly given. So TRUE. (Lateral = from a side or sides)
Questions 11-13. Answer the questions below.
11. What type of mineral were the Dolaucothi mines in Wales built to extract? Answer: gold
– Fourth paragraph, 6th line. “Traces of such tunnels used to mine gold can still be found at Dolaucothi mines in Wales.”
12. In addition to the patron, whose name might be carved onto a tunnel? Answer: (the) architect(‘s) (name)
– In the last paragraph, 11th line. “Most tunnels had inscriptions showing the names of patrons who ordered construction and sometimes the name of the architect.”
13. What part of Seleuceia Pieria was the Cevlik tunnel built to protect? Answer: (the) harbour/ harbor
– In the Last paragraph, 13th line. “1.4- kilometer Cevlik tunnel in Turkey, built to divert the oodwater threatening the harbor of the ancient city of Seleuceia Pieria”
Reading Passage 2: Changes in Reading Habits, Solution with Answer Key
Questions 14-17. Choose the correct letter, A, B, C, D (Multiple Choice)
14. What is the writer’s main point in the first paragraph? Answer: A ( Our use of technology is having a hidden effect on us)
– First paragraph, lines 4 to 6. “The meaning of these lines is that neuronal circuit related to our reading ability is changing without everyone’s knowledge.” Unbeknown-without the knowledge of someone. Invisible is a synonym to hidden. Hence, there is a hidden effect.
15. What main point does Sherry Turkle make about innovation? Answer: B ( We should pay attention to what might be lost when innovation occurs)
– Third paragraph, line 2 to 5. “We do not err as a society when we innovate but when we ignore what we disrupt or diminish while innovating.” In these lines, the writer said that we make an err (mistake) when we do not pay attention to what we disrupt or diminish (make or become less) while innovating.
16. What point is the writer making in the fourth paragraph? Answer: D (Some brain circuits adjust to whatever is required of them)
– Fourth paragraph, line 2 to 6. “It will adapt to that environment’s requirements” This paragraph is about reading circuit of the brain, and the writer explained that reading circuit changes according to the requirement. (Adapt- adjust modify)
17. According to Mark Edmundson, the attitude of college students Answer: B (has influenced what they select to read)
– In Fifth paragraph, line 3 to 5. “In these lines, Mark Edmundson said the students have attitude of no patience to read longer, denser, and more difficult text so they avoid (not select) classic literature of 19 and 20 century.”
Questions 18-22. Complete the summary using the list of words.
Studies on digital screen use
18. showing some……………. trends. Answer: D – worrying.
-In Sixth paragraph’s First two lines. Keyword -> Troubling = Worrying.
19. technique to find out how ………………….. each group’s understanding Answer: H – thorough.
– In 6 paragraph, line 6 and 7. “Result indicated that who read on print were superior in their comprehension” Keyword – superior in their comprehension = thorough in understanding.
20. finding the order of information …………………… to recall. Answer: F – hard.
– In 6 paragraph, line 6 to 8. “Result indicated that students who read on print were superior in their comprehension to screen-reading peers, particularly in their ability to sequence detail and reconstruct the plot in chronological order.” In these lines, the writer said students who read on print were good at understanding and they can better detail information in chronological (following the order of events in which they occurred) order. So it means screen reading peers were not good at such capabilities and it was hard for them to recall order of information.
21. tending to read ………………….. words and phrases in a text to save time. Answer: B – isolated.
– In 7 paragraph line 3 to 4. “ Many readers now use a pattern when reading in which they sample the first line and the word-spot through rest of the text. When the reading brain skims like this, it reduces time allocated to deep reading processes.” Word-spotting = isolated words.
22. superficial understanding of the ……………………… content of material Answer: C – emotional.
— In 7 paragraph’s last 2 lines. “In other words, we don’t have time to grasp complexity, to understand another’s feelings.” Feelings = emotions.
Questions 23-26. YES/ NO/ NOT GIVEN.
23. The medium we use to read can affect our choice of reading content. Answer: Yes
– In Eighth paragraph, line 3 & 4. “It is about how all we have begun to read on various mediums and how that changes not only what we read, but also purposes for which we read.” What we read = choice of reading content. So the answer is YES.
24. Some age groups are more likely to lose the complex reading skills than others. Answer: No
– Eighth paragraph, line 4 & 5. “Nor is it only about the young. The subtle atrophy of critical analysis and empathy effects us all equally.” It effects us all equally, not some age groups. So the answer is NO. Atrophy = gradual decline in effectiveness or vigour.
25. False information has become more widespread in today’s digital era. Answer: Not Given
– In Eighth paragraph, line 5 to 8. In these lines, the writer said that due to a lot of information, we go to familiar (known) information which is unchecked and receive and require no analysis. It makes likely to influence by false information. But nowhere the writer talk about false information has become widespread. So the answer is NOT GIVEN.
26. We still have opportunities to rectify the problems that technology is presenting. Answer: YES
– In Last paragraph’s line 3 & 4. “We possess both the science and the technology to identify and redress the changes how we read before they become entrenched.” It means we have science and technology to nd and rectify (solve/ redress) problems that technology is presenting before they get permanent. Entrenched = firmly established.
Reading Passage 3: Attitudes Towards Artificial Intelligence, Solution with Answer Key
Questions 27-32. Choose the correct heading for each section from the list of headings.
27. Section A Answer: iii – The superiority of AI projections over those made by humans.
— Section A’s full first part and the second part’s first line. A section’s first part tells about elds in which AI is used to predict future. In the A section’s second part’s first line, it is clearly said that AI is almost always better at forecasting (predict/projection) than we are. So the answer is iii.
28. Section B Answer: vi – Widespread distrust of an AI innovation.
— In the B section’s first part, from line 6 to 9, and line 1 & 2 of the second part of B section. Watson is a supercomputer used for Oncology. If Watson gives opinion about treatment that doctors already know, then doctors do not see it with much value. If Watson recommends something opposite of expert’s opinion, doctors think Watson is not smart enough. It means they do not want to trust Watson in any way. So the answer is vi.
29. Section C Answer: ii – Reasons why we have more faith in human judgement than in AI.
— In Section C, from line 1 to 5. In these lines, the writer explained that we trust in human more because we understand how others think and our trust on them was right so we feel safe. But we do not know much about AI, so we do not faith them. Thus, the answer is ii.
30. Section D Answer: i – An increasing divergence of attitudes towards AI.
— Section D’s 2 part’s 3 & 4 line. “ As AI is represented more and more in media and entertainment, it could lead to society split between those who benefit and those who reject it.” Divergence (split) = Difference in opinions.
31. Section E Answer: vii – Encouraging openness about how AI functions.
— In section E’s full second part. The first line of this part said showing more about how algorithms work and for what they work will improve the trust in AI. So answer is vii.
32. Section F Answer: v – The advantages of involving users in AI processes.
— In first line of F section. “Allowing people’s control over AI decision-making could also improve trust”. Advantage-> improve people’s trust.
Question 33-35. Choose the correct letter, A, B, C or D. (Multiple Choice)
33. What is the writer doing in Section A? Answer: C – highlighting the existence of a problem.
— Section A’s second part’s line 2 & 3. The problem is the lack of confidence in AI predictions. So the answer is C.
34. According to Section C, why might some people be reluctant to accept AI? Answer: B – its complexity makes them feel they are at a disadvantage.
— Section C’s first part’s last three lines. A sense of losing control is the disadvantage that the writer talked about. Complexity-> difficult to comprehend. Comprehend = understand.
35. What does the writer say about the media in Section C of the text? Answer: A – It leads the public to be mistrustful of AI.
— Section C’s second part’s lines 3 to 5. “Embarrassing AI failures receive a disproportionate amount of media attention, emphasizing the massage that we cannot rely on technology.” Clearly give.
Questions 36-40. YES/ NO/ NOT GIVEN
36. Subjective depictions of AI in sci- films make people change their opinion about automation. Answer: NO
– In section D’s first part’s lines 3 to 7. “In the last line of this part, it is said that optimists became more extreme in their enthusiasm for AI and skeptics became even more guarded.” It means people who favour AI start favoring more while who doubt AI became stronger in their opinion after watching AI film. So the answer is NO.
37. Portrayals of AI in media and entertainment are likely to become more positive. Answer: NOT GIVEN
– There is discussion related to media and entertainment in D section but nothing is discussed whether the media will portray AI positively or not.
38. Rejection of the possibilities of AI may have a negative effect on many people’s lives. Answer: YES
– Section D’s second part’s last 2 lines. “Refusing to accept the advantages offered by AI could place a large group of people at a serious disadvantage.” Clearly given. So, the answer is YES.
39. Familiarity with AI has very little impact on people’s attitude to the technology. Answer: NO
– In section E’s first part’s lines 2 to 4. “In these lines, the writer said that having previous experience with AI can significantly improve people’s opinion about technology.” The given lines contradict with the question. So the answer is NO.
40. AI applications which users are able to modify are more likely to gain consumer approval. Answer: YES
– In section F’s first part’s lines 3 & 4. “When people were allowed the freedom to slightly modify an algorithm, they felt more satisfied with its decision”. So the answer is YES.
Reading Passage 1: Roman Shipbuilding and Navigation, Solution with Answer Key
, Reading Passage 1: Roman Shipbuilding and Navigation
IELTS Cambridge 16, Test 3, Academic Reading Module
Cambridge IELTS 16, Test 3: Reading Passage 1 – Roman Shipbuilding and Navigationwith Answer Key. Here we will discuss pros and cons of all the questions of the passage with step by step Solution included Tips and Strategies.
Questions 1-5. Do the following statements agree with the information given in Reading Passage 1?
(TRUE / FALSE / NOT GIVEN)
1. The Romans’ shipbuilding skills were passed on to the Greeks and the Egyptians. Answer: FALSE
– First paragraph, third line. “The Romans were not traditionally sailors but mostly land-based people, who learned to build ships from the people that they conquered, namely the Greeks and the Egyptians.” Here, the writer said that the Romans learned to build ships from the Greeks and the Egyptians. The question statement contradicts the information given in the passage. Hence, the answer is FALSE.
2. Skilled craftsmen were needed for the mortise and tenon method of fixing planks. Answer: NOT GIVEN
– There is no such information given in the passage. Some information is given in the second paragraph related to fixing mortise and tenon, in fifth line. However, there is no information on whether skilled craftsmen were needed for this work or not. So, NOT GIVEN.
3. The later practice used by Mediterranean shipbuilders involved building the hull before the frame. Answer: FALSE
– Second paragraph, seventh line. “Mediterranean shipbuilders shifted to another shipbuilding method, still in use today, which consisted of building the frame first and then proceeding with the hull ….” Here, the writer said that Mediterranean shipbuilders build the frame first and then the hull. The question statement contradicts the information given in the passage. Hence, the answer is FALSE.
4. The Romans called the Mediterranean Sea Mare Nostrum because they dominated its use.
Answer: TRUE
– Third paragraph, second-last line. Eventually, Rome s navy became the largest and most powerful in the Mediterranean, and the Romans had control over what they therefore called Mare Nostrum meaning ‘our sea’.” Here, ‘dominated‘ means ‘had control’. Hence, the answer is TRUE.
5. Most rowers on ships were people from the Roman army. Answer: TRUE
– Fourth paragraph, fourth line from end. “It is worth noting that contrary to popular perception, rowers were not slaves but mostly Roman citizens enrolled in the military.” Here, the writer said that rowers were Roman people who were in the military (army). The question statement matches the information given in the passage. Hence, the answer is TRUE.
Questions 6-13. Complete the summary below.
Warships and merchant ships
6. Warships were designed so that they were ………. and moved quickly. Answer: Lightweight
– Third paragraph, first line. “Warships were built to be lightweight and very speedy.” ‘Speedy’ means warships can ‘move quickly’. ‘Designed’ is similar to ‘built’. Hence, the answer is lightweight.
7. A battering ram made of ………. was included in the design for attacking and damaging the timber and oars of enemy ships. Answer: Bronze
– Third paragraph, fourth line. “They had a bronze battering ram, which was used to pierce the timber hulls or break the oars of enemy vessels.” Here, bronze battering ram means that battering ram is made of bronze.
8. Warships, such as the ‘trireme’, had rowers on three different ………. . Answer: Levels
– Fourth paragraph, first line. “The ‘trireme’ was the dominant warship from the 7 to 4 century BCE. It had rowers in the top, middle and lower levels,…” Here, it is given that trireme is a warship, and it had rowers on three (top, middle and lower) different levels.
9. Unlike warships, merchant ships had a broad ………. that lay far below the surface of the sea. Answer: Hull
– Fifth paragraph, second line. “They had a wider hull, …… Unlike warships, their V-shaped hull was deep underwater, …..” Here, ‘they’ referred to ‘merchant ships’ (read the first line of this paragraph). ‘Wider’ is a synonym for ‘broad’. ‘Deep’ gives a hint that it is ‘far’. ‘Underwater’ means it is ‘below the surface of the sea’. Hence, the answer is hull.
10. They had both square and ………. sails. Answer: Triangular
– Fifth paragraph, fifth line. “They had from one to three masts with large square sails and a small triangular sail at the bow.” Here, it is clear that the two shapes of sail are square and triangular. Hence, the answer is triangular.
11. On merchant ships and warships, ………. was used to ensure rowers moved their oars in and out of the water at the same time. Answer: Music
– Fifth paragraph, second-last line. “In order to assist them, music would be played on an instrument, and oars would then keep time with this.” Here, it is given that oars keep time (move in and out at the same time) with the music.
12. Quantities of agricultural goods such as ………. were transported by merchant ships to two main ports in Italy. Answer: Grain
– Sixth paragraph, first line. “The cargo on merchant ships included raw materials …… and agricultural products (e.g. grain from Egypt’s Nile valley).” Here, ‘goods’ are similar to ‘products’. Hence, the answer is grain.
13. The ships were pulled to the shore by ………. . Answer: Towboats
– Sixth paragraph, third-last line. “Large merchant ships would approach the destination port and just like today, be intercepted by a number of towboats that would drag them to the quay.” Here, ‘quay’ means ‘shore’. ‘Drag’ means ‘pull’. Hence, towboats are used to pull the ships to the shore.
Reading Passage 2: Climate Change Reveals Ancient Artefacts in Norway’s Glaciers, Solution with Answer Key
Climate Change Reveals Ancient Artefacts in Norway’s Glaciers
14. an explanation for weapons being left behind in the mountains Answer: D
– In D paragraph, third line. “Hunters would have easily misplaced arrows and they often discarded broken bows rather than take them all the way home.” So, hunters did not take weapons to their home and left them in the mountains.
15. a reference to the physical difficulties involved in an archaeological expedition Answer: C
– In C paragraph’s 2nd part’s first line. “The slow but steady movement of glaciers tends to destroy anything at their bases, so the team focused on stationary patches of ice, mostly above 1,400 metres. C paragraph’s 3 part’s first line. “Fieldwork is hard work- hiking with all our equipment, often camping on permafrost.” In the above-given lines, the writer talked about physical difficulties. Hence, these are the physical difficulties faced by archaeologists.
16. an explanation of why less food may have been available Answer: F
– In the F paragraph’s 2nd part’s last three lines. “A colder turn in the Scandinavian climate would likely have meant widespread crop failures, …” Hence, less food may have been available because of crop failure due to cold climate.
17. a reference to the possibility of future archaeological discoveries Answer: H
– In the H paragraph, second-last line. “That means archaeologists could be extracting some of those artefacts from retreating ice in years to come.” Here, the writer said that in the coming years, archaeologists could nd some artefacts.
18. examples of items that would have been traded Answer: G
– In the G paragraph, from fifth line. “And growing Norwegian …… would have created a booming demand for hides to fight o the cold, as well as antlers to make useful things like combs.” Here, the writer gives examples of two things that would have been traded. Hide = skin of an animal. Antler = horns of an adult deer.
19. a reference to the pressure archaeologists are under to work quickly Answer: B
– B paragraph’s 2nd part’s first 2 lines. “With climate change shrinking ice cover around the world, glacial archaeologists need to race the clock to nd newly revealed artefacts, preserve them and study them.” ‘Race the clock’ means they have to do ‘hurry’.
Questions 20-22. Complete the summary below.
Interesting finds at an archaeological site
20. They have little protection against ………. , which means that they decay relatively quickly. Answer: Microorganisms/ micro-organisms
– B paragraph, second line. “This is because unless they’re protected from the microorganisms that cause decay, they tend not to last long.” For more understanding, read the first line of this paragraph also. Hence, the answer is microorganisms.
21. In the past, there were trade routes through these mountains and ………. gathered there in the summer months Answer: Reindeer
– In C paragraph, fourth line. “Reindeer once congregated on these icy patches in the later summer months …….. In addition, trade routes threaded through the mountain passes ….” Congregated means gathered. Reindeer gathered on icy patches during the summer months. Hence, the answer is reindeer.
22. gathered there in the summer months to avoid being attacked by ………. on lower grounds
Answer: Insects
– In C paragraph, fourth line. “Reindeer once congregated on these icy patches in the later summer months to escape biting insects, ….” Here, the writer said reindeer gathered there to save themselves from insects. ‘Biting insects’ means ‘insects that bite’. ‘Escape’ means ‘to avoid’. Hence, the answer is insects.
Questions 23 and 24. Choose TWO letters, A–E. (Factor Matching)
Which TWO of the following statements does the writer make about the discoveries of Barrett’s team?
23. Answer: B
– Hunters went into the mountains even during periods of extreme cold. F paragraph, sixth line. “But it turned out that hunters kept regularly venturing into the mountains even when the climate turned cold, …” Hence, hunters regularly went to mountains during cold climate.
24. Answer: C
– The number of artefacts from certain time periods was relatively low. E paragraph, forth line. “They found that some periods had produced lots of artefacts, which indicates that people had been pretty active in the mountains during those times. But there were few or no signs of activity during other periods.” Here, the writer said that some periods had produced lots of artefacts which mean people were more active during those periods. However, there were some periods when people were less active means those periods had produced fewer artefacts.
Questions 25 and 26 Choose TWO letters, A–E. (Factor Matching)
Which TWO of the following statements does the writer make about the Viking Age?
25. Answer: A
– Hunters at this time benefitted from an increased demand for goods. G paragraph, fifth line. “And growing Norwegian towns, along with export markets, would have created a booming demand for hides to fight o the cold, as well as antlers to make useful things like combs. Business must have been good for hunters.” The writer said that the booming (increased) demand for goods necessarily (must) benefitted the hunters.
26. Answer: C
– Vikings did not rely on ships alone to transport goods. G paragraph, third line. “Although we usually think of ships when we think of Scadinavian expansion, these recent discoveries show that plenty of goods travelled on overland routes, ..” Here, the writer said that the latest discoveries show that a lot of goods were transported on overland (by land) routes. Hence, they did not rely only on ships.
Plant ‘Thermometer’ Triggers Springtime Growth by Measuring Night-time Heat
27. The Cambridge scientists’ discovery of the ‘thermometer molecule’ caused surprise among other scientists. Answer: NOT GIVEN
– There is no such information given in the passage. There is some information related to the discovery of the thermometer molecule by Cambridge scientists in paragraph A, but there is no such information whether it caused surprise among other scientists or not. Hence, the answer is NOT GIVEN.
28. The target for agricultural production by 2050 could be missed. Answer: TRUE
– D paragraph, fourth line. “It is estimated that agricultural yields will need to double by 2050, but climate change is a major threat to achieving this.” Here, it is given that the target for 2050 could not be achieved due to climate change. It means it could be missed. Hence, the answer is TRUE.
29. Wheat and rice suer from a rise in temperatures. Answer: TRUE
– D paragraph, fifth line. “Key crops such as wheat and rice are sensitive to high temperatures. Thermal stress reduces crop yields by around 10% of every one degree increase in temperature.” Sensitive means wheat and rice are affected by high temperatures. Hence, the answer is TRUE.
30. It may be possible to develop crops that require less water. Answer: NOT GIVEN
– There is no such information given in the passage. Hence, the answer is not given.
31. Plants grow faster in sunlight than in shade. Answer: FALSE
– In E paragraph, second line. “During the day, sunlight activates the molecules, slowing down growth. If a plant finds itself in shade, phytochromes are quickly inactivated – enabling it to grow faster to nd sunlight again.” Here, it is given that sunlight slows the growth of a plant, and in the shade, the plant grows faster to nd sunlight. The question statement contradicts the information given in the passage. Hence, the answer is FALSE.
32. Phytochromes change their state at the same speed day and night. Answer: FALSE
– In E paragraph’s 1st part’s second-last line. “’Light-driven changes to phytochrome activity occur very fast, in less than a second,’ says Wigge. At night, however, it’s a different story. Instead of a rapid deactivation following sundown, the molecules gradually change from their active to inactive state.” Here, the writer said that during the day, the state of phytochromes changes very fast. However, at night, it changes gradually (slowly). The question statement contradicts the information given in the passage. Hence, the answer is FALSE.
Questions 33-37. Which section contains the following information?
33. mention of specialists who can make use of the research findings Answer: H
– In H paragraph, seventh line. “’Cambridge is uniquely well-positioned………. Into the eld” In these lines they talk about outstanding collaborators (specialists) who work on more applied aspects of plant biology. Outstanding collaborators can help this new knowledge (research findings) into the elds. So “H” is the right answer.
34. a reference to a potential benefit of the research findings Answer: D
– In D paragraph, 8th line. “’Discovering the molecules that allow plants to sense temperature has the potential to accelerate the breeding of crops resilient to thermal stress and climate change.” Here, the writer said that molecules have the potential to speed up the breeding of crops. It is the potential (having the capacity to do something in the future) benet of the research.
35. scientific support for a traditional saying Answer: G
– In G paragraph, third line. “In fact, the discovery of the dual role of phytochromes provides the science behind a well-known rhyme long used to predict the coming season: oak before ash we’ll have a splash, ash before oak we’re in for a soak.” Here, ‘well-known’ means ‘famous’, and it is said that this rhyme was used earlier (means it is traditional) to predict the season. The writer said that certain discovery gives the science behind this rhyme. Hence, it provides scientific support to this traditional rhyme.
36. a reference to people traditionally making plans based on plant behavior Answer: C
– In C paragraph, first line. “Farmers and gardeners have known for hundreds of years how responsive plants are to temperature: warm winters cause many trees and flowers to bud early, something humans have long used to predict weather and harvest times for the coming year.” Here, the writer said that farmers and gardeners know about plants’ behavior to temperature, and they used this knowledge to predict weather and harvest times (plan).
37. a reference to where the research has been reported Answer: A
– In A paragraph’s 2nd part’s first line. “The new findings, published in the journal Science, show that phytochromes ….” Hence, the research (new findings) has been reported in the journal Science.
Questions 38-40. Complete the sentences below.
38. Daffodils are likely to flower early in response to ………. weather
Answer: Warm (winter)
– In G paragraph, first line. “Other species, such as daffodils, have considerable temperature sensitivity, and can flower months in advance during a warm winter.” Here, the writer said that daffodils flower early during a warm winter. Hence, the answer is warm (winter).
39. If ash trees come into leaf before oak trees, the weather in ………. will probably be wet. Answer: Summer
– In G paragraph, eighth line. “A warmer spring, and consequently a higher likeliness of a hot summer will result in oak leafing before ash. …….. a colder summer is likely to be a rain-soaked one.” The meaning of above lines is that warmer spring > hot summer > oak leafing before ash. The opposite of it: ash leafing before oak > colder spring > colder summer (rain-soaked). ‘Rain-Soaked’ means ‘wet’. Hence, the answer is summer.
40. The research was carried out using a particular species of ………. . Answer: Mustard plant(s) / mustard
– In H paragraph, second line. “The work was done in a model system, using a mustard plant called Arabidopsis, …” In the first line of this paragraph, the writer started discussing the research, and later in this line, it is said that the work was done using a mustard plant. Hence, the answer is mustard.
Cambridge IELTS 16, Test 2: Reading Passage 1 – The White Horse of Uffington with Answer Key. Here we will discuss pros and cons of all the questions of the passage with step by step Solution included Tips and Strategies.
Questions 1-8 Do the following statements agree with the information
1.Most geoglyphs in England are located in a particular area of the country. Answer: TRUE
– First paragraph, second line. “There are 56 hill figures scattered around England, with the vast majority on the chalk downlands of the country’s southern counties.” Here, the writer said that there are 56 hill figures in England, and the vast (great quantity) number of these are located at a particular place (southern counties). The question statement matches the information given in the passage.
Hence, the answer is TRUE. Geoglyphs = Hill figures.
2. There are more geoglyphs in the shape of a horse than any other creature. Answer: NOT GIVEN
– There is no such information given in the passage. There is some information about the shapes of the geoglyphs in the first paragraph’s third line (The figures include giants, horses…), but no such information is given whether more geoglyphs are in the shape of a horse or not. Hence, the answer is NOT GIVEN.
3. A recent dating of the Uffington White Horse indicates that people were mistaken about its age. Answer: TRUE
– Second paragraph, second line. “The White Horse has recently been re-dated and shown to be even older than its previously assigned ancient pre-Roman Iron Age date.” Here, re-dated means that it was dated again, and shown is a synonym to indicate. The writer said that redating the White horse shows it is older than its previously assigned age. It means people were mistaken about its age. Hence, the answer is TRUE.
4. Historians have come to an agreement about the origins of the Long Man of Wilmington
Answer: FALSE
– Second paragraph, third line. “More controversial is the date of the enigmatic Long Man of Wilmington is Sussex. While many historians are convinced the figure is prehistoric, others believe that it was the work of an artistic monk from a nearby priory and was created between the 11 and 15 centuries.” Agreement means they agree to the same thing. In the passage, it is given that historians have different viewpoints related to the origin of Long Man of Wilmington. Hence, they have different views, and the answer is FALSE.
5. Geoglyphs were created by people placing white chalk on the hillside. Answer: FALSE
– Third paragraph, first line. “The method of cutting these huge figures was simply to remove the overlying grass to reveal the gleaming white chalk below.” As per paragraph’s information, geoglyphs were created by removing grass to uncover already present chalk blow. But the question says that people were using chalk to make them. Thus, the answer is FALSE. Gleaming = of a smooth surface reflecting light.
6. Many geoglyphs in England are no longer visible. Answer: TRUE
– Third paragraph, fourth line to 6 line. “One reason that the vast majority of hill figures have disappeared is that……….” Here, the writer discussed the reason for disappearance of hill figures. Hence, the answer is TRUE. Disappearance = not visible.
7. The shape of some geoglyphs has been altered over time. Answer: TRUE
– In 3rd paragraph, 6th line. “Furthermore, Over hundreds of years the outline the outlines would sometimes change….” The writer said that “people not always cutting in exactly the same place, thus creating a different shape from the original geoglyph”. Hence, the answer is TRUE Altered = Changed
8. The fame of the Uffington White Horse is due to its size
Answer: NOT GIVEN
– Although the writer talked about Uffington White Horse in 4 paragraph, nothing is said about its fame. Hence, the answer is NOT GIVEN.
9. near an ancient road known as the ………. Answer: Ridgeway
– Fourth paragraph, third line. “The horse is situated 2.5 km from Uffington village on a steep slope close to the Late Bronze Age (c. 7 century BCE) hillfort of Uffington Castle and below the Ridgeway, a long-distance Neolithic track.” The track is similar to the road. Here, the Neolithic track is an ancient road. Hence, ridgeway is the answer.
10. first reference to White Horse Hill appears in ………. from the 1070s Answer: documents
– Sixth paragraph, first line. “The earliest evidence of a horse at Uffington is from the 1070s CE when ‘White Horse Hill’ is mentioned in documents from the nearby….” Earliest = First. Mention = Reference.
11. according to analysis of the surrounding ………., the Horse is Late Bronze Age / Early Iron Age Answer: soil
– Seventh paragraph, first line. “However,… testing was carried out…..on soil from two of the lower layers of the horse’s body, and from another cut near the base. The result was a date for the horse’s construction…….. a Late Bronze Age or Early Iron Age origin.” In this paragraph, the writer explained that the testing done on soil near the horse provided the date of the horse’s construction.
12. was a representation of goddess Epona – associated with protection of horses and ……….
Answer: fertility
– Eighth paragraph, fourth line. “Some researchers see the horse as representing the Celtic horse goddess Epona, who was worshipped as a protector of horses, and her associations with fertility.” Hence, goddess Epona was associated with fertility and the protection of horses.
13. was a representation of a Welsh goddess called ………. Answer: Rhiannon
– Eighth paragraph, ninth line. “It is possible that the carving represents a goddess in native mythology, such as Rhiannon, described in later Welsh mythology as a beautiful woman dressed in gold and riding a white horse.” Here, the writer said that the carving represents a goddess (Welsh goddess) like Rhiannon. Hence, the answer is Rhiannon.
Passage 2: I Contain Multitudes, Solution with Answer Key
14. What point does the writer make about microbes in the first paragraph? Answer: D
– They will continue to exist for longer than the human race. First paragraph’s first line. “Microbes, most of them bacteria, have populated this planet since long before animal life developed and they will outlive us.” Here, the writer says that the microbes will outlive us. Outlive = live longer than.
15. In the second paragraph, the writer is impressed by the fact that Answer: C
– the average individual has more microbial cells than human ones. Second paragraph, third line. “What is amazing is that while the number of human cells in the average person is about 30 trillion, the number of microbial ones is higher – about 39 trillion.” From this line, it is clear that humans have more microbial cells (39 trillion) than human cells (30 trillion).
16. What is the writer doing in the fifth paragraph? Answer: A
– explaining how a discovery was made Fifth paragraph, third line. “Using microscopes of his own design that could magnify up to 270 times, he examined a drop of water from a nearby lake and found it teeming with tiny creatures he called ‘animalcules’.” Here, the writer briey tells about a discovery (how animalcules were discovered).
Questions 17-20. Complete the summary using the list of words, A-H, below.
17. Many have a beneficial effect, and only a relatively small number lead to ………. . Answer: G
– Sixth paragraph, first line. “Yong’s book is in many ways a plea for microbial tolerance, pointing out that while fewer than one hundred species of bacteria bring disease, many thousands more play a vital role in maintaining our health.” Here, it is said that many thousands of microbial play an important (vital) role in maintaining our health, and less than one hundred cause disease. Disease = illness. Hence, the answer is G.
18. In fact, we should accept that our relationship with microbes is one based on ………. . Answer: B
– Sixth paragraph, sixth line. “Instead we should realize we have a symbiotic relationship, that can be mutually beneficial or mutually destructive.” The writer said that we have a symbiotic relationship with bacteria. Symbiotic (symbiosis) means interaction between two different organisms to the advantage of both. It is similar to partnership (word given in the box). Hence, the answer is B.
19. Our poor ………., our overuse of antibiotics, Answer: H
– Seventh paragraph, fifth line. “Our obsession with hygiene, our overuse of antibiotics and our unhealthy, low-fiber diets are disrupting the bacterial balance…..” The writer said that we have unhealthy and low-fiber diets (poor diets). Diet = nutrition (word given in the box). Hence the answer is H.
20. and our excessive focus on ………. are upsetting the bacterial balance Answer: E
– Seventh paragraph, fifth line. “Our obsession with hygiene, our overuse of antibiotics and our unhealthy, low-fiber diets are disrupting the bacterial balance…..” Obsession = Excessive focus. Hygiene = cleanliness (word given in the box). Hence, the answer is E.
Questions 21-26 Do the following statements agree with the claims of the writer in Reading Passage 2?
21. It is possible that using antibacterial products in the home fails to have the desired effect. Answer: YES
– Eighth paragraph, first line. “There are studies indicating that the excessive use of household detergents and antibacterial products actually destroys the microbes that normally keep the more dangerous germs at bay.” Here, it is given that the excess use of antibacterial products fails because they kill those bacteria that keep more dangerous bacteria away from us. It means antibacterial products kill beneficial bacteria instead of dangerous ones, which we actually want to kill. Hence, the answer is YES.
22. It is a good idea to ensure that children come into contact with as few bacteria as possible. Answer: NO
– Eighth paragraph, third line. “Other studies show that keeping a dog as a pet gives children early exposure to a diverse range of bacteria, which may help protect them against allergies later.” Here, the writer said that it is good to expose children to different bacteria as it protects them from allergies. Hence, the information in the passage contradicts the statement, and the answer is NO.
23. Yong’s book contains more case studies than are necessary. Answer: Not Given
– There is no such information given in the passage. There is a reference about Yong’s book and its case studies in the last paragraph, but there is no information about how many case studies Yong’s book has.
24. The case study about bacteria that prevent squid from being attacked may have limited appeal
Answer: YES
– Last paragraph, first line to 4th line. “Among the less appealing case studies……..Another is about squid that carry luminescent bacteria ….” “Among the less appealing case studies …” Less appeal = limited appeal. Hence, the answer is YES.
25. Efforts to control dengue fever have been surprisingly successful. Answer: NOT GIVEN
– The writer talk about dengue fever in last paragraph’s 6 & 7 line, but there is no such information about success of dengue control efforts. Hence, NOT GIVEN.
26. Microbes that reduce the risk of infection have already been put inside the walls of some hospital wards. Answer: NO
– Last paragraph, eighth line. “In the future, our ability to manipulate microbes means we could construct buildings with useful microbes built into their wall to fight o infections.” The writer said that we could construct walls with microbes built into them in the future. Thus, microbes are not already put inside the walls. Hence, the answer is NO.
Reading Passage 3: How to Make Wise Decisions, Solution with Answer Key
Questions 27-30. Choose the correct letter, A, B, C or D. (Multiple Choice)
27. What point does the writer make in the first paragraph? Answer: B
– A basic assumption about wisdom may be wrong. First paragraph’s first line from end. “Although the truly wise may seem few ……, given the right context” Here, the writer discussed that wisdom is not something they assumed of; in fact, it is something else. The meaning of the lines is that wisdom seems to be possessed by a few people (assumption), but in reality, most of us have ability to make wise decision. Hence, the assumption related to wisdom may be wrong.
28. What does Igor Grossmann suggest about the ability to make wise decisions?
Answer: C
– The importance of certain influences on it was underestimated. Second paragraph’s first line. “It appears that experiential, situational, and cultural factors are even more powerful in shaping wisdom than previously imagined,’ says Associate Professor Igor Grossmann…” Igor Grossmann said that certain factors are more powerful than previously imagined. Hence, their importance was underestimated.
29. According to the third paragraph, Grossmann claims that the level of wisdom an individual shows Answer: B
– will be different in different circumstances. Third paragraph’s fifth line. “Some situations are more likely to promote wisdom than others.” Thus, it is clearly given that wisdom changes according to situation. Situation = circumstance. It is claimed by Grossmann.
30. What is described in the fifth paragraph? Answer: D
– a recommended strategy that can help people to reason wisely. Fifth paragraph’s 3rd line to the end of this paragraph. “Research suggests that when……….related to wise decisions.” In these lines, the writer described about a research that suggests that if we see the situation like an observer, then we make judgments more broadly. So the strategy is to act as a third person (observer), not first person to make wise decision.
Questions 31-35. Complete the summary using the list of words, A-J, below.
The characteristics of wise reasoning
31. It is important to have a certain degree of ………. regarding the extent of our knowledge, Answer: D (modesty)
– Fourth paragraph, second line. “One is intellectual humility or recognition of the limits of our knowledge…” Limit = Extent. Humility = Modesty. Hence, a certain degree of humility is required
32. and to take into account ………. which may not be the same as our own. Answer: A (opinion)
– Fourth paragraph’s last line. “along with compromise or integration of different attitudes and beliefs” belief = Opinion. Integration of different attitudes and belief means we should include different opinions of others.
33. We should also be able to take a broad ………. of any situation. Answer: C (view)
– Fifth paragraph’s 3rd line. “and another is appreciation of perspectives wider than the issue at hand.” Perspective = view (word given in the box). Wider = Broad. The meaning of these lines is that we should take wider view of situation.
34. Grossmann also believes that it is better to regard scenarios with ………. . Answer: F (objectivity)
– Fifth paragraph’s first line to 3rd line, “Grossmann and his colleagues have also found……giving advice to a friend.” To know this question’s answer, you must know the meaning of “Objectivity”. Objective = of a person or judgment not influenced by personal feelings or opinions in considering and representing facts. So it is better to regard scenarios with objectivity; it can be done by looking at scenario from a third-party perspective, as though giving advice to a friend. Therefore, F is the answer.
35. By avoiding the first-person perspective, we focus more on ………. and on other moral ideals, which in turn leads to wiser decision-making. Answer: G (fairness)
– Fifth paragraph’s 4th line. “when we adopt a third person, ’Observer’ viewpoint we reason more broadly and focus more on interpersonal and moral ideals such as justice and impartiality.” Impartiality = Fairness. By reading these lines and available options, we find G (Fairness) is the best option that fits in this blank.
Questions 36-40. Do the following statements agree with the information given in Reading Passage 3?
(TRUE / FALSE / NOT GIVEN)
36. Students participating in the job prospects experiment could choose one of two perspectives to take. Answer: FALSE
– Seventh paragraph’s 4th line. “Participants in the group assigned………. in the control group.” Participants were assigned with perspective, not they could choose the role. They could only imagine their career. Hence, FALSE.
37. Participants in the couples experiment were aware that they were taking part in a study about wise reasoning. Answer: NOT GIVEN
– There is no such information given in the passage. There is a discussion about a study on couples in the eighth paragraph, but there is no information on whether the couples were aware or not about the experiment.
38. In the couples experiments, the length of the couples’ relationships had an impact on the results. Answer: NOT GIVEN
– There is no such information given in the passage.
39. In both experiments, the participants who looked at the situation from a more detached viewpoint tended to make wiser decisions. Answer: TRUE
– Seventh and eighth paragraph’s fourth line. Here, both experiments mean an experiment on students and an experiment on couples. The fourth line of the seventh paragraph “Participants in the group assigned to the ‘distant observer’ role displayed more wisdom-related reasoning ….” Fourth line of the eighth paragraph “Couples in the ‘other’s eyes’ condition were significantly more likely to rely on wise reasoning …” Detached viewpoint = other’s viewpoint = distant observer. Hence, participants who viewed the situation from other’s viewpoints make wiser decisions in both experiments.
40. Grossmann believes that a person’s wisdom is determined by their intelligence to only a very limited extent.
Answer: TRUE
– Last paragraph, first line. “We might associate wisdom with intelligence or particular personality traits, but research shows only a small positive relationship between wise thinking and crystallized intelligence ….” Small positive relationship = limited extent. Hence, the answer is TRUE.
Cambridge IELTS 16, Test 1, Reading Passage 1: Why We Need to Protect Bolar Bears, Solution with Answer Key
Cambridge IELTS 16, Test 1: Reading Passage 1 – Why We Need to Protect Bolar Bears with Answer Key. Here we will discuss pros and cons of all the questions of the passage with step by step Solution included Tips and Strategies.
1. Polar bears suer from various health problems due to the build -up of fat under their skin. Answer:FALSE
– First paragraph, third line. Start reading from “One reason for this is that they have up to 11 centimetres of fat underneath their skin. Humans with comparative levels of adipose tissue would be considered obese and would likely to suer from diabetes and heart disease. Yet the polar bear experiences no such consequences.” Here, the writer said that polar bears have 11 centimeters of fat under their skin. Humans with the same amount of fat are considered obese and suer from health issues, but polar bears have no issues. The statement in the question contradicts the information given in the passage. Hence, the answer is false.
2. The study done by Liu and his colleagues compared different groups of polar bears. Answer: FALSE
– In the second paragraph, the writer discussed the study done by Liu and colleagues. In the first line, it is given that they compared the genes (genetic structure) of polar bears with brown bears (closest relative). However, the question says that they compared different groups of polar bears. Further explanation: They compared polar bears with bears from a warmer climate. Thus, there is a contradiction, and the answer is false.
3. Liu and colleagues were the first researchers to compare polar bears and brown bears genetically. Answer: NOT GIVEN
– There is no such information given in the passage whether Liu and his colleagues were the first researchers to compare polar bears and brown bears or not. Hence, the answer is not given. Some information about Liu and his colleague’s research and their comparison between polar bears and brown bears is given in the second paragraph, but it is not given whether they were the first to compare these categories of bears or not.
4. Polar bears are able to control their levels of ‘bad’ cholesterol by genetic means. Answer: TRUE
– Second paragraph, fourth line. It is found by Liu and his colleagues that polar bears had a certain kind of gene (APoB) that reduced levels of bad cholesterol. Hence, the answer is true.
5. Female polar bears are able to survive for about six months without food. Answer: TRUE
– Third paragraph, sixth line. The writer said that female polar bears remain in their dens for about six months for the birth of their cubs. Lines from passage – “Once autumn comes around, these females will dig maternity dens in the snow and will remain there throughout the winter, both before and after the birth of their cubs. This process results in about six months of fasting (without food), where the female bears have to keep themselves and their cubs alive, depleting (reducing) their own calcium and calorie reserves.”
6. It was found that the bones of female polar bears were very weak when they came out of their dens in spring. Answer: FALSE
– You will nd the answer to this question in two sentences. Read the last line of the third paragraph. It is given that despite the loss of calcium and calorie, the bones of female polar bears remain strong and dense. Continue reading, and in the third line of the fourth paragraph. It is given that when they came out, there was no significant bone density loss.
7. The polar bear’s mechanism for increasing bone density could also be used by people one day. Answer: TRUE
– Fourth paragraph, last line. It is said that many bedridden (bedridden:- unable to walk or move/ conned to bed) humans can get benefit from polar bears’ bone remodeling mechanism. “Could potentially benefit”- there are chances that it can be used for human in the future. So the answer is true.
Questions from 8 to 13 are Completion Table
Reasons why polar bears should be protected
8. People think of bears as unintelligent and ………. Answer: violent
– Fifth paragraph, fourth line. “Bears, on the other hand, seem to be perceived as stupid and in many cases violent.” Unintelligent and stupid are synonyms. So, the answer is violent.
9. In Tennoji Zoo, a bear has been seen using a branch as a ………. Answer: tool
– Fifth paragraph, sixth line. “A male bear called GoGo in Tennoji Zoo, Osaka, has even been observed making use of a tool to manipulate his environment. The bear used a tree branch on multiple occasions to dislodge a piece of meat hung out of his reach.” The bear used a tree branch as a tool to change his environment. So, the answer is tool.
10. This allowed him to knock down some ………. Answer: meat
– Fifth paragraph, seventh line. “The bear used a tree branch on multiple occasions to dislodge (dislodge:- knock down) a piece of meat hung out of his reach.” The bear knocks down some meat.
11. A wild polar bear worked out a method of reaching a platform where a ………. was located. Answer: photographer
– Fifth paragraph, last line. “A calculated move by a male bear involved running and jumping onto barrels in an attempt to get to a photographer standing on a platform four metres high.” There was a photographer on a platform.
12. Polar bears have displayed behaviour such as conscious manipulation of objects and activity similar to a ………. Answer: game
– Sixth paragraph, second line. “For example, Ames observed bears putting objects in piles and then knocking them over in what appeared to be a game.” Read the rst line of this paragraph also, the writer said about deliberate and focused manipulation, which is similar to conscious manipulation. In the second line, the writer said that bears do something which looks like a game. So, game is the answer.
13. They may make movements suggesting ………. if disappointed when hunting.
Answer: frustration
– Seventh paragraph, first line. “As for emotions, while the evidence is once again anecdotal, many bears have been seen to hit out at ice and snow – seemingly out of frustration – when they have just missed out on a kill.” The writer said that when bears miss a kill, they hit ice because of frustration. They feel disappointed when they cannot hunt
Passage 2: The Step Pyramid of Djoser, Solution with Answer Key
Questions 14-20 Reading Passage 2 has seven paragraphs, A-G.
Choose the correct Heading for each paragraph from the list of headings below.
14. Paragraph A Answer: iv
– “A single certainty among other less definite facts”. ‘A’ paragraph, fourth line. “The evolution of the pyramid form has been written and argued about for centuries. However, there is no question that, as far as Egypt is concerned, it began with one monument to one king designed by one brilliant architect: the Step Pyramid of Djoser at Saqqara.”
15. Paragraph B Answer: vii
– An idea for changing the design of burial structures. ‘B’ paragraph, read from first line. “Djoser was the first king of the Third Dynasty of Egypt and the first to build in stone. Prior to Djoser’s reign, tombs were rectangular monuments made of dried clay brick.” (In these lines, the writer talks about previous designs.)
Now read from 4 line onwards. “For reasons which remain unclear, Djoser’s main official, whose name was Imhotep, conceived of building a taller, more impressive tomb for his king by stacking stone slabs on top of one another, progressively making them smaller, to form the shape now known as the Step Pyramid.”
16. Paragraph C Answer: ii
– A difficult task for those involved. C paragraph, sixth line. The weight of the enormous mass was a challenge for the builders, who placed the stones at an inward incline in order to prevent the monument breaking up.”
17. Paragraph D Answer: v
– An overview of the external buildings and areas. ‘D’ paragraph, second line. “The complex in which it was built was the size of a city in ancient Egypt and included a temple, courtyards, shrines, and living quarters for the priests. It covered a region of 16 hectares and was surrounded by a wall 10.5 meters high.”
18. Paragraph E Answer: i
– The areas and artefacts within the pyramid itself. ‘E’ paragraph, first line. “The burial chamber of the tomb, where the king’s body was laid to rest, was dug beneath the base of the pyramid, surrounded by a vast maze of long tunnels that had rooms o them to discourage robbers. One of the most mysterious discoveries found inside the pyramid was a large number of stone vessels. Over 40,000 of these vessels, of various form and shapes, were discovered in storerooms o the pyramid’s underground passage.”
19. Paragraph F Answer: viii
– An incredible experience despite the few remains. ‘F’ paragraph, second line. “Djoser’s grave goods, and even his body, were stolen at some point in the past and all archaeologists found were a small number of his valuables overlooked by the thieves. There was enough left throughout the pyramid and its complex, however, to astonish and amaze the archaeologists who excavated it.”
20. Paragraph G Answer: vi
– A pyramid design that others copied. ‘G’ paragraph, fth line. “The Step Pyramid was a revolutionary advance in architecture and became the archetype (archetype:- an original which has been imitated) which all other great pyramid builders of Egypt would follow.”
Questions 21-24 Complete the Notes below.
The Step Pyramid of Djoser
21. The complex that includes the Step Pyramid and its surroundings is considered to be as big as an Egyptian ………. of the past. Answer: city
– ‘D’ paragraph, second line. “The complex in which it was built was the size of a city in ancient Egypt ….” It means that the complex consisting of the Step Pyramid and its surroundings was as big as an Egyptian city.
22. The area outside the pyramid included accommodation that was occupied by ………. along with many other buildings and features. Answer: priests
– ‘D’ paragraph, second line. Continue reading where you found the answer to the 21st question. “….and living quarters for the priests.” Living quarters means there was accommodation for priests.
23. A wall ran around the outside of the complex and a number of false entrances were built into this. In addition, a long ..…. encircled the wall. Answer: trench
– ‘D’ paragraph, 6 line. “the entire wall was then ringed(encircled) by trench ….” Hence, a trench encircled the wall.
24. As a result, any visitors who had not been invited were cleverly prevented from entering the pyramid grounds unless they knew the ………. of the real entrance. Answer: location
– ‘D’ paragraph, eighth line. “If someone wished to enter, he or she would have needed to know in advance how to nd the location of the true opening in the wall.” Here, the true opening is similar to the real entrance. Hence, they need to know the location of the real entrance.
Questions 25-26: Choose TWO letters, A-E Which TWO points does the writer make about King Djoser?
25. Answer: B
– There is disagreement concerning the length of his reign. ‘B’ paragraph, last three line. “Djoser is thought to have reigned for 19 years, but some historians and scholars attribute a much longer time for his rule, owing to the number and size of the monuments he built.”
26. Answer: D
– A few of his possessions were still in his tomb when archaeologists found it. ‘F’ paragraph, third line from end. “all archaeologists found were a small number of his valuables overlooked by thieves .”
Passage 3: The Future of Work, Solution with Answer Key
Questions 27-30 Choose the correct letter, A, B, C or D. (Multiple Choice)
27. The first paragraph tells us about Answer: B
– First paragraph, first line. “3-14% of the global workforce will need to switch to a different occupation within the next 10-15 years, and all workers will need to adapt as their occupations evolve alongside increasingly capable machines.” Proportion = 3-14%
28. According to the second paragraph, what is Stella Pachidi’s view of the ‘knowledge economy’? Answer: D
– Second paragraph, first line. “Dr Stella Pachidi from Cambridge Judge Business School believes that some of the most fundamental changes are happening as a result of the ‘algorithmication’ of jobs that are dependent on data rather than on production – the so-called knowledge economy.”
29. What did Pachidi observe at the telecommunications company? Answer: C
– Seventh paragraph. Read full paragraph. It is said that workers feed algorithms with incorrect data to achieve their targets. Hence, they are making sure that algorithms (AI) produce the results that they want.
30. In his recently published research, Ewan McGaughey
Answer: D
– Twelfth paragraph. Read the complete 12 paragraph and continue to read the 13 paragraph until its 3 line ….work and leisure. Here, the writer discussed McGaughey’s recent research in which he gives methods to handle changes in the job market
Questions 31-34 Complete the summary using the list of words, A-G, below.
31. Stella Pachidi of Cambridge Judge Business School has been focusing on the ‘algorithmication’ of jobs which rely not on production but on ………. Answer: G
– Second paragraph, first line. “Dr Stella Pachidi from Cambridge Judge Business School believes that some of the most fundamental changes are happening as a result of the ‘algorithmication’ of jobs that are dependent on data rather than on production – the so-called knowledge economy.” Information is similar to word data given in the passage.
32. While monitoring a telecommunications company, Pachidi observed a growing ………. on the recommendations made by AI, as workers begin to learn through the ‘algorithm’s eyes’. Answer: E
– Sixth paragraph, second line. In the fifth paragraph, the writer discussed Pachidi’s monitoring of telecommunications company in the second line. After this, the writer told about Pachidi’s observations in a telecommunication company. Then start reading from the sixth paragraph’s second line. “In cases like this, Pachidi believes, a short-sighted view begins to creep into working practices whereby workers learn through the ‘ algorithm eyes’ and become dependent on its instructions.”
Here, dependent means reliance, and recommendations mean instructions.
33. Meanwhile, staff are deterred from experimenting and using their own ………., and are therefore prevented from achieving innovation. Answer: C
– Sixth paragraph, fourth line. “Alternative explorations – where experimentation and human instinct lead to progress and new ideas – are effectively discouraged.” Instinct means intuition. Sta is discouraged from experimenting and using their instinct. Hence, the answer is intuition.
34. To avoid the kind of situations which Pachidi observed, researchers are trying to make AI’s decision-making process easier to comprehend, and to increase users’ ………. with regard to the technology. Answer: F
– Eighth paragraph, first line. “It’s scenarios like these that many researchers are working to avoid. Their objective is to make AI technologies more trustworthy and transparent, so that organisations and individuals understand how AI decisions are made.” Comprehend means understand. Making technologies more trustworthy and transparent will increase the confidence of users in AI. Hence, confidence is the answer.
Questions 35-40. Look at the following statements (Questions 35-40) and the list of people below.
35. Greater levels of automation will not result in lower employment. Answer: B
– Tenth paragraph. Read full paragraph. The meaning of this paragraph is that taking 50 out of 100 jobs by robots does not mean we are left with 50 jobs. The number of jobs will increase.
36. There are several reasons why AI is appealing to businesses. Answer: A
– Third paragraph, first line. “In many cases, they can outperform humans, says Pachidi. Organisations are attracted to using algorithms because they want to make choices based on why they consider is “perfect information”, as well as to reduce costs and enhance productivity.” So, there are multiple reasons.
37. AI’s potential to transform people’s lives has parallels with major cultural shifts which occurred in previous eras. Answer: C
– Twelfth paragraph. Read full paragraph. From the perspective of the question, the meaning of this paragraph is that in the past, change could cause redundancy (unemployment because of no work). So AI, automation and robotics can cause unemployment corresponding (parallel) to the past (history).
38. It is important to be aware of the range of problems that AI causes.
Answer: A
– Eighth paragraph, third line. “We need to make sure we fully understand the dilemmas that this new world raises regarding expertise, occupational boundaries and control.”
39. People are going to follow a less conventional career path than in the past. Answer: B
– Ninth paragraph, second line. “’The traditional trajectory of full-time education followed by full-time work followed by a pensioned retirement is a thing of the past,’ says Low. Instead, he envisages a multistage employment life; one where retraining happens across the life course, and where multiple jobs and no job happen by choice at different stages.”
40. Authorities should take measures to ensure that there will be adequately paid work for everyone. Answer: C
– Second last paragraph, third line. “McGaughey’s findings are a call to arms to leaders of organisations, governments and banks to preempt the coming changes with bold new policies that guarantee full employment, fair incomes (adequately paid work) and a thriving economic democracy.”
Answer Key – Why We Need to Protect Bolar Bears
Why We Need to Protect Bolar Bears Reading Answers
Paragraph 2 provides information on the role of the huarango tree: “it could reach deep water sources”. So the answer is ‘water’.
access = reach
Answer: water.
2. Answer: diet
Key words: crucial, local, inhabitants, long time ago
It is stated in paragraph 2 that “the huarango was key to the ancient people’s diet”.
crucial = key
a long time ago = ancient
Thus, the answer is ‘diet’.
Answer: diet.
3. Answer: drought
Key words: people, survive, periods
Still in paragraph 2, we learn that the huarango tree “allowed local people to withstand years of drought when their other crops failed”.
survive = withstand
Thus, the answer is ‘drought’.
Answer: drought.
4. Answer: erosion
Key words: prevents, soil
It is stated in paragraph 2 that “Cutting down native woodland leads to erosion, as there is nothing to keep the soil in place”. Here, ‘native woodland’ refers to the huarango trees. The sentence states that huarango trees keep the soil in place, thereby preventing soil erosion (because if those trees are cut down, erosion will occur). Therefore, the blank should be filled with ‘erosion’.
Answer: erosion.
5. Answer: desert
Key words: prevents, land, becoming
The author concludes paragraph 2 by stating that: “So when the huarangos go, the land turns into a desert.” It can be inferred that huarangos prevent land from becoming a desert.
become = turn into
Answer: desert.
QUESTIONS 6-8: COMPLETE THE NOTES BELOW.
6. Answer: (its / huarango / the) branches
Paragraph 3 gives information about traditional uses of huarangos (“For centuries the huarango tree was vital to the people”). Firstly, leaves and bark were used for “herbal remedies”, which refers to types of medicine. So answers for Q7 should be ‘leaves’ and ‘bark’ (in any order).
Secondly, its branches were used for “charcoal for cooking and heating”. In other words, branches were used as fuel for cooking and heating. Thus, the answer for Q6 is ‘branches’.
Finally, its trunk was used to build houses. ‘building’ is synonymous to ‘construction’, so the answer must be ‘trunk’.
medicine = remedies
construction = build (building)
Answer: 6. Branches; 7. Leaves & bark (in any order); 8. Trunk.
7. Answer: IN EITHER ORDER (BOTH REQUIRED FOR ONE MARK) leaves (and) bark
Paragraph 3 gives information about traditional uses of huarangos (“For centuries the huarango tree was vital to the people”). Firstly, leaves and bark were used for “herbal remedies”, which refers to types of medicine. So answers for Q7 should be ‘leaves’ and ‘bark’ (in any order).
Secondly, its branches were used for “charcoal for cooking and heating”. In other words, branches were used as fuel for cooking and heating. Thus, the answer for Q6 is ‘branches’.
Finally, its trunk was used to build houses. ‘building’ is synonymous to ‘construction’, so the answer must be ‘trunk’.
medicine = remedies
construction = build (building)
Answer: 6. Branches; 7. Leaves & bark (in any order); 8. Trunk.
8. Answer: (its / huarango / the) trunk
Paragraph 3 gives information about traditional uses of huarangos (“For centuries the huarango tree was vital to the people”). Firstly, leaves and bark were used for “herbal remedies”, which refers to types of medicine. So answers for Q7 should be ‘leaves’ and ‘bark’ (in any order).
Secondly, its branches were used for “charcoal for cooking and heating”. In other words, branches were used as fuel for cooking and heating. Thus, the answer for Q6 is ‘branches’.
Finally, its trunk was used to build houses. ‘building’ is synonymous to ‘construction’, so the answer must be ‘trunk’.
medicine = remedies
construction = build (building)
Answer: 6. Branches; 7. Leaves & bark (in any order); 8. Trunk.
QUESTIONS 9-13: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
There is no information regarding this. The answer is not given. We only learn that Whaley is trying to get local people interested in planting more huarangos and to use the products from the tree to “create a sustainable income”. There is no mention of the local people telling Whaley about the traditional uses of the tree.
Answer: NOT GIVEN.
10. Answer: FALSE
Key words: Alberto Benevides, profit, growing, huarangos
By skimming the proper noun ‘Alberto Benevides’, we can find the information we need in paragraph 6: “His farm is relatively small and doesn’t yet provide him with enough to live on”. The huarango farm doesn’t provide him with enough to live, which means that the profit from huarangos is not yet enough. Thus, it cannot be said that Alberto Benevides is making a good profit.
Wildlife is mentioned in paragraph 7 as “movement of mammals, birds and pollen”. Whaley hopes to counteract, or reduce, the threat to wildlife by persuading farmers to let him plant forest corridors on their land. In other words, he needs farmers’ co-operation because without their permission, he cannot plant forest corridors, which are necessary to enable the natural movement of mammals, birds and pollen in the area. So the answer is TRUE.
Answer: TRUE.
12. Answer: FALSE
Key words: Whaley, project, succeed, extended
Whaley explains about his project in paragraph 8: “’It’s not like a rainforest that needs to have this huge expanse. […] If you just have a few trees left, the population can grow up quickly […]”. Thus, it can be understood that just a small area of huarangos can attract a wildlife population quickly, without a huge area or a great number of trees. In other words, Whaley’s project does not need to be extended over a large area. The statement is FALSE.
The last paragraph mentions that: “He sees his project as a model that has the potential to be rolled out across other arid areas around the world”. These areas include Africa. However, Whaley does not deliberately say that he has plans to set up another project in Africa; he only mentions the possibility that the model could be implemented there and in lots of other places where there is drought. Thus, the answer is NOT GIVEN.
Answer: NOT GIVEN.
cambridge ielts 15 reading test 4 passage 1 answers
QUESTIONS 14-19: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
14. Answer: NOT GIVEN
Key words: La Gomera, mountainous, Canary Islands
It is stated in paragraph 1 that La Gomera is one of the Canary Islands and that it is mountainous. However, there is no information regarding whether La Gomera is the most mountainous or not. Thus, the answer is NOT GIVEN.
In paragraph 5, Carreiras contends that “’In daily life they use whistles to communicate short commands, but any Spanish sentence could be whistled”. In fact, “…silbadores are able to pass a surprising amount of information via their whistles”. So silbo, or whistles, can be used to communicate any messages, not just short ones. It’s just that short messages are more common in daily life. Thus, the statement ‘Silbo is only appropriate for short and simple messages’ is FALSE.
Paragraph 6 mentions the results of the brain-activity study. Regarding silbadores, the left temporal lobe and other key regions in the brain’s frontal lobe responded. However, in non-whistlers, “activation was observed in all areas of the brain”. In paragraph 7, this finding is explained further: “The non-Silbo speakers were not recognising Silbo as a language. They had nothing to grab onto, so multiple areas of their brains were activated”. Thus, these can be seen as ‘different results’.
Answer: TRUE.
17. Answer: FALSE
Key words: Spanish, introduced, Silbo, 15th century
It is stated in paragraph 8 that “indigenous Canary Islanders […] already had a whistled language when Spain conquered the volcanic islands in the 15th century”. Thus, the Spanish could not have introduced Silbo to the islands as Silbo was present even before their arrival.
Still in paragraph 8, the author said that “There are thought to be as many as 70 whistled languages still in use, though only 12 have been described and studied scientifically”.
in existence = in use
It can be inferred from this sentence that not all whistled languages (only 12/70) have been studied, so there cannot be precise data available regarding all whistled languages. The statement is FALSE.
Answer: FALSE.
19. Answer: TRUE
Key words: children, Gomera, learn, Silbo
The last paragraph mentions the attempts of Canaries’ authorities to ensure the survival of Silbo. “Since 1999, Silbo Gomero has been taught in all of the island ‘s elementary schools”. Thus, it can be understood that the Silbo language is still being taught to children until now. The statement is therefore true.
With regard to high and low-frequency tones, it is stated that: “Silbo is a substitute for Spanish, with individual words recoded into whistles which have high and low-frequency tones”. Thus, it is clear that the blank should be filled with ‘words’.
Answer: words.
21. Answer: finger
Key words: pitch, whistle, controlled, silbador’s
In paragraph 4 again, the whistler can increase the whistle’s pitch by putting “a finger in his or her mouth”. In other words, this can be paraphrased into the passive voice as ‘the pitch of whistle can be increased using the silbador’s finger’. Thus, the answer is ‘finger’.
Answer: finger.
22. Answer: direction
Key words: changed, cupped, hand
Still in paragraph 4: “[…] the other hand can be cupped to adjust the direction of the sound”.
change = adjust
Thus, it is clear that the answer is ‘direction of the sound’. However, as only one word is allowed, the final answer is ‘direction’.
Answer: direction.
23. Answer: commands
Key words: everyday, use, transmission, brief
“’In daily life they use whistles to communicate short commands, but any Spanish sentence could be whistled.”
everyday = daily
transmission = communicate (communication)
short = brief
In other words, whistles are used in everyday life for the transmission of brief commands. The answer is ‘commands’.
“Silbo has proved particularly useful when fires have occurred on the island and rapid communication across large areas has been vital”.
quickly = rapid (rapidly)
essential = vital
relay information = communicate
e.g. = such as, for example
This sentence means that silbo can be used to inform people about (communicate) essential (vital) information such as fires. Thus, the answer is ‘fires’.
Answer: fires.
25. Answer: technology
Key words: future, threat, new
“But with modern communication technology now widely available, researchers say whistled languages like Silbo are threatened with extinction”.
new = modern
under threat = be threatened
It can be understood from this sentence that Silbo is threatened because of new, modern communication technology. But we can only fill the gap with one word, the correct answer must be ‘technology’.
“The local authorities are trying to get an award from the organisation to declare [Silbo Gomero] as something that should be preserved for humanity”. The ‘organisation’ here refers to UNESCO. Thus, the local authorities are hoping to receive a UNESCO award to preserve Silbo.
receive = get
Answer: award.
cambridge ielts 15 reading test 4 passage 2
PASSAGE 3: ENVIRONMENTAL PRACTICES OF BIG BUSINESSES
QUESTIONS 27-31: COMPLETE THE SUMMARY USING THE LIST OF WORDS, A-J, BELOW.
27. Answer: D
28. Answer: E
Key words: lack, governments, public
In paragraph 1 we find: “When government regulation is effective, and when the public is environmentally aware, environmentally clean businesses may out-compete dirty ones”. The last sentence of paragraph 1 states that: “the reverse is likely to be true if government regulation is ineffective and if the public doesn’t care”. The term ‘the reverse’ here refers to dirty businesses out-competing environmentally clean ones. In other words, ineffective government regulation and an indifferent public could lead to environmental problems. Ineffective government regulation can be paraphrased into ‘lack of control by governments’; and ‘the public doesn’t care’ can be paraphrased into ‘lack of public involvement’.
control = regulation
Answer: 28. E; 29. F
29. Answer: F
Key words: lack, governments, public
In paragraph 1 we find: “When government regulation is effective, and when the public is environmentally aware, environmentally clean businesses may out-compete dirty ones”. The last sentence of paragraph 1 states that: “the reverse is likely to be true if government regulation is ineffective and if the public doesn’t care”. The term ‘the reverse’ here refers to dirty businesses out-competing environmentally clean ones. In other words, ineffective government regulation and an indifferent public could lead to environmental problems. Ineffective government regulation can be paraphrased into ‘lack of control by governments’; and ‘the public doesn’t care’ can be paraphrased into ‘lack of public involvement’.
control = regulation
Answer: 28. E; 29. F
30. Answer: H
Key words: environmental, problems, destruction
We need to find examples of two environmental problems caused by ‘lack of control by governments and lack of public involvement’. Paragraph 1 mentions:
“an unmanaged fishery without quotas”, which means that fishing is done without limit. This can also be called ‘overfishing’.
“international logging companies […] with corrupt officials and unsophisticated landowners”. This refers to logging companies that overexploit the tropical rainforests with the backup of officials and landowners. Thus, this can be called ‘destruction of trees’.
Answer: 30. H; 31. B
31. Answer: B
Key words: environmental, problems, destruction
We need to find examples of two environmental problems caused by ‘lack of control by governments and lack of public involvement’. Paragraph 1 mentions:
“an unmanaged fishery without quotas”, which means that fishing is done without limit. This can also be called ‘overfishing’.
“international logging companies […] with corrupt officials and unsophisticated landowners”. This refers to logging companies that overexploit the tropical rainforests with the backup of officials and landowners. Thus, this can be called ‘destruction of trees’.
Answer: 30. H; 31. B
QUESTIONS 32-34: CHOOSE THE CORRECT LETTER, A, B, C OR D.
32. Answer: C could be prevented by the action of ordinary people
Paragraph 3 emphasizes the “ultimate responsibility of the public”. The public can make destructive policies “unprofitable and illegal”, which means that they can prevent or hinder wrong actions. They can also “make sustainable environmental policies profitable”, which means they can promote good actions. Thus, the main idea of this paragraph is that environmental damage could be prevented by the action of ordinary people.
ordinary people = the public
Answer: C
33. Answer: D influence the environmental policies of businesses and governments
Key words: fourth, paragraph, ways, public
Paragraph 4 mentions several actions to help the environment, such as suing environmentally harmful businesses, buying sustainably harvested products or pressing governments to enforce good environmental regulations. Because these are not individual actions directly impacting the environment but rather actions imposed on other people, A is incorrect. B is irrelevant because no information about learning is given. The same goes for C – specific environmental disasters are mentioned, but this is in reference to suing businesses, not raising awareness. The only appropriate answer is D, because the actions listed above influence the policies of businesses and governments.
Answer: D.
34. Answer: B A fast-food company forced their meat suppliers to follow the law
Key words: pressure, exerted, business, BSE
By skimming “BSE”, we can find the information we need in paragraph 5. Then, we must find which sentence mentions “big business” and what pressure that business exerted. We find that “when a major fast-food company then made the same demands […], the meat industry complied within weeks”. Here, ‘the same demands’ refer to the FDA’s demand that the meat industry must follow the rules and abandon practices associated with the risk of BSE. Thus, it can be understood that a fast-food company pressured the meat industry, or meat suppliers, to follow the FDA regulations.
big business = major company
law = rules
Answer: B.
QUESTIONS 35-39: DO THE FOLLOWING STATEMENTS AGREE WITH THE CLAIMS OF THE WRITER IN READING PASSAGE 3?
35. Answer: YES
Key words: public, fund, environmental, practices
In paragraph 6, the author believes that “the public must accept […] higher prices for products to cover the added costs, if any, of sound environmental practices”.
By saying that the public should pay for the added costs of good practices, the author means that they should fund such practices with their money. Thus, this statement agrees with the author’s opinion.
good environmental practices = sound environmental practices
Still in paragraph 6, the author mentions that businesses will not apply moral principles without government regulations to deal with environmental problems. There is no information regarding the moral principles of different businesses. Thus, the answer is NOT GIVEN.
It is stated in the last paragraph that “My conclusion is not a moralistic one about who is right or wrong, admirable or selfish, a good guy or a bad guy”. Thus, the author does not want to make a clear distinction between right (acceptable behaviour) and wrong (unacceptable behaviour). So the statement contradicts the author’s view.
Answer: NO.
38. Answer: YES
Key words: public, successfully, influenced, businesses, past
There are two relevant sentences in the last paragraph:“In the past, businesses have changed when the public came to expect and require different behaviour”. Secondly: “I predict that in the future, just as in the past, changes in public attitudes will be essential for changes in businesses’ environmental practices”. The sentences mean that businesses were influenced by the public’s expectations and requirements.
The author predicts in the last paragraph that in the future, “In the future…changes in public attitudes will be essential for changes in businesses’ environmental practices”. However, there is no information saying that businesses will show more or less concern for the environment. Thus, the answer for this is NOT GIVEN.
Answer: NOT GIVEN.
QUESTIONS 40: CHOOSE THE CORRECT LETTER, A, B, C OR D.
40. Answer: D Are big businesses to blame for the damage they cause the environment?
This passage discusses the blame for environmental issues. However, the author raises a different viewpoint from conventional ones, and has made this clear throughout the passage: “It is easy for the rest of us to blame a business” (paragraph 2); “Our blaming of businesses also ignores the ultimate responsibility of the public” (paragraph 3); “I place the ultimate responsibility for business practices harming the public on the public itself” (paragraph 7). Thus, the author wants to look at the problem from the perspective of the responsibility of the public, and contends that businesses are not the only ones to blame. Thus, the most appropriate subheading must be D – ‘Are big businesses to blame for the damage they cause the environment?”.
It is mentioned in the first paragraph that “After leaving school, Moore hoped to become a sculptor, but instead he complied with his father’s wish”. To ‘comply with something’ means to ‘agree to or obey something’, so Moore agreed to do what his father wished. Thus, this statement is clearly true.
want = wish
Answer: TRUE.
2. Answer: FALSE
Key words: began, sculpture, first term, Leeds School of Art
By skimming the proper noun ‘Leeds School of Art’, we can find information in paragraph 2 saying that “Although he wanted to study sculpture, no teacher was appointed until his second year”. This means that he could not have studied sculpture in his first year, not to mention his first term. Thus, the answer is FALSE.
Answer: FALSE.
3. Answer: NOT GIVEN
Key words: Royal College of Art, reputation, sculpture, excellent
By skimming the proper noun ‘Royal College of Art’, we can find information in paragraphs 2 and 3 that mention his period of study there. However, there is no information on the reputation of this school. Therefore, the answer is NOT GIVEN.
Answer: NOT GIVEN.
4. Answer: TRUE
Key words: aware, ancient sculpture, visiting, London museums
In paragraph 3, it is stated that Moore visited many London museums where “he discovered the power and beauty of ancient Egyptian and African sculpture”.
The proper noun ‘Trocadero’ can be found through skimming in paragraph 4. It was in this museum that Moore “became fascinated” with a Mayan sculpture, but there is no information on whether the public also found it fascinating. Thus, we do not know if this Mayan sculpture attracted public interest or not.
Answer: NOT GIVEN.
6. Answer: FALSE
Key words: Mayan sculpture, similar, other, stone sculptures
Still in paragraph 4, regarding the Mayan sculpture, Moore thought it “had a power and originality that no other stone sculpture possessed”. The word “originality” and the phrase “no other stone sculpture possessed” imply that the Mayan sculpture was different and unlike any others. Thus, it would be wrong to say that the Mayan sculpture was similar to other stone sculptures.
Answer: FALSE.
7. Answer: TRUE
Key words: artists, Unit One, modern art, architecture, popular
Unit One is mentioned in paragraph 5: “The aim of the group was to convince the English public of the merits of […] modern art and architecture”. This means that Unit One wanted to prove to the public that modern art and architecture was of good quality and excellence. In other words, they wanted to make it more popular among the public.
Answer: TRUE.
QUESTIONS 8-13: COMPLETE THE NOTES BELOW.
8. Answer: resignation
Key words: urged, offer, leave, Royal College
Paragraph 6 mentions the event of Moore leaving the Royal College: “There were calls for his resignation from the Royal College, and the following year […] he left […]”. This means that people wanted Moore to leave by offering his resignation (an announcement made by Moore himself that he would leave the job). Thus, Moore was urged by his employers at the Royal College to offer his resignation.
Answer: resignation.
9. Answer: materials
Key words: turns to, drawing, sculpting, not, available
Moving on to the 1940s, paragraph 8 mentions: “A shortage of materials forced him to focus on drawing”. This means that Moore focused on drawing because materials for sculpting were not available.
turn to = focus on
not available = shortage
Answer: materials.
10. Answer: miners
Key words: visiting, hometown, drawings
We know from the start of the passage that Moore’s hometown was named Castleford, so we should be looking for this proper noun. In paragraph 8 we find: “In 1942, he returned to Castleford to make a series of sketches of the miners who worked there”.
some drawings ~ a series of sketches
Answer: miners.
11. Answer: family
Key words: employed, produce, sculpture, of
Paragraph 9: “In 1944, Harlow, a town near London, offered Moore a commission for a sculpture depicting a family”. The phrase ‘offer someone commission’ means ‘employ someone and pay them with money’. In this case, Moore was employed to make a sculpture of a family.
employ = offer [someone] a commission
Answer: family.
12. Answer: collectors
Key words: start, buy, Moore’s work
Paragraph 9: “Moore’s work became available to collectors all over the world”. While this sentence alone cannot prove that Moore’s work was ‘bought’ by collectors, it is supported by the following sentence: “the boost to his income […]”. Thus, it can be inferred that Moore gained extra income thanks to collectors buying his work.
This question directly follows question 12: “The boost to his income enabled him to take on ambitious projects”
increase = boost
make it possible for = enable
Answer: income.
PASSAGE 2: THE DESOLENATOR : PRODUCING CLEAN WATER
QUESTIONS 14-20: READING PASSAGE 2 HAS SEVEN SECTIONS, A-G.
14. Answer: iii
Section A introduces Janssen’s device, which originally comes from the idea of “rooftop solar heating systems” in Southeast Asia. Two decades later, he “developed that basic idea he saw in Southeast Asia into a portable device…” Thus, the only appropriate heading for this section is iii – ‘From initial inspiration to new product’.
Answer: iii.
15. Answer: vi
Section B starts by mentioning the function of the desolenator: it can “take water from different places, such as the sea, rivers, boreholes and rain, and purify it for human consumption”. Thus, ‘the sea, rivers, boreholes and rain’ can be regarded as different sources of water which can be purified (cleaned) by the device. So the heading is vi – ‘Cleaning water from a range of sources’.
clean = purify
Answer: vi.
16. Answer: v
Section C explains how the device works. It starts by emphasizing that “unlike standard desalination techniques, it (the desolenator) doesn’t require a generated power supply: just sunlight”. This is considered the feature of the desolenator which makes it different from other alternatives. Thus, the heading is v – ‘What makes the device different from alternatives’.
different = unlike
Answer: v.
17. Answer: x
The topic sentence of Section D is right at the beginning: “A recent analysis found that at least two-thirds of the world’s population lives with severe water scarcity for at least a month every year”. The section then continues by describing the hardships in such regions with water shortage, with different vocabulary for the same phenomenon: “water scarcity”, “water stress”. So the correct heading must be x – ‘The number of people affected by water shortages’.
water shortage = water stress = water scarcity
Answer: x.
18. Answer: iv
This section names “a wide variety of users” for the desolenator, both in the developing and developed world. In the developing world, customers can be “those who cannot afford the money for the device outright and pay through microfinance, and middle-income homes that can lease their own equipment”. Meanwhile, potential markets in developed countries are “niche markets where tap water is unavailable”. Therefore, the most suitable heading for Section E would be iv – ‘The range of potential customers for the device’.
customers ~ users
Answer: iv.
19. Answer: viii
This section discusses the price of the desolenator. Janssen said that his company has a “social mission” and that the main application would be in “the developing world and humanitarian sector”. By saying “this is the way we will proceed”, Janssen implies that the company will proceed to produce devices that can help those in need. Thus, it can be inferred that profit is not the primary goal for Janssen. The answer is viii.
Answer: viii.
20. Answer: i
This section mentions the funding of the project (“It has raised £340,000 in funding so far”) and its future prospects (“the company aims to be selling 1,000 units a month”). Thus, the most appropriate heading is i – ‘Getting the finance for production’.
finance = funding
Answer: i.
QUESTIONS 21-26: COMPLETE THE SUMMARY BELOW.
21. Answer: wheels
Key words: device, used, different locations,
Section C explains how the desolenator works: “It measures 120 cm by 90 cm, and is easy to transport, thanks to its two wheels”. ‘easy to transport’ has been paraphrased into ‘can be used in different locations’. The feature that makes this possible is its ‘two wheels’. However, as we can only use ONE WORD, the answer must be ‘wheels’.
Answer: wheels.
22. Answer: film
Key words: water, fed, pipe, flows, solar panel
“Water enters through a pipe, and flows as a thin film between a sheet of double glazing and the surface of a solar panel”. After water enters a pipe (or is ‘fed into’ a pipe), a thin film of water flows out, between ‘a sheet of double glazing and the surface of a solar panel’. It can be inferred that the film of water flows over the surface of a solar panel. Therefore, the blank should be filled with ‘film’.
Answer: film.
23. Answer: filter
Key words: any, particles, water, caught in
“The device has a very simple filter to trap particles”.
catch = trap
So this sentence can be paraphrased into the passive voice as ‘particles are trapped/caught in a very simple filter’. The answer is ‘filter’.
Answer: filter.
24. Answer: waste
Key words: purified, water, tube, types, through another
This sentence distinguishes between two types of liquid that come out through two different tubes. In Section C: “There are two tubes for liquid coming out: one for the waste – salt from seawater, fluoride, etc. – and another for the distilled water”. The term ‘distilled water’ is synonymous to ‘purified water’, so the other type of liquid must be ‘waste’.
The last sentence of section C states that: “The performance of the unit is shown on an LCD screen and transmitted to the company which provides servicing when necessary”.
The first part of the sentence can be paraphrased using the passive voice into ‘an LCD screen shows the performance of the unit’.
display = show
device = unit
So the answer for Q25 is ‘performance’.
The second part of the sentence means that the information lets the company know when it is necessary to do servicing, i.e. when the device requires servicing. So the answer for Q26 is ‘servicing’.
The last sentence of section C states that: “The performance of the unit is shown on an LCD screen and transmitted to the company which provides servicing when necessary”.
The first part of the sentence can be paraphrased using the passive voice into ‘an LCD screen shows the performance of the unit’.
display = show
device = unit
So the answer for Q25 is ‘performance’.
The second part of the sentence means that the information lets the company know when it is necessary to do servicing, i.e. when the device requires servicing. So the answer for Q26 is ‘servicing’.
require = necessitate (necessary)
Answer: performance; servicing.
PASSAGE 3: WHY FAIRY TALES ARE REALLY SCARY TALES
QUESTIONS 27-31: COMPLETE EACH SENTENCE WITH THE CORRECT ENDING, A-F, BELOW.
27. Answer: C
Key words: fairy tales, details, plot
The very first sentence of the passage mentions that: “[…] the same story often takes a variety of forms in different parts of the world”.
Thus, the matching answer is C, and the complete sentence is “In fairy tales, details of the plot show considerable global variation.”
global = world
variation = variety = different
Answer: C.
28. Answer: B
Key words: Tehrani, rejects, useful, lessons, life
Paragraph 2 mentions: “the idea that they contain cautionary messages”. Here, ‘cautionary messages’ refer to the warnings or lessons for life, such as listening to your mother and avoid talking to strangers. This idea may be “what we find interesting” about fairy tales, and why it has survived till this day. However, Tehrani’s research suggests otherwise. Therefore, it can be understood that : Tehrani rejects the idea that the useful, survival-relevant lessons in fairy tales are the reason for their survival.
Still in paragraph 2: “That hasn’t stopped anthropologists, folklorists and other academics devising theories to explain the importance of fairy tales in human society”.
Thus, there are various theories about the social significance of fairy tales devised by various academics. However, according to Tehrani, “’We have this huge gap in our knowledge about the history and prehistory of storytelling”, which implies that such theories are developed without full knowledge on the topic, i.e. without factual basis. So, the complete sentence is: Various theories about the social significance of fairy tales have been developed without factual basis.
develop = devise
significance = importance
social = in society
factual basis = knowledge
Answer: F.
30. Answer: A
Key words: insights, development, fairy tales
It is stated in the last sentence of paragraph 2 that: “Now Tehrani has found a way to test these ideas, borrowing a technique from evolutionary biologists”. What Tehrani wants to discover is how fairy tales have “evolved” and “survived”, using the same methods of ‘phylogenetic analysis’ used by biologists (paragraph 3). Therefore, it can be understood that the development or evolution of fairy tales can be studied through methods used by biologists. This gives the correct sentence: Insights into the development of fairy tales may be provided through methods used in biological research.
development = evolution (evolve)
biological research = biologist
Answer: A.
31. Answer: E
Key words: analysed, Tehrani
Paragraph 4 mentions that Tehrani focused on analysing variants of two fairy tales: Little Red Riding Hood and The Wolf and The Kids, and “he ended up with 58 stories recorded from oral traditions”. Thus, it can be inferred that these fairy tales were traditionally spoken rather than written. The complete sentence is: All the fairy tales analysed by Tehrani were originally spoken rather than written.
analyse = analysis
spoken = oral
originally = tradition (traditionally)
Answer: E.
QUESTIONS 32-36: COMPLETE THE SUMMARY USING THE LIST OF WORDS, A-L, BELOW.
Tehrani’s use of ‘phylogenetic analysis’ can be found from paragraph 3 onwards. This process is used by biologists to “work out the evolutionary history, development and relationships among groups of organisms…”
Paragraph 4: “Once his phylogenetic analysis had established that they (the stories) were indeed related, he used the same methods to explore how they have developed and altered over time”, meaning that the phylogenetic analysis was aimed at testing the relations, or links, among these 58 stories. Thus, the answer for this question is D – ‘links’.
links = relationships
Answer: D.
33. Answer: F
Key words: aspects, fewest, believed, these, most important
Paragraph 5: “First he tested some assumptions about which aspects of the story alter least as it evolves, indicating their importance”. This sentence can be paraphrased into “he tested some assumptions about which aspects of the story had fewest alterations/variations, as this would indicate the most important aspects”.
There is a contrast between what folklorists believe and what Tehrani found. Still in paragraph 5, it is stated: “Folklorists believe that what happens in a story is more central to the story than the characters in it”, while we find in paragraph 6 that “Tehrani found no significant difference in the rate of evolution of incidents compared with that of characters”. This means that he found both incidents (what happens) and characters in a story change over time, not just the characters as suggested by folklorists. Thus, the answer should be something synonymous to ‘incidents’, which can only be B – ‘events’.
In paragraph 7, what was a “really big surprise” for Tehrani was that he found cautionary elements to be “just as flexible as seemingly trivial details” in “hunter-gatherer folk tales”.
This means that the elements which seem to provide cautionary, survival-relevant information may also be trivial, or unimportant, because they are not always fixed in the story. Although they may warn of “possible dangers” that may be faced in the environment, these parts of a story have surprisingly changed over time. Thus, the answer should be synonymous to ‘caution’ or ‘survival’. The most appropriate would be C – ‘warning’.
story = tale
unimportant = trivial
Answer: C.
36. Answer: G
Key words: aspect, most important, story’s survival
The end of paragraph 7 features a rhetorical question: “What, then, is important enough to be reproduced from generation to generation?”. If a story is “reproduced from generation to generation, this means that the story survives for a long time. The answer, which was previously thought to be cautionary information/warnings, is actually “fear” (paragraph 8). The stories which survive are usually “blood-thirsty and gruesome”, adjectives that we associate with horror and fear. Thus, the answer must be G – ‘horror’ because it has a similar meaning.
horror = fear
Answer: G.
37. Answer: B He looked at many different forms of the same basic story.
As mentioned in paragraph 4, Tehrani analysed 58 variants of two fairy tales in their oral form: “he ended up with 58 stories recorded from oral traditions”. Thus, the answer is clearly B, because these stories are variants of the same basic story. A is incorrect because he only examined oral stories; C is also incorrect as the stories are clearly related; D is not discussed in the passage.
Answer: B.
QUESTIONS 37-40: CHOOSE THE CORRECT LETTER, A, B, C OR D.
38. Answer: D features of stories only survive if they have a deeper significance
Key words: Tehrani’s views, Jack Zipes, suggests
By skimming the proper noun ‘Jack Zipes’, we can find his opinion in paragraph 9: “’Even if they’re gruesome, they won’t stick unless they matter”. Here, ‘gruesome’ is synonymous to ‘fearful, horrific’. Zipes argues that such gruesome features/details of fairy tales will not last long unless they have some meaning or significance in the story.
stick = survive
have significance = matter
Thus, the answer must be D.
Answer: D.
39. Answer: A to indicate that Jack Zipes’ theory is incorrect
Still in paragraph 9, Tehrani defends his idea against the view of Jack Zipes. Tehrani “points out that although this is often the case in Western versions, it is not always true elsewhere”. The case here refers to the opinion of Jack Zipes that all fairy tales have “the perennial theme of women as victims”. Tehrani shows that this theme is not present in Chinese and Japanese fairy tales, in which the woman is often actually the villain, instead of victim. Thus, Tehrani refers to these fairy tales to argue that Jack Zipes’ theory is incorrect.
Answer: A.
40. Answer: A They are a safe way of learning to deal with fear.
Key words: Mathias Clasen, believe
The last paragraph mentions Mathias Clasen’s belief: “scary stories teach us what it feels like to be afraid without having to experience real danger”. In other words, fairy tales let us learn about fear in a safer way (rather than experiencing real danger). The answer is therefore A.
The other answers are incorrect for the following reasons:
B is incorrect because “we seek out entertainment that’s designed to scare us”. This means humans seek out, not avoid, fairy tales with fearful details.
C is irrelevant. While it is mentioned that “’Habits and morals change”, Mathias Clasen does not say these are reflected in fairy tales.
D is incorrect because fairy tales with fearful features help us to “build up resistance to negative emotions”, thereby INCREASING (not REDUCING) our ability to deal with real-world problems.
PASSAGE 1: COULD URBAN ENGINEERS LEARN FROM DANCE ?
QUESTIONS 1- 6: READING PASSAGE 1 HAS SEVEN PARAGRAPHS, A-G.
1. Answer: B
Key words: way of using dance, not proposing
By using the skimming and scanning technique, we would find that before going into details about how engineers can learn from dance, the author first briefly mentions ways of using dance in paragraph B. The writer says: “That is not to suggest everyone should dance their way to work, …” to state his point that instead, we could learn from “the techniques used by choreographers”. Although dancing your way to work might be appealing, because it might make us “healthy and happy”, this is not the writer’s suggestion. Therefore, B is the answer.
Answer: B
2. Answer: C
Key words: contrast, past and present, building
In the passage, we should look for keywords that refer to the “past and present”, which are the time milestones of building approaches. These are found in paragraph C, where we find “medieval” and “now” in the same sentence; “medieval” describes those approaches of the “past”, and “now” refers to the “present”. Therefore, while builders in the past carried out construction through intimate knowledge and personal experience, building designers at present rely on media technologies, unfortunately detaching themselves from physical and social realities. Thus, C is the answer for this question.
past = medieval
present = now
Answer: C
3. Answer: F
Key words: objective, both, dance and engineering
By scanning, we could find that dance and engineering are both mentioned in paragraph F, so we would look here. It was stated that: “Yet it shares with engineering the aim of designing patterns of movement within limitations of space”, where “it” refers to “choreography” in the preceding sentence, and “aim” has the same meaning as “objective”. Therefore, it could be understood that both dance and engineering have the objective of “designing patterns of movement within limitations of space”, suggesting F as the answer for this question.
objective = aim
Answer: F
4. Answer: D
Key words: unforeseen problem, ignoring, climate
We could start by scanning and skimming for keywords that suggest “climate”, which we find in paragraph D. It is stated that: “They failed to take into account that …. cafes could not operate in the hot sun without …”, where the “hot sun” could be understood as a reference to climate, and “failing to take into account” is the same as “ignoring”. Moreover, in the last sentence, the author refers to the case as an “unexpected result”, which could also be translated into an “unforeseen problem”. Therefore, D is the answer.
ignore = fail to take into account
unforeseen = unexpected
Answer: D
5. Answer: E
Key words: measures, intended, help people, reserved
Several measures of building models are referred to in paragraph E, so we would investigate this one. After mentioning an example of “designs that seem logical in models appear counter-intuitive in the actual experience”, the writer further explains that the measures not only “make it harder to cross the road”, but also “divide communities and decrease opportunities for healthy transport”, and those are the reason why many are being “removed”. As being “removed” has the same meaning as being “reversed”, it is understood that some measures intended to help people are being reversed because of the reasons already mentioned. Therefore, E is the answer.
be reversed = be removed
Answer: E
6. Answer: A
Key words: impact, human lives
The impact of transport is described in paragraph A. Specifically, it is stated that: “The ways we travel affect our physical and mental health, our social lives, our access to work and culture, and the air we breathe”. Thus, “the ways we travel” is understood as “transport”, “affect” is the same as “have an impact on” and “our physical and mental health, our social lives, our access to work and culture, and the air we breathe” basically describes “human lives”. As a result, paragraph A conveys the same message as the statement, so A is the answer.
have an impact = affect
Answer: A
QUESTIONS 7-13: COMPLETE THE SUMMARY BELOW.
7. Answer: safety
Key words: Guard rails, improve, pedestrians, movement, not disrupted
In paragraph E, the guard rails are described as “an engineering solution to pedestrian safety …”; “pedestrian safety” could be rephrased as “the safety of pedestrians”. Therefore, “safety” is the answer for gap 7.
Moreover, the guard rails were based on models that “prioritise the smooth flow of traffic”, where the “smooth flow” could be understood as “movement” that is “not disrupted”, meaning that it also ensures the undisrupted movement of traffic. Thus, “traffic” should be filled in gap 8
movement = flow
Answer: safety – traffic.
8. Answer: traffic
Key words: Guard rails, improve, pedestrians, movement, not disrupted
In paragraph E, the guard rails are described as “an engineering solution to pedestrian safety …”; “pedestrian safety” could be rephrased as “the safety of pedestrians”. Therefore, “safety” is the answer for gap 7.
Moreover, the guard rails were based on models that “prioritise the smooth flow of traffic”, where the “smooth flow” could be understood as “movement” that is “not disrupted”, meaning that it also ensures the undisrupted movement of traffic. Thus, “traffic” should be filled in gap 8
movement = flow
Answer: safety – traffic.
9. Answer: carriageway
Key words: access points, one at a time
Paragraph E states that access points are used to divide the crossing into two, and there is one of these access points, “one for each carriageway”, in order to encourage pedestrians to slow down by crossing each one at a time. As a result, what pedestrians are encouraged to cross one” at a time”, here, is the carriageway. Therefore, “carriageway” is filled in the gap.
Answer: carriageway
10. Answer: mobile
Key words: unintended, psychological difficulties, less
The “psychological barriers” are mentioned in paragraph E as an effect of the guard rails, and they “greatly impact those that are the least mobile”, suggesting that psychological difficulties are unintentionally created for less mobile people. Therefore, “mobile” is the answer here.
difficulties = barriers
Answer: mobile
11. Answer: dangerous
Key words: cross the road, way
The guard rails are also observed to “encourage others to make dangerous crossings”. As “making crossings” is the same as the act of “crossing”, “dangerous” is the adjective that describes this action of crossing the road. Thus, the blank should be filled with “dangerous”.
cross = make crossings
Answer: dangerous
12. Answer: communities
Key words: separate, difficult, introduce
The drawbacks of guard rails are mentioned near the end of paragraph E, showing that they “divide communities and decrease opportunities for healthy transport”. As “divide” has the same meaning as “separate”, the noun that should be filled in gap 12 is “communities”. Moreover, to “decrease opportunities” could be understood as to “make it more difficult”, which means making it hard to introduce healthy forms of transport. Therefore, “healthy” should be filled in gap 13.
separate = divide
Answer: communities – healthy
13. Answer: healthy
Key words: separate, difficult, introduce
The drawbacks of guard rails are mentioned near the end of paragraph E, showing that they “divide communities and decrease opportunities for healthy transport”. As “divide” has the same meaning as “separate”, the noun that should be filled in gap 12 is “communities”. Moreover, to “decrease opportunities” could be understood as to “make it more difficult”, which means making it hard to introduce healthy forms of transport. Therefore, “healthy” should be filled in gap 13.
separate = divide
Answer: communities – healthy
PASSAGE 2: SHOULD WE TRY TO BRING EXTINCT SPECIES BACK TO LIFE ?
QUESTIONS 14 -17: WHICH PARAGRAPH CONTAINS THE FOLLOWING INFORMATION?
14. Answer: F
Key words: disappearance, avoided
While most paragraphs are about bringing back extinct species, only paragraph F mentions how extinction could be avoided in the first place. It is stated that it is “far easier to save an existing species which is merely threatened with extinction”, and this could be achieved specifically by making “genetic modifications which could prevent mass extinctions in the future”. In this sentence, “prevent” could be understood as “avoid”. In mass extinctions, many/multiple species disappear/become extinct. Therefore, paragraph F contains the message that matches this statement, so F is the answer.
avoid = prevent
→ Answer: F
15. Answer: A
Key words: explanation, reproducing, using DNA
By using the scanning and skimming technique, in paragraph A we could find the details of how DNA could be used to reproduce extinct animals. Specifically, it is stated that “the basic premise involves using cloning technology to turn the DNA of extinct animals into a fertilised embryo, which is carried by the nearest relative still in existence …”, meaning that this is an explanation of the mechanism of the technology. Therefore, A is the answer.
reproduce = clone
→ Answer: A
16. Answer: D
Key words: habitat, suffered, following the extinction
The purposes of bringing back extinct species are mentioned in paragraph D, where one of the reasons is to repair damage to ecosystems. Specifically, it is stated that “Since the disappearance of this key species (passenger pigeons), ecosystems in the eastern US have suffered….”, in which “ecosystems” refers to “habitat”. Therefore, D is the answer.
habitat = ecosystems
→ Answer: D
17. Answer: A
Key words: exact point, particular species, extinct
As the “exact point” might refer to an exact time or date, we could use the skimming and scanning technique and find in paragraph A the particular date for the extinction of the passenger pigeon, which “came to an end on 1 September 1914, when the last living specimen died…” As “come to an end” is the same as “become extinct”, it is confirmed that A is the answer.
become extinct = come to an end
→ Answer: A
QUESTIONS 18 – 22: COMPLETE THE SUMMARY BELOW.
18. Answer: genetic traits
Key words: George Church, mammoths, tundra
In paragraph E, the team is focusing on reaching its goal by “pinpointing which genetic traits made it possible for mammoths to survive the icy climate of the tundra”.
identify = pinpoint
enable = make it possible
live = survive
Therefore, the subject that Professor George Church and his team are trying to identify ís the “genetic traits”, which should be filled in gap 18.
→ Answer: genetic traits
19. Answer: heat loss
Key words: Church, Asian elephants, physical adaptations, minimise
In the same paragraph, it is stated that in order to expand the range of Asian elephants to the tundra, there would be multiple necessary physical adaptations that are “all for the purpose of reducing heat loss in the tundra”.
minimise = reduce
Therefore, certain physical adaptations are aimed at minimising “heat loss”, which are the missing words in gap 19.
→ Answer: heat loss
20. Answer: ears
Key words: mammoth-like features
As mentioned earlier, multiple adaptations are necessary for the elephant to survive in the tundra, including “smaller ears, thicker hair, and extra insulation fat”, which are traits found in the woolly mammoth.
reduced size = smaller
more = extra
Therefore, the adaptations can be rewritten as “ears” of reduced size and more “insulation fat”. Thus, “ears” and “insulation fat” are respectively filled in gaps 20 and 21.
→ Answer: ears – (insulating) fat
21. Answer: (insulating) fat
Key words: mammoth-like features
As mentioned earlier, multiple adaptations are necessary for the elephant to survive in the tundra, including “smaller ears, thicker hair, and extra insulation fat”, which are traits found in the woolly mammoth.
reduced size = smaller
more = extra
Therefore, the adaptations can be rewritten as “ears” of reduced size and more “insulation fat”. Thus, “ears” and “insulation fat” are respectively filled in gaps 20 and 21.
→ Answer: ears – (insulating) fat
22. Answer: (carbon) emissions
Key words: repopulating, environment
In paragraph E, the repopulation of the tundra with large mammals (which refers to mammoths and Asian elephants) might encourage grass growth, which would “reduce temperatures, and mitigate emissions from melting permafrost”.
Thus, it means that repopulating the tundra could help decrease “emissions”, or specifically “carbon emissions” in the preceding sentence. Therefore, “(carbon) emissions” is the answer.
decrease = mitigate
→ Answer: (carbon) emissions
QUESTIONS 23 – 26: LOOK AT THE FOLLOWING STATEMENTS (QUESTIONS 23-26) AND THE LIST OF PEOPLE BELOW.
23. Answer: B
Key words: reproducing an extinct species, improve, particular species
Among multiple benefits from reintroducing an extinct species, one of them, which is improving the health of a particular species living in a certain area (the island of Tasmania) is mentioned in paragraph B. Specifically, Michael Archer refers to the example of how the reintroduction of the thylacine would have helped the Tasmanian devils avoid the threats from the facial tumour syndrome, which dangerously affects their health. Therefore, B is the answer here,
→ Answer: B
24. Answer: C
Key words: concentrate, causes
By skimming and scanning, we can find the emphasis on finding the causes of an animal’s extinction in paragraph F. Particularly, Beth Shapiro prefers to “fully understand why various species went extinct in the first place”, where “understand why” could be understood as “concentrate on the causes”. Therefore, C is the answer.
→ Answer: C
25. Answer: A
Key words: beneficial impact, vegetation
By looking for keywords that relate to “vegetation”, we could find the idea of this statement in paragraph D. Since the extinction of a species – the passenger pigeon – the forests where they used to live have become “stagnant”. Ben Novak explains how the return of the passenger pigeons to their forest habitat, with their nesting habits, would help “re-establish that forest disturbance, thereby creating a habitat necessary for a great many other native species to thrive”. As the “forest disturbance” conveys the same meaning as “impact on the vegetation”, it is once again confirmed that this statement is the idea of Ben Novak. Therefore, A is the answer.
“Preserving biodiversity” could be understood as preventing extinction in the first place, which is the idea of paragraph F, so we would look in this one. In this paragraph, Shapiro expresses how it is “far easier to try to save an existing species …”, and commented that “we know that what we are doing today is not enough” for this act of preserving biodiversity.
current = today
insufficient = not enough
Therefore, this is the statement of Beth Shapiro, so C is the answer.
→ Answer:
PASSAGE 3: HAVING A LAUGH
QUESTIONS 27 – 31: CHOOSE THE CORRECT LETTER, A, B, C OR D.
27. Answer: C its value to scientific research
Keywords: first paragraph, language, human culture, scientific research, universality, animal societies
In paragraph 1, laughter is said to “provide psychological scientists with rich resources for studying human psychology”, which is an emphasis on its value. Although the relationship between laughter and the development of language is mentioned, this is only one part of its value to scientific research. The main point is that as the “study of human psychology” is a part of “scientific research”, we could infer that the value of laughter to scientific research in general is emphasised in paragraph 1. Therefore, C is the answer.
→ Answer: C
28. Answer: A He understood the importance of enjoying humour in a group setting
Keywords: Charley Douglass, group setting, TV viewers, social spectrum, recording studio
Charley Douglass is mentioned in paragraph 2, so we would look in this one. It is stated that Douglass recorded “laugh tracks” with the intention to “help people at home feel like they were in a social situation such as a crowded theatre”. As such, it could be understood that he had realized that people would enjoy humour more in a “social situation”, or in other words, in a “group setting”. Therefore, A is the answer.
group setting = social situation
→ Answer: A
29. Answer: B the similar results produced by a wide range of cultures
Keywords: Santa Cruz, different, cultures, academic disciplines, recorded
Santa Cruz is mentioned in paragraph 3, which describes a study made up of 30 people listening to the reaction to recorded laughter of people from 24 diverse societies, representing a wide range of cultures, “…from indigenous tribes in New Guinea to city-dwellers in India and Europe”. The result was that people’s guesses were correct about 60% of the time worldwide, meaning that the outcome was similar for diverse cultures that were involved in the study. Thus, B is the answer.
a wide range of cultures = diverse societies
→ Answer: B
30. Answer: B Participants exchanged roles.
Keywords: San Diego, upset, exchanged roles, friends, unable
A study from San Diego is described in paragraph 4. The words in the passage: “each student in the study” refers to the participants. In the study, specifically, participants “took a turn at being teased by the others”. As the act of “taking a turn” means that participants “exchange roles” with each other, statement B shows how the study was conducted, so B is the answer.
→ Answer: B
31. Answer: D High-status individuals can always be identified by their way of laughing
At the end of paragraph 5, it is stated that “high-status individuals were rated as high-status whether they produced their natural dominant laugh or tried to do a submissive one”. It can then be understood that, with whatever their way of laughing, the high-status individuals were always identified. As a result, D is the answer.
→ Answer: D
QUESTIONS 32 – 36: COMPLETE THE SUMMARY USING THE LIST OF WORDS, A-H, BELOW.
32. Answer: F
Key words: Australian National University, three videos, different kind
A study conducted by researchers from Australian National University is explained in paragraph 6. In the study, participants were assigned to watch randomly one of three videos, which “elicit either “humour, contentment, or neutral feelings”.
generate = elicit
emotion = feelings
Therefore, the videos were designed to generate different kinds of emotion, so F is the answer.
→ Answer: F
33. Answer: H
Key words: persisted, tried harder
The result of the study is revealed in paragraph 7. After watching one of the videos, the groups were given a second task “requiring persistence”. It was found that those who watched the Mr. Bean video ended up persisting with the task longer (“spending significantly more time working on the task”) and tried harder (“making twice as many predictions as the other two groups”). Among the given words, “amusing” best describes the Mr. Bean video, so H is the answer.
→ Answer: H
34. Answer: C
Key words: second study, similar results
Paragraph 8 describes the second study, in which participants had to “complete long multiplication questions by hand”, and the result was quite similar to that of the previous one, in which those who watched the humorous video persisted longer and tried harder. Of the words that we were given, the task that the participants were given is best described as being “boring”. Therefore, C is the answer.
→ Answer: C
35. Answer: D
Key words: David Cheng, Lu Wang, reduces, body and mind
In the last paragraph, Cheng and Wang conclude that humour helps “relieve stress” and that it is “energising”.
reduce = relieve
stimulating = energising
As a result, D and E are to be filled in gap 35 and 36 respectively
→ Answers: D – E
36. Answer: E
Key words: David Cheng, Lu Wang, reduces, body and mind
In the last paragraph, Cheng and Wang conclude that humour helps “relieve stress” and that it is “energising”.
reduce = relieve
stimulating = energising
As a result, D and E are to be filled in gap 35 and 36 respectively
→ Answers: D – E
QUESTIONS 37 – 40: DO THE FOLLOWING STATEMENTS AGREE WITH THE CLAIMS OF THE WRITER IN READING PASSAGE 3?
37. Answer: NOT GIVEN
Key words: Santa Cruz, more accurate, friends, strangers
The study at the University of California at Santa Cruz is found in paragraph 3. The result was that participants were accurate for about 60% of the time at guessing whether the people laughing were friends or strangers, but it is not stated what percentage were correct at guessing laughs of friends and how many of guessing laughs of strangers. Therefore, the validity of the statement cannot be identified, so NOT GIVEN is the answer.
→ Answer: NOT GIVEN
38. Answer: YES
Key words: San Diego, predictions, high-status individuals
The San Diego study is described in paragraph 4, which states that the result was “as expected, high-status individuals produced more dominant laughs and fewer submissive laughs relative to the low-status individuals”.
predict = expect
Therefore, it is understood that what the researchers expected about high-status individuals was correct, so we shall say YES to this statement.
→ Answer: YES
39. Answer: NO
Key words: Australian National University, fixed, time, employee profiles
The study from Australian National University described in paragraphs 6 and 7 was conducted with participants guessing “the potential performance of employees based on provided profiles, and they “were allowed to quit the task at any point”. Therefore, the amount of time given was not fixed, so the answer is NO for this statement.
→ Answer: NO
40. Answer: NO
Key words: Cheng and Wang, in line, task performance
In the last paragraph, Cheng and Wang mentioned the “traditional view” that “individuals should avoid things such as humour that may distract them from the accomplishment of task goals”. However, the result of the study was that those who watched the humorous video persisted longer and tried harder to perform the task. This result is not at all in line with the established notion or traditional idea. Therefore, the answer for this statement is NO.
QUESTIONS 1- 4: COMPLETE THE NOTES BELOW. CHOOSE ONE WORD ONLY FROM THE PASSAGE FOR EACH ANSWER.WRITE YOUR ANSWER IN BOXES 1-8 ON YOUR ANSWER SHEET.
1. Answer: oval
Key words: leaves, shape
Using the scanning skill, we can see that the first paragraph describes the characteristics of the tree in detail, including the leaves, so we would pay attention to this paragraph. It can be seen in the 2nd sentence: “The tree is thickly branched with […], dark green oval leaves, […]” referring first to the colour, and then to the shape, stating that the leaves are oval. Therefore, “oval” is the answer.
2. Answer: husk
Key words: surrounds, fruit, open, ripe
Similarly, fruit is another feature of the tree, so we would still look into in paragraph 1. There are two sentences mentioning fruit: “The fruit is encased in a fleshy husk. When the fruit is ripe, this husk splits into two halves along a ridge running the length of the fruit.” To be “encased” in something” is to be covered completely by something, so it can be understood the other way around that a “fleshy husk” surrounds the fruit. Moreover, “splitting into two halves” is a simple image of “breaking open”, so it is once again confirmed that “husk” is the answer.
to surround = to encase
to break = to split
Answer: husk
3. Answer: seed
Key words: produce, spice nutmeg
Although the nutmeg is mentioned in both paragraph 1 and 2, butparagraph 2 is focused on the historical application of the nutmeg, not theorigin different parts of the plant, so we would once again pay attention to paragraph 1. The spice nutmeg is brought up in the last sentence: “These are the sources of the two spices nutmeg and mace, the former being produced from the dried seed and the latter from the aril.” As “the former” refers to the subject that was mentioned first, which, in this case, is the “spices nutmeg”, it can be inferred that the spices nutmeg is produced from the dried seed, revealing the answer to be the “seed”.
Answer: seed
4. Answer: mace
Key words: covering, aril, produce
In We find the answer to this question in the same last final sentence thatof paragraph 1 that we look into in found the answer to question 3. “The latter” refers to the subject spice that was mentioned later after nutmeg, which is the “mace”. The previous sentence explains the meaning of the word ‘aril’, which is the red covering surrounding the seed. Note that the key word ‘covering’ is mentioned here. Therefore, it can be understood that the mace is produced from the aril, confirming that our answer is the“mace”.
Answer: mace
QUESTIONS 5 – 7: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
5. Answer: FALSE
Key words: Middle Ages, Europeans, knew, grown
Through scanning, we can see that the Middle Ages period is mentioned in paragraph 2, so we would look into this one. “Arabs were the exclusive importers of the spice to Europe”, so it can be understood that they are the only people getting having access to the source of the nutmeg. Moreover, “they never revealed the exact location of the source”, which means that no Europeans, other than the Arabs, know the source of the nutmeg, which is where it was grown. Therefore, this statement is false.
→ Answer: FALSE
6. Answer: NOT GIVEN
Key words: VOC, first, major trading
As the VOC was mentioned only in paragraph 4, this paragraph would be investigated. In this statement, the word “first” refers to the idea that there was no major trading company before the VOC. However, there was no sentence mentioning this; the only sentence emphasizing the position ofdescribing the VOC is that it is was the “richest commercial operation in the world”. not “the first”. We do not know if it was the first trading company, only that it was rich. Therefore, it is not given to confirm whether this statement is true or false. we have no information to confirm if the statement is true or false.
trading company = commercial operation
→ Answer: NOT GIVEN
7. Answer: TRUE
Key words: following, Treaty of Breda, Dutch, control, all, where nutmeg grew
By using the scanning technique, we can see that the Treaty of Breda is brought up referred to in paragraph 5, which mentions how the Dutch and British arrived at the settlement and what happened afterwards. The paragraph shows that the Dutch managed to be “securely in control of the Bandas”, where all nutmeg production was concentrated into easily guarded areas, and “there was no chance a fertile seed which could be grown elsewhere would leave the islands”. which This means that the Banda Islands were the sole islands that where nutmeg grew in, and the Dutch is were fully in control of those, except for only the island of Run. However, through the Treaty of Breda, the ownership of this island of Run was also transferred to the Dutch. Therefore, after the Treaty of Breda, it is true that all the islands where nutmeg grew are were under the control of the Dutch.
→ Answer: TRUE
QUESTIONS 8 -13: COMPLETE THE TABLE BELOW. CHOOSE ONE WORD ONLY FROM THE PASSAGE FOR EACH ANSWER. WRITE YOUR ANSWERS IN BOXES 8-13 ON YOUR ANSWER SHEET.
8. Answer: arabs
Key words: Middle Ages, brought to, Europe
We would look into paragraph 2 where the Middle Ages period was brought up is mentioned. As mentioned, Here, it is stated that “throughout this period, the Arabs were the exclusive importers of the spice to Europe”, which means that the Arabs were the only people that brought nutmeg to Europe in the Middle Ages. Therefore, “Arabs” is the answer here.
→ Answer: Arabs
9. Answer: plague
Key words: 17th century, disease
The 17th century starts from 1600, so we would look into where this period was first mentioned – paragraph 4. In this paragraph, a disease that was called “the plague” was mentioned, which was doctors decided tocould be cured by nutmeg, making everyone want it at the time. Therefore, “plague” is the answer for question 9.
→ Answer: plague
10. Answer: lime
Key words: 17th century, Dutch, avoid, outside, obtained, British
The information on the Dutch protecting its monopoly position wasbrought up is given in paragraph 5. It mentions that “all exported nutmeg was covered with lime to make sure there was no chance a fertile seed which could be grown elsewhere would leave the islands”. It could then be understood that to avoid fertile seed being grown – or cultivated – outside the islands, the Dutch had used lime cover nutmeg, or in other words, put lime on nutmeg. Therefore, “lime” is the answer to question 10. Additionally, was We can now find the answer to question 11. It is mentioned that although the Dutch was were in control of the Banda Islands, one of them islands – called Run – was under the control of the British. which was called Run. After the trade exchange offered by the Dutch, the British gave the island of Run to them. It can therefore be said that the Dutch finally obtained the island of Run from the British.
cultivated = grown
→ Answers: lime – Run
11. Answer: run
Key words: 17th century, Dutch, avoid, outside, obtained, British
The information on the Dutch protecting its monopoly position is given in paragraph 5. It mentions that “all exported nutmeg was covered with lime to make sure there was no chance a fertile seed which could be grown elsewhere would leave the islands”. It could then be understood that to avoid fertile seed being grown – or cultivated – outside the islands, the Dutch used lime to cover nutmeg, or in other words, put lime on nutmeg. Therefore, “lime” is the answer to question 10. We can now find the answer to question 11. It is mentioned that although the Dutch were in control of the Banda Islands, one of the islands – called Run – was under the control of the British. After the exchange offered by the Dutch, the British gave the island of Run to them. It can therefore be said that the Dutch finally obtained the island of Run from the British.
cultivated = grown
→ Answers: lime – Run
12. Answer: mauritius
Key words: 1770, secretly taken
As 1770 was is mentioned in paragraph 6, we would investigate this paragraph. It states that: “a Frenchman … smuggled nutmeg plants to safety in Mauritius”. “Smuggle” means to steal or to take something secretly, so this is the piece of information we are looking for. Therefore, Mauritius is our answer to question 12.
secretly taken = smuggle
→ Answer: Mauritius
13. Answer: tsunami
Key words: 1778, half, Banda Islands, destroyed
An event in 1778 was is mentioned in paragraph 6: “a volcanic eruption in the Banda region caused a tsunami that wiped out half the nutmeg groves”. “Wipe out” has the same meaning with as “destroy”, and it can be understood that the tsunami is was the direct cause of this event. Therefore, tsunami is the missing word here.
destroy = wipe out
→ Answer: tsunami
PASSAGE 2: DRIVERLESS CARS
QUESTIONS 14 -18: READING PASSAGE 2 HAS SIX PARAGRAPHS, A-G. WHICH PARAGRAPH CONTAINS THE FOLLOWING INFORMATION?
14. Answer: C
Key words: time, not in use
Paragraph C states that: “At present, the average car spends more than 90 percent of its life parked”. In this context, “parked” means that the car is turned off stationary and not in use, which means that the amount of time referenced referred to is 90% of the car’s life. Therefore, the answer is C.
→ Answer: C
15. Answer: B
Key words: advantages, individual road-users
While several paragraphs mention the advantages of driverless vehicles, most are about the effects on the large society as a whole, and only paragraph B mentions the pros for individual road-users. Specifically, the author shows how the technology could reduce road collisions involving human error and free the time people spend on driving. Therefore, the answer is B.
→ Answer: B
16. Answer: E
Key words: opportunity, appropriate vehicle, each trip
Paragraph E states that: “If […], drivers will have the freedom to select one that best suits their needs for a particular journey, […]”
best suit = appropriate
each trip = particular journey
The author then explains that consumers could see this happen by purchasing access to a range of vehicles, to suit their particular individual needs for exceptional journeys such as a family camping trip. through a mobility provider, which is an opportunity through changes in vehicle manufacture. Therefore, the answer is E.
→ Answer: E
17. Answer: G
Key words: how long, overcome, problems
The hurdles are mentioned in the last two paragraphs, where paragraph F brings up specific difficulties, and paragraph G shows the potentiality to overcome those problems. Paragraph G states that “It’s clear that there are many challenges that need to be addressed, but … these can most probably be conquered within the next 10 years.”
problems = challenges
overcome = conquer
It could then be inferred that 10 years is the estimate of how long it will take to overcome a number of problems. Therefore, the answer is G.
→ Answer: G
18. Answer: D
Key words: no effect, number, vehicles manufactured
Paragraph D first begins with “… it might mean that we need to manufacture far fewer vehicles to meet demand.” However, in However, the author states that although fewer cars might be used, they would be “…used more intensively, and might need replacing sooner. At the end, it states is stated that: “This faster rate of turnover may mean that vehicle production will not necessarily decrease”. Therefore, it is suggested from this paragraph that the number of vehicles manufactured might not decrease as calculated in the beginning, meaning that the use of driverless cars may have no effect on this. Hence, the answer is D.
→ Answer: D
QUESTIONS 19 – 22: COMPLETE THE SUMMARY BELOW. CHOOSE NO MORE THAN TWO WORDS FROM THE PASSAGE FOR EACH ANSWER.
19. Answer: human error
Key words: Transport Research Laboratory, motor accidents, due to
Paragraph B states that: “…, research at the UK’s Transport Research Laboratory has demonstrated that more than 90 percent of road collisions involve human error as a contributory factor, and it is the primary cause in the vast majority”.
motor accidents = road collisions
It can then be inferred that most motor accidents are partly due to human error. Therefore, “human error” is the answer for question 19.
→ Answer: human error
20. Answer: car (-) sharing
Key words: schemes, workable
Benefits that are beyond direct ones, such as greater safety, are mentioned in paragraph C. It states that: “Automation means that initiatives for car-sharing become much more viable, …”
schemes = initiatives
workable = viable
It can therefore be understood that automation would make car-sharing more workable, suggesting “car-sharing” as the answer for this question.
→ Answer: car (-) sharing
21. Answer: ownership
Key words: University of Michigan Transportation Research Institute, 43 percent drop, cars
This piece of information is specifically mentioned in paragraph D: “Modelling work by the University of Michigan Transportation Research Institute suggests automated vehicles might reduce vehicle ownership by 43 percent, …”
drop = reduce
cars = vehicles
Thus, the answer here is “vehicle ownership”.
→ Answer: ownership
22. Answer: mileage
Key words: yearly, twice as high
In the same sentence mentioned above in paragraph D, it is describedstated that “… vehicles’ average annual mileage would double as a result.” As “annual” is the same as “yearly”, the answer to question 22 is “mileage”.
yearly = annual
twice as high = double
→ Answer: mileage
QUESTIONS 23 – 24: CHOOSE TWO LETTERS, A – E. WRITE THE CORRECT LETTERS IN BOXES 23 AND 24 ON YOUR ANSWER SHEET.
Questions 23-24: C Travellers could spend journeys doing something other than driving., D People who find driving physically difficult could travel independently.
Key words: benefits
Cost savings and pollution are not mentioned anywhere in the passage, so A and E is are incorrect. Moreover, parking is only brought up in paragraph C, where the main idea is that the average car spends most of its life parked, so B is also incorrect.
In paragraph B, one of the advantages is described as “Another aim is to free the time people spend driving for other purposes”, meaning that instead of driving, travellers could spend the time on something else. Thus, C is correct.
In the same paragraph, people who find driving physically difficult, who are mentioned to be referred to as “those who are challenged by existing mobility models”, are said to “be able to enjoy significantly greater travel autonomy”. As autonomy can be understood as independence, D is correct.
travel independently = travel autonomy
→ Answers: C & D
QUESTIONS 25 – 26: CHOOSE TWO LETTERS, A – E. WRITE THE CORRECT LETTERS IN BOXES 25 AND 26 ON YOUR ANSWER SHEET.
Questions 25-26: A making sure the general public has confidence in automated vehicles , E getting automated vehicles to adapt to various different driving conditions
Key words: challenges
The hurdles are easily found in paragraph F.
As the pace of transition, professional drivers compensation and infrastructure are not mentioned anywhere, B, C and D are incorrect.
It is stated that In paragraph F, the text refers to “… the societal changes that may be required for communities to trust and accept automated vehicles …” In this context, “communities” can be understood as the “general public”, and “trust and accept” is the same as “have confidence”. Therefore, making sure that the general public has confidence in automated vehicles is one of the challenges that automated vehicle development meets, so A is correct.
Paragraph F also tells that there are: “… technical difficulties in ensuring that the vehicle works reliably in the infinite range of traffic, weather and road situations it might encounter.” As “infinite” can also be expressed as “various”, and “range of traffic, weather and road situations” is also “different driving conditions”, this sentence expresses the same idea as E. Thus, E is correct.
general public = communities
have confidence = trust and accept
various = infinite
Answers: A & E
PASSAGE 3: WHAT IS EXPLORATION
QUESTIONS 27 – 32: CHOOSE THE CORRECT LETTER, A, B, C OR D. WRITE THE CORRECT LETTER IN BOXES 27-32 ON YOUR ANSWER SHEET.
27. Answer: A exploration is an intrinsic element of being human.
Key words: New York, intrinsic, enthusiastic, surprising results, daunting
Visitors to New York were mentioned in the first paragraph as an example for the statement preceding it: “This questing nature of ours undoubtedly helped our species spread around the globe”, where “questing” is the same as “exploring” and “nature” refers to the “intrinsic element”. This example then illustrates how exploring, as an intrinsic element of human nature or behaviour, helps a visitor find directions in subways of a strange city like New York. Therefore, A is the answer.
exploring = questing
intrinsic element = nature
Answer: A
28. Answer: C They act on an urge that is common to everyone.
Key words: second paragraph, benefits and disadvantages, teaching, common, certain professions
Paragraph 2 starts by stating people’s assumption that explorers are odd (peculiar = odd/strange), and that there is a type of person more suited for exploring, so we might be inclined to choose answer D. However, eventually, the author counters that idea by asserting that “we all have this enquiring instinct”. “Instinct” here can be understood as “urge”, and the fact that “we all have” means that it is “common to everyone”. It can then be inferred that the exploring urge, in other words the desire to explore, is common to everyone, so the answer is C.
urge = instinct
Answer: C
29. Answer: C Hardy’s aim was to investigate people’s emotional states.
In paragraph 3, it is stated that the Egdon Heath landscape was used to “suggest the desires and fears of his Thomas Hardy’s characters.” Hereby The words “desires and fears” can be generally called “emotional states”. In other words, the description of Egdon Heath is used to show the emotional states of his characters, which who are later referred to as “humanity”, understood as “people”. Therefore, we could infer that the answer is C.
people = humanity
Answer: C
30. Answer: D we are wrong to think that exploration is no longer necessary.
Key words: fourth paragraph, golden age, useful information, decreased, fewer, interested, less exciting, wrong, no longer necessary
Paragraph 4 begins by stating that: “the word ‘explorer’ has become associated with a past era”, which expresses the idea that exploring is perceived to be important only in the past but not the present. This ‘golden age’ is widely considered to be the 19th century, but now exploration has declined. Following are multiple The following “as if” statement s to show a sense of disagreement shows that the writer disagrees with this idea. Moreover, the The author continues with the number that shows argues that we have only studied 5% of the species we know, which conveys that there is still a huge space area of knowledge to explore, implying a counter argument against the idea that exploring is no longer necessary at present. Therefore, D is the answer.
Answer: D
31. Answer: A people tend to relate exploration to their own professional interests
Key words: definition, own professional interested, misunderstand, changed, historians and scientists, more value
The first sentence in paragraph 6 clearly states that: “Each definition is slightly different – and tends to reflect the field of endeavour of each pioneer.” Hereby, The word “definition” can be understood as how each person relates to the subject mentioned meaning of the word ‘exploration’, and “field of endeavour” is also “professional interest”. Therefore, it can be understood as the idea that each person would relate exploration to his own professional interests. As a result, A is the answer.
interest = endeavour
Answer: A
32. Answer: B the human ability to cast new light on places that may be familiar.
Key words: last paragraph, personality, choice of places, human ability new light, travel writing, evolve, changing demands feelings
In the last paragraph, the author states what interests him in the last sentence: “how a fresh interpretation, even of a well-travelled route, can give its readers new insights.” “Giving new insight” or a “fresh interpretation” could here be understood as the act of “casting new light” on something, and being “well-travelled” means that the route is seen as “familiar”. Thus, it might be inferred that the author is interested in how new light could be cast on places that are familiar, so the answer is B.
cast new light on = give new insight
Answer: B
QUESTIONS 33 – 37: LOOK AT THE FOLLOWING STATEMENTS (QUESTIONS 33-37) AND THE LIST OF EXPLORERS BELOW.MATCH EACH STATEMENT WITH THE CORRECT EXPLORER, A-E
33. Answer: E
Key words: form of transport
The types of transport are brought up in paragraph 5 in the sayingstatement: “If I’d gone across by camel when I could have gone by car, it would have been a stunt”, where “camel” and “car” are the different forms of transport used. This is said by Wilfred Thesiger, so E is the answer.
Answer: E
34. Answer: A
Key words: feeling, coming back home
Back to paragraph 3, Peter Fleming “talks of the moment when the explorer returns to the existence he has left behind with his loved ones”. In this context, “the existence he has left behind” shall be understood as the “home” he has left for in order to undertake the journey, and “talking of the moment” might refer to the act of “describing feelings”. Therefore, it can be inferred that Peter Fleming described feelings on coming back home after a long journey, so the answer is A.
Answer: A
35. Answer: D
Key words: benefit, specific groups of people
In paragraph 5, specific groups of people were brought up referred to as “‘tribal’ people”, of for whom Robin Hanbury-Tenison worked on behalf as a campaigner. In other words, Robin Hanbury-Tenison was said to work for the benefit of specific groups of people, so D is the answer here.
Answer: D
36. Answer: E
Key words: not essential, learning about oneself essential
The last sentence in paragraph 5 states that to Wilfred Thesiger, “exploration meant … regardless of any great self-discovery.” The word “regardless” here shows that “self-discovery”- which could be understood as “learning about oneself” – is not an essential part of exploration. Therefore, the statement in this question is the idea of Wilfred Thesiger, suggesting E as the answer.
learning about oneself = self-discovery
Answer: E
37. Answer: B
Key words: unique, of value
The first explorer mentioned in paragraph 5, Ran Fiennes, said that “An explorer is someone who has done something that no human has done before – and also done something scientifically useful”; there are two phrases we could look into here. “Something that no human has done before” is the description of something that is “unique”, and “something scientifically useful” is something “of value”. Therefore, Ran Fiennes is the one that has the definition of exploration as described in the statement, suggesting that B is the answer.
Answer: B
QUESTIONS 38 – 40: COMPLETE THE SUMMARY BELOW. CHOOSE NO MORE THAN TWO WORDS FROM THE PASSAGE FOR EACH ANSWER.
38. Answer: (unique) expeditions
Key words: large number, first stranger, encountered
The author states that: “I’ve done a great many expeditions and each one was unique”. As “a great many” is the same as “a large number of”, the noun that we would fill in the first gap (38) should be “expeditions”. Moreover, the described adjective “unique” used in the passage could also be added, making our full answer “(unique) expeditions”.
Moreover, the writer had also “lived for months alone with isolated groups of people all around the world, even two ‘uncontacted tribes’”. As “uncontacted tribes” refers to those who might have never encountered any person outside theirs own isolated group, the writer could have been the first one to make contact with them, so the answer shall be is either “uncontacted” (to be specific) or “isolated” in general.
a large number = a great many
Answer: (unique) expeditions
39. Answer: uncontacted / isolated
Key words: large number, first stranger, encountered
The author states that: “I’ve done a great many expeditions and each one was unique”. As “a great many” is the same as “a large number of”, the noun that we would fill in the first gap (38) should be “expeditions”. Moreover, the described adjective “unique” used in the passage could also be added, making our full answer “(unique) expeditions”.
Moreover, the writer had also “lived for months alone with isolated groups of people all around the world, even two ‘uncontacted tribes’”. As “uncontacted tribes” refers to those who might have never encountered any person outside theirs own isolated group, the writer could have been the first one to make contact with them, so the answer shall be is either “uncontacted” (to be specific) or “isolated” in general.
a large number = a great many
Answer: uncontacted/isolated
40. Answer: (land) surface
Key words: no need, further exploration
The writer first says that “the time has long passed for the great continental voyages”, and the reason is that “we know how the land surface of our planet lies; exploration of it is now down to the details”, and that “it’s the era of specialists”. It could therefore be inferred that the author believes there is no need for further exploration of the “land surface”, as the mechanism it is now known and there are more specialists to explore the details of it. Thus, “land surface” shall be is the answer for question 40.
Explain – Key words: focused age groups, ants – In paragraph 3, it is stated that “Giraldo focused on ants at four age ranges”, so the answer must be “four/4”.
2. ANSWER: YOUNG
Explain – Key words: how well, ants, looked after – The first sentence of paragraph 4 states that “Giraldo watched how well the ants took care of the young of the colony” – Look after = take care of
3. ANSWER: FOOD
Explain – Key words: ability, locate, scent trail – In the second sentence of paragraph 4, the author mentions how ants “followed the telltale scent that the insects usually leave to mark a trail to food”. This means that she studied ants‟ ability to locate food using a scent trail.
4. ANSWER: LIGHT
Explain
Key words: effect
In the same paragraph, we are told that “she tested how ants responded tolight”, meaning that she tested the effect of “light” on ants
5. ANSWER: AGGRESIVELY
Explain – Key words: attacked, prey – Still in paragraph 4, Giraldo compared the way old and young ants attacked their prey and found that the old ones attacked “just as aggressively” as the young ones did. In other words, she studied how aggressively they attacked the prey.
6. ANSWER: LOCATION
Explain – Key words: comparison, age, dying, cells, brains – In paragraph 5, we know that Giraldo didn‟t find any major difference in age and the location of dying brain cells between 20-day-old and 95-day-old ants. This suggests that she compared between the age and location of dying cells.
7. ANSWER: NEURONS
Explain – Key words: synaptic, complexes, brain‟s, mushroom bodies – In paragraph 5, it is stated that synaptic complexes are “regions where neurons come together”
8. ANSWER: CHEMICALS
Explain – Key words: two, brain, associated, ageing – Still in paragraph 5, we are told that Giraldo studied the level of serotonin and dopamine, which are two “brain chemicals whose decline often coincides with aging”. This implies that they are associated with aging. Thus, the answer is “chemicals”.
QUESTIONS 9-13: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
9. ANSWER: FALSE
Explain – Key words: Pheidole dentata remain, active, whole, life – In paragraph 2, the author mentions naked mole rats as an age-defying animal: they stay fit for nearly their entire lives and they can reproduce even when old. It can be said that they remain active for almost their whole life. Thus, Pheidole dentata ants are not the only animal with this feature.
10. ANSWER: TRUE
Explain – Key words: Ysabel Giraldo, first, Pheidole dentata precise, data, age – It is stated in paragraph 3: “Unlike all previous studies, which only estimated how old the ants were…she knew their exact ages”. This means that she was the first person to use the ants‟ exact ages in her studies.
11. ANSWER: FALSE
Explain – Key words: ants, Giraldo‟s experiments, behaved, predicted – It is stated in paragraph 4 that “Giraldo expected the older ants to perform poorly…but the elderly ants were all good caretakers and trail-followers”. This implies that the elderly ants behaved differently from what she expected (predicted). She thought that they would perform badly, but they performed well.
12. ANSWER: NOT GIVEN
Explain – Key words: recent, studies, bees, different, methods, measuring, age-related decline – With regard to recent studies of bees, the author only mentions in paragraph 6 that the results about age-related decline were mixed: some showed it while some didn‟t. However, there is nothing said about the methods used, So this statement is NOT GIVEN.
13. ANSWER: TRUE
Explain – Key words: Pheidole dentata laboratory, live, longer – The first sentence of paragraph 3 reveals that in the lab, Pheidole dentata ants typically live for around 140 days. Later, in paragraph 7, it is said that “out in the wild, the ants probably don‟t live for a full 140 days”. This clearly means that the ants tend to live longer in laboratory conditions. – The statement is therefore TRUE.
PASSAGE 2: WHY ZOOS ARE GOOD
QUESTIONS 14-17: READING PASSAGE 2 HAS SIX PARAGRAPHS, A-F.
14. ANSWER: B
Explain – Key words: quickly, animal, species, die out – It is mentioned in paragraph B that “some of these collapses have been sudden, dramatic and unexpected”, with “these collapses” referring to the extinction of animals. The word “sudden” is a synonym for quickly, so the sentence suggests that some animals may become extinct, or die out, quickly.
15. ANSWER: E
Explain – Key words: preferable, study, animals, captivity, wild – The term „animals in captivity‟ is another way of saying „animals in zoos‟. The role of zoos in animal research is mentioned in paragraph E: “Being able to undertake research on animals in zoos where there is less risk and fewer variables means real changes can be effected on wild populations”. So, zoos have many advantages for studying how animals live, act and react. Thus, – The answer is paragraph E.
16. ANSWER: C
Explain – Key words: two, ways, learning, animals, other than, zoos – Several ways of learning about animals are mentioned in paragraph C: zoos, television documentaries, and museums. Thus, this paragraph shows two ways of learning about animals other than visiting them in zoos.
17. ANSWER: A
Explain – Key words: animals, zoos, healthier, wild – The first sentence of the passage is: “it is perfectly possible for many species of animals living in zoos or wildlife parks to have a quality of life as high as, or higher than, in the wild”. Higher quality of life implies that zoo animals may be healthier than those in the wild. The author then goes on to discuss various reasons why zoos are healthy places for animals, including a good diet, treatment of illnesses and a safe environment from predators.
QUESTIONS 18-22: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 2?
18. ANSWER: TRUE
Explain – Key words: animal, live, longer, zoo – As we know from question 17, the comparison between animals living in zoos and in the wild is in paragraph A. “The average captive animal will have a greater life expectancy compared with its wild counterpart”. The captive animal refers to animals in zoos. Its wild counterpart refers to animals of the same species in the wild.
19. ANSWER: TRUE
Explain – Key words: species, zoos, no longer, found, wild – It is stated in paragraph B that “A good number of species only exist in captivity”, implying that these species cannot be found in the wild. – The statement is TRUE.
20. ANSWER: NOT GIVEN
Explain – Key words: improvements, TV, wildlife, documentaries, increased, numbers, zoo visitors – With regard to TV documentaries, the author only mentions (in paragraph C) that “television documentaries are becoming ever more detailed and impressive” but there is no relation between this and zoo visitor numbers. – This information is NOT GIVEN.
21. ANSWER: FALSE
Explain – Key words: zoos, excelled, information, animals, public – Paragraph D states that zoos can “communicate information to visitors about the animals they are seeing and their place in the world”. In other words, zoos can transmit information about animals to the public. It is mentioned, however, that “this was an area where zoos used to be lacking”, implying that zoos were not good at this in the past. – The statement is therefore FALSE.
22. ANSWER: NOT GIVEN
Explain – Key words: studying, animals, zoos, less, stressful, the wild – In comparison with studying animals in the wild, studying them in zoos is less risky and involves fewer variables. We only know that there is less risk for both the animals and the scientists themselves, but we do not know if studying animals in zoos is less stressful. There is no information regarding this.
QUESTIONS 23-24: CHOOSE TWO LETTERS, A-E.
23-24. ANSWER: B. SOME TRAVEL TO OVERSEAS LOCATIONS TO JOIN TEAMS IN ZOOS., D. SOME TEACH PEOPLE WHO ARE INVOLVED WITH CONSERVATION PROJECTS
Explain – Key words: two, stated, zoo staff – It is stated in paragraph D that: – “Many zoos also work directly to educate conservation workers in other countries” -> zoo staff can teach conservation workers, or people involved with conservation projects. So D is correct
Teach = educate – “..or send their animal keepers abroad to contribute their knowledge and skills to those working in zoos and reserves”. This means that some animal keepers (a type of zoo staff) travel to overseas to help other zoo staff. – So B is correct
QUESTIONS 25-26: CHOOSE TWO LETTERS, A-E.
25-26. ANSWER: B. THEY CAN INCREASE PUBLIC AWARENESS OF ENVIRONMENTAL ISSUES., E. THEY CAN RAISE ANIMALS WHICH CAN LATER BE RELEASED INTO THE WILD.
Explain – Key words: two, beliefs, zoos – In paragraph B, it is stated that some animals have been reintroduced into the wild from zoos, or that wild populations have been increased by the introduction of captive bred animals. The term „reintroduce‟ means that animals will be raised in zoos before being released into the wild. – So E is correct.
– Public = general population – Awareness = conscious – Thus, the sentence can be paraphrased into: zoos can increase public awareness of environmental issues. – B is correct.
PASSAGE 3: IELTS 14 READING TEST 4 PASSAGE 3
QUESTIONS 27-33: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 3?
27. ANSWER: FALSE
Explain – Key words: Rochman, colleagues, first, research, marine, debris – Paragraph 2 mentions that “plenty of studies have sounded alarm bells about the state of marine debris” and that “Rochman and her colleagues set out to determine how many of those perceived risks are real”. This implies that there has been other research on marine debris before Rochman and her colleagues, and they want to examine these previous studies. – Thus, the statement is FALSE.
28. ANSWER: NOT GIVEN
Explain – Key words: creatures, danger, ocean, trash, seabirds – Paragraph 3 only mentions that “certain seabirds eat plastic bags” but we do not find any information about them being the most in danger. Scientists have only „speculated‟ about wider effects: „There wasn‟t a lot of information‟. – Thus it is NOT GIVEN.
29. ANSWER: FALSE
Explain – Key words: studies, Rochman, reviewed, proved, some birds, extinct – Rochman gave an imaginary example in paragraph 3 of a study which might show certain birds eating plastic, and then warn that those birds are “at risk of dying out”. But this, as well as many other perceived threats, had not yet been tested, according to Rochman. In other words, there is no proof that the birds will soon become extinct. – The statement is therefore FALSE.
30. ANSWER: TRUE
Explain – Key words: Rochman, analysed, papers, danger, ocean trash – Paragraph 4 states that “Rochman and her colleagues examined more than a hundred papers on the impacts of marine debris” and found 366 perceived threats. It can be understood that these papers focused on various kinds of danger (threat) caused by ocean trash (marine debris).
31. ANSWER: FALSE
Explain – Key words: most, research, analysed, Rochman, badly, designed – In paragraph 5, the author states that “In 83 percent of cases, the perceived dangers of ocean trash were proven true”. So, there is obviously no reason to think that this research was badly designed if the findings were proven true, “In the remaining cases, the working group found the studies had weaknesses in design”. Therefore, only 17 percent of the cases analysed were badly designed. So, most of the cases were well designed. – The statement is FALSE.
32. ANSWER: TRUE
Explain – Key words: one, study, expecting, mussels, harmed, eating, plastic – The information about mussels (a type of shellfish) can be found in paragraph 6 The study examined mussels that eat plastic, “but it didn‟t seem to stress out the shellfish”. This means that the plastic didn‟t seem to have any harmful effect on the mussels. Rochman said this study “failed to find the effect it was looking for”, so clearly it was looking for some effect of the plastic on the mussels.
33. ANSWER: NOT GIVEN
Explain – Key words: some, mussels, choose, eat, plastic, preference, natural, diet – Paragraph 7 only states that the “mussels may be fine eating trash”. It does not mean they prefer trash to their natural diet. – The statement is NOT GIVEN.
QUESTIONS 34-39: COMPLETE THE NOTES BELOW.
34. ANSWER: LARGE
Explain – Key words: bits, debris, harmful, animals – Rochman found (paragraph 8) that “most of the dangers also involved large pieces of debris” that can cause severe injuries to animals. – So the answer is “large”.
35. ANSWER: MICROPLASTIC
Explain – Key words: little, research, synthetic fibres – Paragraph 9 mentions that “Rochman‟s group found little research on the effects of these tiny bits”, with “tiny bits” referring to microplastic. – So the answer is “microplastic”.
36. ANSWER: POPULATIONS
Explain – Key words: most, focused individual, not, entire – The remaining questions refer to the drawbacks of the studies. According to paragraph 10: “Many studies have looked at how plastic affects an individual animal…rather than the whole populations”.
37. ANSWER: CONCENTRATIONS
Explain – Key words: plastic, lab, not, reflect, ocean – It is mentioned in paragraph 10 that “in the lab, scientists often use higher concentrations of plastic than what‟s really in the ocean”. This means that the concentrations of plastic used in the lab was different from, and thus did not always correctly reflect, those in the ocean.
38. ANSWER: PREDATORS
Explain – Key words: impact, reduction, numbers, species – Rochman said in paragraph 10 that no one can tell us “how deaths in one species could affect that animal‟s predators”. Deaths in one species can be understood as a reduction in numbers of that species. – Impact = effect (affect) – Thus, there is insufficient information on how a reduction in numbers of a species can impact on their predators. The blank should be filled with “predators”.
39. ANSWER: DISASTERS
Explain – Key words: more, information, needed, impact, future, oil – According to Rochman in paragraph11, we need to ask more “ecologically relevant questions”, such as how disasters will affect the environment before they actually happen. This means that more information related to disasters is needed. She also mentioned an oil spill as an example of the impact of future disasters which we need to know more about, by asking the right questions earlier. Hence, – The answer is “disasters”.
QUESTIONS 40: CHOOSE THE CORRECT LETTER, A, B, C OR D
40. ANSWER: A. ASSESSING THE THREAT OF MARINE DEBRIS
Explain – The passage does not focus on who is to blame for marine debris, nor does it focus on any new solutions or international action, which are only briefly referred to in paragraph 12. In the final paragraph, Rochman refers to the importance of “clearing up…misconceptions” in order to know how serious the threat of marine debris really is. Therefore, it is important to interrogate “the existing scientific literature” to help ecologists to figure out “which problems really need addressing”. – The entire passage concerns Rochman and her study on other prior research on marine debris. She assessed these studies to answer the question of whether the situation is as bad as they suggested. In other words, Rochman assessed the threat of marine debris mentioned by other researchers. – A is the correct answer. – Assess = figure out
· People‟s behavior towards others‟ intelligence is mentioned in the first sentence of paragraph B: “implicit theories of intelligence drive the way in which people perceive and evaluate their own intelligence and that of others”. Non-scientists refer to normal people, and implicit theories refer to assumptions (about intelligence). The way people evaluate the intelligence of other people influences their behavior towards others.
· In the first sentence of the passage, the author claims that “no one knows for certain what it (intelligence) actually is”. Thus, it can be said that there is a lack of clarity over the definition of intelligence. The answer is paragraph A.
3. ANSWER: D
Explain
· Key words: researcher‟s, implicit, explicit, theories, different
· The relation between implicit and explicit theories is mentioned in paragraph D: “if an investigation…reveals little correspondence between the extant implicit and explicit theories, the implicit theories may be wrong”. This suggests that it is possible that these two types of theories may be different.
· Different = little correspondence
QUESTIONS 4-6: DO THE FOLLOWING STATEMENTS AGREE WITH THE CLAIMS OF THE WRITER IN READING PASSAGE 1?
· The information about parents and their children‟s language development can be found in paragraph B. While the author mentions parents making “corrections” to the children‟s speech at certain ages, there is nothing said about how parents feel towards slow language development.
· This statement is therefore NOT GIVEN.
5. ANSWER: NO
Explain
· Key words: expectations, children, gain, education, universal
· Paragraph E suggests that people‟s “expectations for intellectual performances differ for children of different ages” and of different cultures. Therefore, these expectations are not universal (universal = common in the world). The statement contradicts the author’s claims, so
· The last sentence of paragraph J states that: “Until scholars are able to discuss their implicit theories and thus their assumptions, they are likely to miss the point of what others are saying”. The expression “miss the point” here has a similar meaning to “not fully understand”, so this sentence means that scholars usually discuss their own theories without fully understanding other scholars.
· The answer is therefore YES.
QUESTIONS 7-13: LOOK AT THE FOLLOWING STATEMENTS (QUESTIONS 7-13) AND THE LIST OF THEORIES BELOW.
· The first sentence of paragraph H includes the statement: “the Jeffersonian view is that people should have equal opportunities.” Later in the paragraph, we find: “In the Jeffersonian view, the goal of education is not to favor or foster an elite…”
· Same = equal
· Possibilities = opportunities
· Thus, the idea that „It is desirable for the same possibilities to be open to everyone‟ belongs to Jeffersonian view.
· In paragraph I, the Jacksonian view is that “we do not need or want any institutions that might lead to favouring one group over another”.
· The answer is C
· Preferential treatment = favour
· Section = group
9. ANSWER: B
Explain
· Key words: people, gain, benefits, basis, achieve
· According to Jeffersonian view in paragraph H, “people are rewarded for what they accomplish”.
· The answer is B
· Gain benefits = be rewarded
· Achieve = accomplish
10. ANSWER: A
Explain
· Key words: variation, intelligence, birth
· According to paragraph G, the Hamiltonian view is that “people are born with different levels of intelligence”, which means variation in intelligence begins at birth.
· So the answer is A.
· Variation = different
11. ANSWER: A
Explain
· Key words: more intelligent, positions, power
· The Hamiltonian view, still in paragraph G, suggests that the more intelligent should keep the less intelligent “in line”, which means they should be in control. They hold the positions of power like government officials or philosopher-kings. Thus,
· The answer is A.
12. ANSWER: C
Explain
· Key words: everyone, develop, same, abilities
· According to Jacksonian view in paragraph I, people are equal in terms of their competencies. This means that everyone can have the same abilities to serve as well as another in any position.
· According to Hamiltonian theory in paragraph G, the unintelligent would create chaos if left to themselves. This means that their lives are uncontrolled.
· Low intelligence = unintelligent
· Uncontrolled = chaos
PASSAGE 2: SAVING BUGS TO FIND NEW DRUGS
QUESTIONS 14-20: READING PASSAGE 2 HAS NINE PARAGRAPHS, A-L.
· The first sentence of paragraph C states that laboratory-based drug discovery has now “prompted the development of new approaches focusing once again on natural products”. The phrase “once again” implies that this interest in natural medicine had existed before, and now it is „renewed‟. So, this is one factor behind the renewed interest in natural products. Paragraph C then mentions another factor: “This realisation, together with several looming health crises, such as antibiotic resistance, has put bioprospecting – the search for useful compounds in nature – firmly back on the map”. The expression “back on the map” also refers to „a renewed interest‟.
· The only paragraph which concerns technological advances is paragraph H: it is now possible to snip out insects‟ DNA and insert them into other cells that can produce larger quantities. The phrase “now possible” suggests that it wasn‟t possible in the past, implying a great development in technology and science.
· Paragraph A gives examples of primates which use natural substances like toxin-oozing millipedes or noxious forest plants as medicine.
· Substances = compounds
· Nature = living things
17. ANSWER: F
Explain
· Key words: reasons, challenging, insects, drug, research
· Paragraph F discusses 3 reasons why it is very difficult, or challenging, to use insects in bioprospecting (which is the search for plant and animal species from which medicinal drugs and other commercially valuable compounds can be obtained).
· The relation between insect research and wildlife (wilderness) can be found in paragraph I. The author claims that his main motivation for insect research is actually wildlife conservation, because “all species, however small and seemingly insignificant, have a right to exist for their own sake”. Thus, by showing the practical value of insect research, people would appreciate nature more, and wildlife in general will benefit.
19. ANSWER: B
Explain
· Key words: reason, nature-based, medicine, fell out of favour
· According to paragraph B: “for a while, modern pharmaceutical science moved its focus away from nature”
· For a period = for a while = trong một thời gian
· Medicine = pharmaceutical science = dược phẩm
· The term “moved its focus away” means that natural medicine was no longer the focus of pharmaceutical science. Attention „shifted‟ to the design of chemical compounds in the laboratory. In other words, it fell out of favour.
20. ANSWER: E
Explain
· Key words: example, insect-derived, medicine
· Paragraph E mentions several promising compounds derived from insects, such as alloferon, which is used in Russia and South Korea. Hence, paragraph E gives an example of an insect-derived medicine in use at the moment.
QUESTIONS 21-22: CHOOSE TWO LETTERS, A-E.
QUESTIONS 21-22
Answer: B. the variety of substances insects have developed to protect themselves, C. the potential to extract and make use of insects‟ genetic codes
Explain
· Key words: what, make, insects, interesting, for, drug research
· Although using insects for drug research is challenging, it is also interesting and potentially useful. In paragraph G, the author mentions that many insects can release compounds to subdue their prey or to deal with pathogenic bacteria and fungi. This means that humans can make use of these compounds to produce antibiotics. Thus, B is one correct answer. Another benefit from insect research is that we can extract useful compounds by snipping out insect DNAs and inserting them into particular cells to allow larger production. Therefore, C is correct.
· Using the skim and scan skill, we can find information about Aberystwyth University scientists in paragraph G. There, Piper and his colleagues use their knowledge in ecology to target certain insects for bioprospecting.
· The insects that have to product compounds to fight against pathogenic bacteria and fungi, as well as other micro-organisms, usually live in filthy habitats. Thus, it can be understood that pathogenic bacteria and fungi are found in these insects‟ habitats. Note that we cannot use “filthy habitats” because only one word is allowed.
· Piper (the author) states that “there is certainly potential to find many compounds that can serve as or inspire new antibiotics”. This means he hopes that these compounds and substances will be used to develop antibiotics (a type of drug). The answer is “antibiotics”.
· Be useful = serve
PASSAGE 3: THE POWER OF PLAY
QUESTIONS 27-31: LOOK AT THE FOLLOWING STATEMENTS (QUESTIONS 27-31) AND THE LIST OF RESEARCHERS BELOW.
27. ANSWER: B
Explain
· Key words: play, divided, separate, categories
· According to Miller & Almon (paragraph 4), there are “discrete descriptions of various types of play such as physical, construction, language or symbolic play”. This means that play can be divided into various types or categories.
· The answer is B.
· Separate = discrete
· Categories = types
28. ANSWER: G
Explain
· Key words: adults, intended goals, affect, play, children
· Hirsch-Pasek et al (paragraph 8) state that the adult‟s role in play varies according to their educational goals. In other words, adults‟ goals affect how they play with children (by taking different roles).
· Joan Goodman (paragraph 7) suggested that “hybrid forms of work and play can provide optimal contexts for learning”. This means that such hybrid, or combination, could be the best way for children to learn.
· Combine = hybrid
· Best = optimal
30. ANSWER: E
Explain
· Key words: certain, elements, play, more significant,
· While Rubin et al (paragraph 5 and 6) considered all aspects, or dimensions, of play along a continuum from less playful to more playful, they did not state that certain elements of play are more important than others: “Rubin and colleagues did not assign greater weight to any one dimension in determining playfulness”. However, Pellegrini (paragraph 6) suggested that two aspects are “the most important”, namely “process orientation” and “a lack of obvious functional purpose”. It can be inferred that Pellegrini considered these two aspects more important (more significant) than others.
· Rubin and colleagues (paragraph 5) claim that play is defined as more or less playful according to a set of criteria. In other words, there is a scale of playfulness for play. Thus, the matching researchers are Rubin et al.
· Scale = continuum
QUESTIONS 32-36: DO THE FOLLOWING STATEMENTS AGREE WITH THE CLAIMS OF THE WRITER IN READING PASSAGE 3?
32. ANSWER: NO
Explain
· Key words: children, toys, play
· In the second sentence of the passage, the author states that children will play in any circumstances, even when they have no real toys. Thus, it is incorrect to say that children need toys to play.
· The distinction between learning and play can be found in the last sentence of paragraph 2: “our society has created a false dichotomy between play and learning”. The word “dichotomy” means division, distinction between opposite things. Thus, it is false to treat play and learning as separate activities.
· Paragraph 3 gives some examples of benefits of play for children, including benefits in their behavior, science, maths, problem-solving skills, etc. Although the word “creative” is mentioned, this is only used to refer to problem-solving skills. However, there is no mention of “artistic talents”.
35. ANSWER: NO
Explain
· Key words: researchers, agreed, definition, play
· It is stated in paragraph 4 that “full consensus on a formal definition of play continues to elude the researchers and theorists who study it”. „Full consensus‟ means „full agreement‟. The word „elude‟ suggests that the definition is hard to be grasped by researchers. Thus, it is clear that they have not agreed on a definition of play yet. So the statement contradicts the author‟s claims.
· Agree = consensus
36. ANSWER: YES
Explain
· Key words: work, play, differ, target
· The difference between work and play is stated in the following sentence in paragraph 7: “Unlike play, work is typically not viewed as enjoyable and it is extrinsically motivated (i.e. it is goal oriented”. To have a goal is the same as to have a target. Work has a target, and in that way it is different from play.
· Differ = unlike
· Target = goal
QUESTIONS 37-40: COMPLETE THE SUMMARY BELOW.
37. ANSWER: ENCOURAGING
Explain
· Key words: adult, play, kid, develop, investigate, aspects, game
· The answer can be found in paragraph 9, which is about guided play. The author mentions that there are two forms of guided play, and we need to focus on the second, more direct form. In this form, the adult can encourage “further exploration or new facets” by asking questions or making comments while joining in the play.
· Investigate = exploration
· Aspects = facets
38. ANSWER: DESIRE
Explain
· Key words: adults, help, children, learn, play, activity, structured, based on
· According to Nicolopolou et al in paragraph 9, while play can be somewhat structured (with the help of adults), it must also be child-centred and “stem from the child‟s own desire”. In other words, the play should be based on the child and his/her desire to play.
39. ANSWER: AUTONOMY
Explain
· Key words: play, without, intervention, adults, real
· It is stated (in paragraph 10) that “free play provides the child with true autonomy”.
· without intervention = free
· real = true
40. ANSWER: TARGETED
Explain
· Key words: with, adults, particular goals
· In paragraph 10, it is stated that “guided play…can provide more targeted learning experiences”. We already know (from question 36), that „targets‟ and „goals‟ have a similar meaning. Guided play refers to play with the intervention of adults, so the blank should be filled with “targeted”
Cambridge IELTS 14 is the latest IELTS exam preparation.https://draftsbook.com/ will help you to answer all questions in cambridge ielts 14 reading test 2 with detail explanations.
PASSAGE 1: ALEXANDER HENDERSON (1831-1913)
QUESTIONS 1-8: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
1. ANSWER: FALSE
Explain
Henderson rarely visited the area around Press estate when he was younger.
· We should look for the piece of information related to Press estate, using the skim and scan skill. It can be found in the first paragraph. It is stated that Alexander (Henderson) “spent much of his childhood in the area”, which means he often stayed in the Press estate when he was younger. This is contradictory to the above statement. Therefore, it is FALSE.
o Younger = childhood
2. ANSWER: TRUE
Explain
Henderson pursued a business career because it was what his family wanted.
· In paragraph 2, it is mentioned that Henderson “never liked the prospect of a business career” but “stayed with it to please his family”. This means that he only pursued a business career because his family wanted him to do so. Thus, it is clear that the statement is TRUE.
3. ANSWER: NOT GIVEN
Explain
Henderson and Notman were surprised by the results of their 1865 experiment.
· We should look for the year 1865 in the passage, which is in paragraph 3.
Here, we know that Henderson and Notman carried out an experiment with magnesium flares. There is no reference, however, to the results of the experiment or about the men‟s reaction towards such results. The information is not given.
· Answer: NOT GIVEN.
4. ANSWER: FALSE
Explain
There were many similarities between Henderson’s early landscapes andthose of Notman.
· The comparison between Henderson‟s and Notman‟s landscapes can be
5. ANSWER: NOT GIVEN
Explain
The studio that Henderson opened in 1866 was close to his home.
· Key words: studio, Henderson, opened, 1866, close, home
· We should look for the year 1866 in the passage. It can be easily found in the first sentence of paragraph 5, where it is stated that Henderson opened a studio. But the author does not mention anything about its location or the distance from the studio to Henderson‟s home, so the statement is NOT GIVEN.
· Answer: NOT GIVEN.
6. ANSWER: TRUE
Explain
Henderson gave up on portraiture so that he could focus on taking photographs of scenery.
· Key words: gave up, portraiture, focus, photographs, scenery
· In the following sentence in paragraph 5, it is mentioned that “he dropped
portraiture to specialize in landscape photography and other views”
o Give up on = drop
o Focus on = specialize
o Scenery = landscape
· The word “specialize” implies that he wanted to focus his efforts on only one kind of photography, so this statement is TRUE.
· Answer: TRUE.
7. ANSWER: FALSE
Explain
When Henderson began work for the Intercolonial Railway, the Montreal toHalifax line had been finished.
· Key words: began, work, Intercolonial Railway, Montreal to Halifax line, finished
· Using the skim and scan skill, we can locate the phrase “Intercolonial Railway” in the middle of paragraph 7, then we read from there. In 1875, there was “a commission from the railway” to Henderson to record structures along the Montreal to Halifax line, which can be considered his work for the Intercolonial Railway. It is said that the line is “almost-completed”, suggesting that at the time it had not been finished yet. Therefore, the statement is FALSE.
o Finished = completed
· Answer: FALSE.
8. ANSWER: TRUE
Explain
Henderson’s last work as a photographer was with the Canadian PacificRailway.
· Key words: last, work, photographer, Canadian Pacific Railway
· “Canadian Pacific Railway” (CPR) is mentioned in the last sentence of paragraph 7 and the entire paragraph 8. It is stated that Henderson took photos along the railway in summer 1892, and he continued until 1897 before retiring completely from photography. Thus, it can be understood that his last photography work (before retiring) was with the CPR. The statement is TRUE.
· Answer: TRUE.
QUESTIONS 9-13: COMPLETE THE NOTES BELOW.
9. ANSWER: MERCHANT
Explain
was born in Scotland in 1831 – father was a …
· Key words: born, Scotland, 1831, father,
· In the first sentence of the passage, it is stated that Henderson was “the son of a successful merchant”. In other words, his father was a successful merchant. Because we can only write ONE WORD, the answer should be “merchant”.
10. ANSWER: EQUIPMENT
Explain
people bought Henderson’s photos because photography took upconsiderable time and the … was heavy
· In paragraph 5, we know that there was a demand for Henderson‟s landscape photos. People bought his photos because “there was little competing hobby or amateur photography”, suggesting that at the time, not many people took photographs. Henderson, therefore, did not have much competition from amateur photographers or people who took photographs for a hobby. There are two reasons for this: “time-consuming techniques” and the“weight of the equipment”. The former can be understood as “taking up considerable time”, and the latter as “heavy equipment”. Thus, the answer is “equipment”.
o Take up considerable time = time-consuming
11. ANSWER: GIFTS
Explain
the photographs Henderson sold were … or souvenirs
· Still in paragraph 5, it is stated that “people wanted to buy photographs as souvenirs of a trip or as gifts”. Therefore, it is clear that the blank should be filled with “gifts”.
12. ANSWER: CANOE
Explain
took many trips along eastern rivers in a …
· Key words: took, trips, eastern rivers,
· We can use the first point in “travelling as a professional photographer” as a cue: it is stated in the first sentence of paragraph 7. Subsequently, “eastern rivers” are mentioned, as Henderson “often travelled by canoe” on these rivers. Thus, the answer is “canoe”.
· Took many trips = travelled
13. ANSWER: MOUNTAINS
Explain
worked for CPR in 1885 and photographed the … and the railway at RogersPass
· Key words: worked for, CPR, 1885, photographed, railway, RogersPass
· As we have learned in question 8, the information about Henderson‟s work for CPR can be found in paragraph 7 and 8. The year 1885 is mentioned in paragraph 7, so we should read from there. It is stated that he took photos of “the mountains and the progress of construction” at Rogers Pass. The construction here refers to that of the railway, so the remaining item is “mountains”, which is the answer.
o Photographed = took photos of
PASSAGE 2: BACK TO THE FUTURE OF SKYSCRAPER DESIGN
QUESTIONS 14-18: READING PASSAGE 2 HAS NINE SECTIONS, A-I.
14. ANSWER: F
Explain
why some people avoided hospitals in the 19th century
· Key words: why, avoided, hospitals, 19th century
· Information about 19th century hospitals can be found in paragraphs D, E and F. Paragraphs D and E discuss the designs and performance of hospitals in the 19th century, but we are looking for a reason why people avoided hospitals. Paragraph F mentions that “the prosperous steered clear of hospitals”. “The prosperous” refers to rich people, and can be called “some people”. The phrasal verb “steer clear of” means “keep away from”, or in other words, “avoid”. Therefore, the reason why some people avoided hospitals in the 19thcentury was „hospital fever‟. The correct answer is F.
o Avoid = steer clear of
15. ANSWER: C
Explain
a suggestion that the popularity of tall buildings is linked to prestige
· In paragraph C, the author says that skyscrapers are symbols of status and not practical, implying that skyscrapers (tall buildings) are popular these days because people associate them with status, or prestige. Therefore, the answer is C.
o Tall buildings = skyscrapers
o Prestige = status
· Answer: C
16. ANSWER: E
Explain
a comparison between the circulation of air in a 19th–century building and modern standards
· Key words: comparison, circulation of air, 19th century, building, modern, standards
· In paragraph E: “19th century hospital wards could… – that‟s similar to the performance of a modern-day operating theatre”. The word “similar” suggests a comparison, and “modern-day operating theatre” can be understood as modern standards. This sentence discusses the capacity of buildings to generate air changes, which is the circulation of air inside a building. Thus, this sentence is a comparison between the circulation of air in 19th century hospitals and modern buildings. The correct paragraph is E.
o Circulation of air = air changes
17. ANSWER: D
Explain
how Short tested the circulation of air in a 19th–century building
· Key words: Short, tested, circulation of air, 19th–century, building
· We can find information about Short‟s test in paragraph D. His test was “to put pathogens in the airstreams” of a 19th century hospital. He found that “the ventilation systems in the room would have kept other patients safe from harm”. This means that he tested the circulation of air in the hospital (of 19th century).
o Circulation of air = ventilation
· Answer: D
18. ANSWER: B
Explain
an implication that advertising led to the large increase in the use of air conditioning
· Key words: implication, advertising, increase, air conditioning
· Paragraph B mentions the “widespread introduction of air conditioning systems”, which is the result of marketing by their inventors.
o Advertising = marketing
o Large = widespread
· Therefore, it can be paraphrased that advertising led to the large increase in the use of air conditioning.
QUESTIONS 19-26: COMPLETE THE SUMMARY BELOW.
19. ANSWER: DESIGNS
Explain
Professor Alan Short examined the work of John Shaw Billings, whoinfluenced the architectural … of hospitals to ensure they had good ventilation.
· Key words: Alan Short, examined, John Shaw Billings, influenced, architectural, hospitals, ventilation
· The part containing information about John Shaw Billings (JSB) can be found in paragraph D. The first sentence mentions that Short‟s book “highlights” the art and science of ventilating buildings, including a study of the designs of JSB for a hospital in Baltimore in the 19th century. This suggests that in order to publish the book, Short must have had examined JSB‟s work. Later, in the last sentence of paragraph E, Short describes JSB‟s designs and other designs of 19th century buildings, stating that“up to half the volume of the building was given over to ensuring everyone got fresh air”.
· Have good ventilation = get fresh air
· Therefore, the answer is “designs”.
20. ANSWER: PATHOGENS
Explain
He calculated that … in the air coming from patients suffering from … would not have harmed other patients.
· Key words: calculated, air, patients, suffering, harmed, other patients
· In the last sentence of paragraph D, Short explained his findings: “We put pathogens in the airstreams, modeled for someone with tuberculosis … the ventilation systems in the room would have kept other patients safe from harm”. So, patients with tuberculosis (TB) would release pathogens in the air when they coughed – these minute organisms would harm other patients unless there was good ventilation. Short modeled this in his experiment. The answer for 20 is “pathogens”.
· The purpose of this experiment was to test whether the system could prevent TB pathogens from spreading. Therefore, it is clear that answer for question 21 would be “tuberculosis”.
21. ANSWER: TUBERCULOSIS
Explain
He calculated that … in the air coming from patients suffering from … would not have harmed other patients.
· Key words: calculated, air, patients, suffering, harmed, other patients
· In the last sentence of paragraph D, Short explained his findings: “We put pathogens in the airstreams, modeled for someone with tuberculosis … the ventilation systems in the room would have kept other patients safe from harm”. So, patients with tuberculosis (TB) would release pathogens in the air when they coughed – these minute organisms would harm other patients unless there was good ventilation. Short modeled this in his experiment. The answer for 20 is “pathogens”.
· The purpose of this experiment was to test whether the system could prevent TB pathogens from spreading. Therefore, it is clear that answer for question 21 would be “tuberculosis”.
22. ANSWER: WARDS
Explain
He also found that the air in … in hospitals could change as often as in a modern operating theatre.
· Key words: air, hospitals, change, often modern operating theatre
· The first sentence of paragraph E states that “19th-century hospital wards could generate up to 24 air changes an hour – that‟s similar to the performance of a modern-day, computer-controlled operating theatre”. This means that the air in hospitals wards could change as often as in a modern operating theatre. Thus, the word in the blank is “wards”.
· Answer: wards
23. ANSWER: COMMUNAL
Explain
He suggests that energy use could be reduced by locating more patients in … areas.
· Key words: energy, reduced, locating, patients,
· In the middle of paragraph E, Short states that communal wards “would work just as well…at a fraction of the energy cost”. “Communal wards” imply that more than one patient is located in each ward. “Fraction” implies that energy cost would be reduced, because less energy would be used. Therefore, the answer is “communal” areas.
24. ANSWER: PUBLIC
Explain
A major reason for improving ventilation in 19th–century hospitals was the demand from the … for protection against bad air, known as …
· Key words: major, reason, improving, ventilation, 19th century hospitals, demand, protection, against bad air
· The first sentence of paragraph F states that much of the ventilation demand was “driven by a panicked public clamouring for buildings that could protect against … miasmas – toxic air that spread disease”. The phrasal verb “clamour for” means “demand or request something passionately”. In this context, it can be understood that the public demanded proper ventilation to protect them from toxic air (or „bad air‟) known as miasmas. Thus, the answers are “public” and “miasmas”, respectively.
o Demand = clamour for
· Answer: public; miasmas
25. ANSWER: MIASMAS
Explain
A major reason for improving ventilation in 19th–century hospitals was the demand from the … for protection against bad air, known as …
· Key words: major, reason, improving, ventilation, 19th century hospitals, demand, protection, against bad air
· The first sentence of paragraph F states that much of the ventilation demand was “driven by a panicked public clamouring for buildings that could protect against … miasmas – toxic air that spread disease”. The phrasal verb “clamour for” means “demand or request something passionately”. In this context, it can be understood that the public demanded proper ventilation to protect them from toxic air (or „bad air‟) known as miasmas. Thus, the answers are “public” and “miasmas”, respectively.
o Demand = clamour for
26. ANSWER: CHOLERA
Explain
These were blamed for the spread of disease for hundreds of years, including epidemics of in London and Paris in the middle of the 19th century.
· Key words: blamed, spread disease, hundreds of years, epidemics, London and Paris, middle, 19th century
· The following sentence states that miasmas were feared as the cause of disease and epidemics for centuries. The author also names two epidemics: the Middle Ages infection and the cholera outbreaks in London and Paris in the 1850s (or mid-19th century). The latter is the information we need, so the answer is “cholera”.
o Disease = infection
o Hundreds of years = centuries
o Epidemics = outbreak
PASSAGE 3: WHY COMPANIES SHOULD WELCOME DISORDER
QUESTIONS 27-34: READING PASSAGE 3 HAS EIGHT SECTIONS, A-H.
27. ANSWER: VI
Explain Section A
· This section describes the popular opinion, or belief, that we ought to organize everything in our life to become more productive. Part of this can be considered “recommendations concerning business activities” (heading iii), but it also concerns other aspects of life besides work. In addition, this practice has only been widespread in recent times, not “early” times, so iii cannot be the answer.
· The most suitable heading would be vi – What people are increasingly expected to do. More “than at any other time in human history”, “We are told that we ought to organise our company, our home life, our week, our day and even our sleep…” So, increasingly (more than at any other time), people are told to (= they are expected to) become more organised.
28. ANSWER: I
Explain Section B
· While section A introduces the structured and organised approach to our lives, section B mentions its drawbacks. “A large proportion of workers…claimed to be dissatisfied with the way their work is structured and the way they are managed”. So i – Complaints about the impact of a certain approach is the correct answer.
29. ANSWER: III
Explain Section C
· Section C is about the history of the science of management, with Frederick Taylor being one of the pioneers in the early part of the 20th century. So the only appropriate heading for this would be iii – Early recommendations concerning business activities.
30. ANSWER: II
Explain Section D
· This section discusses the “misguided” assumptions about efficiency. The emphasis on order has led to people‟s efforts to become organised without understanding that organisation does not always bring increased productivity. These basic assumptions can be considered “fundamental beliefs that are in fact incorrect”. Thus, the answer is ii.
o Fundamental = basic
o Incorrect = misguided
31. ANSWER: IX
Explain Section E
· Section E mentions the term “diminishing returns” of order, which basically means that the disadvantages of organising may eventually outweigh the advantages at some point: “if the cost of formally structuring something outweighs the benefit of doing it, then that thing ought not to be formally structured”. This has been shown in recent studies, so there is evidence behind this. Thus, the correct heading is ix – Evidence that a certain approach can have more disadvantages than advantages.
o Advantages = benefits
32. ANSWER: VII
Explain Section F
· This section suggests that “the best approach is to create an environment devoid of structure”, which “can lead to new solutions that, under conventionally structured environments, would never be reached”. This implies that a new approach can achieve outcomes that are impossible under the current practice (a conventionally structured environment). The answer is vii.
33. ANSWER: IV
Explain Section G
· Section G discusses the new approach – disorganisation, which has been embraced by many companies: Google, General Electric, Oticon, etc. Thus, the heading for this section is iv – Organisations that put a new approach into practice.
o Organisations = companies
o Put into practice = embrace
34. ANSWER: VIII
Explain Section H
· This section warns readers that “…disorder, much like order, also seems to have diminishing utility, and can also have detrimental effects on performance if overused”. Therefore, they should only be used “so far as it is useful”. So the only appropriate heading for this is viii – Neither approach guarantees continuous improvement.
QUESTIONS 35-37: COMPLETE THE SENTENCES BELOW.
35. ANSWER: PRODUCTIVE
Explain
Numerous training sessions are aimed at people who feel they are not … enough.
· Key words: numerous, training sessions, aimed, people, feel
· Section A mentions “countless seminars and workshops”, which can also be called “numerous training sessions”, that help people to organise better, and hence become more productive. Thus, it can be inferred that these are aimed to help people who are not productive enough. The answer is “productive”.
o Numerous = countless
o Training sessions = seminars, workshops
· Answer: productive
36. ANSWER: PERFECTIONISTS
Explain
Being organised appeals to people who regard themselves as …
· The last paragraph of section A suggests that the idea of organising everything has become popular among business leaders and entrepreneurs, “much to the delight of” perfectionists. This means that being organised appeals to perfectionists. So the answer is “perfectionists”.
37. ANSWER: DISSATISFIED
Explain
Many people feel … with aspects of their work.
· Key words: many, feel, aspects, work
· Section B mentions that “a large proportion of workers…claimed to be dissatisfied” with two aspects of their work: the way it is structured and the
way they are managed. Therefore, the answer is “dissatisfied”.
· Answer: dissatisfied
QUESTIONS 38-40: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 3?
38. ANSWER: TRUE
Explain
Both businesses and people aim at order without really considering its value.
· Key words: businesses, people, aim, order, value
· We can find information concerning “businesses and people” in the last sentence of section D: they “spend time and money organising” rather than actually “looking at the usefulness of such an effort”.
o Value = usefulness
· So businesses and people aim to be organised (aim at order), but they do not really consider its usefulness (value). Thus, it is clear that the statement is TRUE.
39. ANSWER: FALSE
Explain
Innovation is most successful if the people involved have distinct roles.
· By using the skim and scan skill, we find that “innovation” is mentioned in the first sentence of section F. Here, it is stated that “the best approach is to create an environment devoid of structure and hierarchy”. This means that innovation is most successful when people are involved as the whole group, rather than as distinct roles found in a structure and hierarchy. Thus, this statement is FALSE.
40. ANSWER: NOT GIVEN
Explain
Google was inspired to adopt flexibility by the success of General Electric.
· Key words: Google, inspired, adopt, flexibility, success, General Electric
· The last paragraph of section G contains information about General Electric and Google. It is mentioned that both of them have embraced disorganisation, or flexibility, in their companies. However, the author does not mention anything about General Electric‟s success or the relation between Google and General Electric. So we cannot say that Google adopted flexibility because of General Electric. The answer is NOT GIVEN.
Cambridge IELTS 14 is the latest IELTS exam preparation.https://draftsbook.com/ will help you to answer all questions in cambridge ielts 14 reading test 1 with detail explanations.
PASSAGE 1: THE IMPORTANCE OF CHILDREN’S PLAY
QUESTIONS 1-8: COMPLETE THE NOTES BELOW.
1. ANSWER: CREATIVITY
Explain building a “magical kingdom” may help develop …
– Key words: magical kingdom, develop
– The phrase “magical kingdom” is put in the double quotes, implying it is emphasized as a phrase used in the text. As we can easily locate the phrase in the first sentence of the passage, we should pay attention to the first paragraph. What we need to focus on now is what the fantasy of building a magical kingdom can help develop, referring to its benefits in the future. The answer should be mentioned in the next sentences, after describing what building a magical kingdom is like. In those sentences, “take first steps towards her capacity” can be understood as “develop”, and it refers to “creativity”. Therefore, creativity is the answer.
2. ANSWER: RULES
Explain board games involve … and turn-taking
– Key words: board games, turn-taking
– We have to find information referring to board games. It is in the last sentence of paragraph 2 (we use scanning skills to find the word “board game” in the passage): “When they tire of this and settle down with a board game, she‟s learning how to follow the rules and take turns with a partner”. So with board games, a child can learn to “follow the rules” and “take turns” (it means “turntaking”, which is mentioned already as one of the two things involved). As the word needed should be a noun (after “involve”) and the task asks for one word only, it must be “rules”.
3. ANSWER: CITIES
Explain populations of … have grown
– Key words: populations, grown
– Remember that question 3 belongs to the section “Recent changes affecting children‟s play”, so we should focus on the part of the passage where the author mentions “changes”, which is paragraph 5. Here, the author refers to “changing times”. “Population” means “the number of people or a species living in a certain area”. The word needed here should be a noun referring to a place or a species. In paragraph 5, the writer confirms that “over half of people in the world now live in cities”, implying the number of people living in cities has increased/ grown compared to the past. Therefore, The answer is “cities”.
– The author mentions “Opportunities for free play” by saying that they “are becoming increasingly scarce” and “outdoor play is curtailed” in the second and third sentence in paragraph 5. “Curtail” means to reduce something with the result that we can no longer continue to do it. So we can assume it is replaced by the word “limited” here. Therefore, we should focus on those sentences to find the reasons for that. Reasons which are listed include “perception of risk to do with traffic”, “parents wish to protect their children from being victims of crime” and “greater competition in academic learning and schools”. “Perception of risk” and “wish to protect their children from something” should be considered as fears. Therefore, “traffic” and “crime” are the answers for Question 4 and 5 (One word only and it should be a noun – after preposition “of”). The third reason mentioned is “greater competition” in schools and “greater” can be understood as “increased”, so the answer for Question 6 is “competition”‟.
– The author mentions “Opportunities for free play” by saying that they “are becoming increasingly scarce” and “outdoor play is curtailed” in the second and third sentence in paragraph 5. “Curtail” means to reduce something with the result that we can no longer continue to do it. So we can assume it is replaced by the word “limited” here. Therefore, we should focus on those sentences to find the reasons for that. Reasons which are listed include “perception of risk to do with traffic”, “parents wish to protect their children from being victims of crime” and “greater competition in academic learning and schools”. “Perception of risk” and “wish to protect their children from something” should be considered as fears. Therefore, “traffic” and “crime” are the answers for Question 4 and 5 (One word only and it should be a noun – after preposition “of”). The third reason mentioned is “greater competition” in schools and “greater” can be understood as “increased”, so the answer for Question 6 is “competition”‟.
– The author mentions “Opportunities for free play” by saying that they “are becoming increasingly scarce” and “outdoor play is curtailed” in the second and third sentence in paragraph 5. “Curtail” means to reduce something with the result that we can no longer continue to do it. So we can assume it is replaced by the word “limited” here. Therefore, we should focus on those sentences to find the reasons for that. Reasons which are listed include “perception of risk to do with traffic”, “parents wish to protect their children from being victims of crime” and “greater competition in academic learning and schools”. “Perception of risk” and “wish to protect their children from something” should be considered as fears. Therefore, “traffic” and “crime” are the answers for Question 4 and 5 (One word only and it should be a noun – after preposition “of”). The third reason mentioned is “greater competition” in schools and “greater” can be understood as “increased”, so the answer for Question 6 is “competition”‟.
7. ANSWER: EVIDENCE
Explain it is difficult to find … to support new policies
– Key words: difficult, find, support, new policies
– New policies are mentioned in paragraph 6, so we should pay attention here. As the word “difficult” is mentioned, we need to look for difficulties or disadvantages of supporting new policies. At first, the author mentions all the advantages, then he uses “but”, implying an added statement, usually something different from what he said before, so we can assume the next statement will be a disadvantage so we should focus here. “But what we often lack is the evidence to base policies on”. The phrase “to base policies on” can be considered as “to support new policies”, and “what they lack” means “it is difficult to find”, so the answer is “evidence”.
8. ANSWER: LIFE
Explain research needs to study the impact of play on the rest of the child’s …
– Key words: research, study, impact, play, the rest, the child’s
– As the word needed is put behind a possessive adjective (child‟s), we need to look for a noun referring to the child. Paragraph 7 talks about the long – term impact of play. In the last sentence, the author explains that “long-term impact of play” means “the impact of play on the child‟s later life” while “later” refers to “the rest”. Therefore, what is needed to fill in the blank here is “life”.
QUESTIONS 9-13: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
9. ANSWER: TRUE
Explain Children with good self-control are known to be likely to do well at school later on Key words: children, self-control, well, school, later
– Find the paragraph beginning: “In a study carried out by Baker….” This was a study of very young pre-school children. The study found that “children with greater self-control solved problems more quickly..” According to the next paragraph, play is therefore very significant for education, “because the ability to self-regulate (= to control oneself) has been shown to be a key predictor of academic performance”. So, developing good self-control through play means that children are likely to do well academically in school later on
10. ANSWER: TRUE
Explain The way a child plays may provide information about possible medical problems Key words: plays, information, medical problems
– Find the paragraph beginning: “Gibson adds…” This is about the way that children play or, in other words, “playful behaviour”. We are told that this can indicate the healthy social and emotional development of children. Observing how children play “can give us important clues (= provide information) about their well-being and can even be useful in the diagnosis of neurodevelopmental disorders like autism”. Autism is an example of a medical problem. Therefore, a child‟s behaviour during play may give information to help identify medical problems.
11. ANSWER: NOT GIVEN
Explain Playing with dolls was found to benefit girls’ writing more than boys’ writing
– Key words: dolls, benefit, writing
– Find the paragraph beginning: “Whitebread‟s recent research…” This is about using play to support children‟s writing, because “Children wrote longer and better-structured stories when they first played with dolls representing characters in the story”. So, playing with dolls benefits the writing of children in general, but we are not told if this benefits girls more than boys.
12. ANSWER: FALSE
Explain Children have problems thinking up ideas when they first created the story with Lego
– Key words: problems, ideas, create story, Lego
– In the same paragraph, we find the key words: “In the latest study, children first created their story with Lego with similar results. Many teachers commented that they had always previously had children saying they didn‟t know what to write about. With the Lego building, however, not a single child said this….” So, using Lego to think up ideas (= create their story), children then had no problems with ideas for their stories.
13. ANSWER: TRUE
Explain People nowadays regard children’s play as less significant than they did in the past
– Key words: play, regard, less significant, past
– We find the answer in the last paragraph: “Somehow the importance of play has been lost in recent decades. It‟s regarded as something trivial, or even as something negative that contrasts with „work‟ “. In recent decades, attitudes to play have, therefore, changed. It is now considered to be something unimportant or even negative. In contrast, people in the past thought that it was more important.
https://www.youtube.com/watch?v=PQFctKhlcU8The Importance Of Children’s Play | IELTS Reading
PASSAGE 2: THE GROWTH OF BIKE-SHARING SCHEMES AROUND THE WORLD
QUESTIONS 14-18: READING PASSAGE 2 HAS SEVEN PARAGRAPHS, A-G.
14. ANSWER: E
Explain a description of how people misused a bike-sharing scheme
– Paragraph E states that: “The system was prone to vandalism and theft”. This means that people damaged and stole bikes from the scheme, thus both can be called actions of misusing the scheme. Therefore, the answer is E.
15. ANSWER: C
Explain an explanation of why a proposed bike-sharing scheme was turned down Key words: explanation, proposed, bike-sharing scheme, turned down
– Paragraph C states that: “the council unanimously rejected the plan”. o Turn down = reject o Scheme = plan
– The author further explains that the council turned down the plan because they believed bikes were a thing of the past. Thus, paragraph C gives explanation of why a proposed bike-sharing scheme was turned down.
16. ANSWER: F
Explain a reference of a person being unable to profit from their work
– Key words: reference, person, unable, profit, work
– We can find information relating to profit in both paragraphs E and F. In paragraph E, we know that the chip card wasn‟t profitable, but it is irrelevant to „a person being unable to profit from their work‟. In paragraph F, however, we know that Schimmelpennink financially “didn‟t really benefit from it” („it‟ refers to his bike-sharing programme). Thus, Schimmelpennink didn‟t profit from his work. o Profit = benefit
17. ANSWER: C
Explain an explanation of the potential savings a bike-sharing scheme would bring
– Schimmelpennink stated in paragraph C that his bike-sharing scheme “would cost the municipality only 10% of what it contributed to public transport per person per kilometre”. This suggests that the benefits of the scheme were much greater than the cost, hence it would save a lot of resources. This can be considered „the potential savings‟ of this scheme. Therefore, the answer is C.
18. ANSWER: A
Explain a reference to the problems a bike-sharing scheme was intended to solve
– The purposes of a bike-sharing scheme are mentioned in paragraph A: “the scheme…was an answer to the perceived threats of air pollution and consumerism”. Hence, air pollution and consumerism are two problems that the scheme was intended to solve. o Problems = threats
QUESTIONS 19 AND 20: CHOOSE TWO LETTERS, A-E.
19-20. ANSWER: B IT FAILED WHEN A PARTNER IN THE SCHEME WITH DREW SUPPORT. D IT WAS MADE POSSIBLE BY A CHANGE IN PEOPLE’S ATTITUDES.
Explain Which TWO of the following statements are made in the text about the Amsterdam bike-sharing scheme of 1999?
– While there are a few mentions of the Amsterdam bike-sharing scheme in the text, we need to find information about the 1999 scheme, not the initial one. We can find this in paragraph D onwards.
– Schimmelpennink and his scheme “succeeded in arousing the interest of the Dutch Ministry of Transport”, so A is incorrect.
– Schimmelpennink said “times had changed”, referring to people‟s change in attitudes towards the environment. This, combined with the success of the Danish bike-sharing scheme, led to the introduction of the new Amsterdam scheme in 1999. In other words, it was made possible by a change in people‟s attitudes. Thus, D is one correct answer.
– Paragraph E mentions several problems faced by the scheme: vandalism, theft, and most importantly, Postbank‟s withdrawal from the scheme. We know this because: “Postbank decided to abolish the chip card” and “the business partner had lost interest”. This was “the biggest blow” to the scheme, and the scheme could not continue. Therefore, B is correct.
QUESTIONS 21 AND 22: CHOOSE TWO LETTERS, A-E.
21/22. ANSWER: D- A BIKE-SHARING SCHEME WOULD BENEFIT RESIDENTS WHO USE PUBLIC TRANSPORT, E -THE CITY HAS A REPUTATION AS A PLACE THAT WELCOMES CYCLISTS
Explain Which TWO of the following statements are made in the text about the Amsterdam today?
– Key words: two, statements, Amsterdam, today
– We can easily find the phrase “Amsterdam today” at the beginning of paragraph G.
– “38% of all trips are made by bike”, but we cannot be sure that more trips in the city are made by bike than by any other form of transport, so C is incorrect.
– “it is regarded as one of the two most cycle-friendly capitals in the world”, which means Amsterdam is known as a place that welcomes cyclists. Thus, E is correct.
– Schimmelpennick also mentions the need for a bike-sharing scheme in Amsterdam today because “people who travel on the underground don‟t carry their bike around. But often they need additional transport to reach their final destination”. People using the underground are “residents who use public transport”, and they would benefit from the scheme. Thus, D is correct.
QUESTIONS 23-26: COMPLETE THE SUMMARY BELOW.
23. ANSWER: ACTIVISTS
Explain The people who belonged to this group were …
– Key words: people, belonged, this group,
– “This group” refers to the Dutch group, Provo. We can find information about Provo in paragraph A. Here, it is stated that Provo “was a group of Dutch activists”, so “activists” is the answer.
24. ANSWER: CONSUMERISM
Explain They were concerned about the damage to the environment and about …
– Key words: concerned, about, damage, environment, and
– Provo activists believed that the scheme would help to deal with air pollution and consumerism. This means that they are concerned about these two problems, and suggested a solution. Because air pollution can be understood as „damage to the environment‟, the missing word in the blank is „consumerism‟.
25. ANSWER: LEAFLETS
Explain As well as painting some bikes white, they handed out … that condemned the use of cars.
– Key words: painting, bikes, white, handed out, condemned, use of cars
– The word „condemn‟ means „disapprove‟. It is stated that Provo activists “distributed leaflets describing the dangers of cars”, meaning these leaflets disapproved (or condemned) the use of cars. o Hand out = distribute
26. ANSWER: POLICE
Explain However, the scheme was not a great success: almost as quickly as Provo left the bikes around the city, the … took them away.
– Paragraph B describes the scheme‟s problems, one of which is that the police removed the bikes “as soon as the white bikes were distributed around the city”. Therefore, it is clear that the answer is “police”. o Take away = remove o As quickly as = as soon as
PASSAGE 3: MOTIVATIONAL FACTORS AND THE HOSPITALITY INDUSTRY
QUESTIONS 27-31: LOOK AT THE FOLLOWING STATEMENTS (QUESTIONS 27-31) AND THE LIST OF RESEARCHERS BELOW.
27. ANSWER: E
Explain Hotel managers need to know what would encourage good staff to remain.
– Paragraph 8 refers to the practices that hotel management must develop “to inspire and retain competent employees”. The last sentence of paragraph 8 states that “it is beneficial for hotel managers to understand what practices are most favourable to increase employee satisfaction and retention”. To increase employee retention means to encourage employees to remain. This is the statement of Enz and Siguaw (2000), so the answer is E. o Good = competent o Staff = employee
28. ANSWER: D
Explain The actions of managers may make staff feel they shouldn’t move to a different employer.
– According to Ng and Sorensen in paragraph 5: “employees feel more obligated to stay with the company” if the manager does certain things, such as: providing recognition, motivating group work, and removing obstacles. These are „actions of managers‟, and these actions make employees feel that they should stay with the company and shouldn‟t move to another employer. So D is the correct answer.
29. ANSWER: B
Litter is done in the hospitality industry to help workers improve their skills
Keywords for this question : little, done, hospitality, help workers, improve skills
This answer can be traced in Paragraph no.4, at the very begining. “Lucas also points out that “the substance of HRM practices does not appear to be designed foster constructive relations with employees or to represent a management approach that enables developing and drawing out the full potential of people,…
The lines suggest that such HRM practices does very little ( or nothing ) to help the employees hone ( Sharpen or improve ) their full potential (skills)
So, the answer is B (Lucas )
30. ANSWER: D
Explain Staff are less likely to change jobs if cooperation is encouraged.
– Key words: staff, less likely, change, jobs, cooperation, encouraged
– As we have learned in question 28, Ng and Sorensen suggest in paragraph 5 that motivating employees to work together, as well as other actions, is a way to keep staff from changing jobs. o Cooperation = work together o Encourage = motivate
– Therefore, D is the answer.
31. ANSWER: C
Explain Dissatisfaction with pay is not the only reason why hospitality workers change jobs.
– Key words: dissatisfaction, pay, reason, hospitality, workers, change, jobs
– In the last sentence of paragraph 4, the author cited Madouras et al. to mention several reasons which result in high employee turnover in hospitality industry. These reasons include “low compensation”, or in other words, low pay. High employee turnover means that a high percentage of workers leave the company and are replaced by new employees. Thus, it can be understood that dissatisfaction with low pay is, along with other reasons, why hospitality workers change jobs frequently. The answer is C.
o Pay = compensation
o Change jobs = employee turnover
QUESTIONS 32-35: DO THE FOLLOWING STATEMENTS AGREE WITH THE CLAIMS OF THE WRITER IN READING PASSAGE 3?
32. ANSWER: YES
Explain One reason for high staff turnover in the hospitality industry is poor morale.
– Paragraph 4 refers to “high employee turnover” in the hospitality industry. As we know from question 31, “compromised employee morale” is given in paragraph 4 as one reason for high employee turnover in the hospitality industry. The word „compromised‟ here suggests that employees are not very motivated to do their work, so we can also call it „poor morale‟. The correct answer is YES.
33. ANSWER: NO
Explain Research has shown that staff have a tendency to dislike their workplace
– According to Spector et al in paragraph 6, “no evidence exists to support this hypothesis”. The said hypothesis is that employees have “a predisposition to view their work environment negatively”. In other words, employees have a tendency to dislike their workplace.
– Because there is no evidence, it cannot be said that this hypothesis is shown or proven by research. The answer is, therefore, NO.
o Tendency = predisposition
o Dislike = view negatively
o Workplace = work environment
34. ANSWER: NO
Explain An improvement in working conditions and job security makes staff satisfied with their jobs
– We can find information relating to „working conditions and job security‟ in paragraph 9. According to Herzberg, when these are not good, employees may be dissatisfied. However, fulfilling factors like working conditions and job security alone “does not result in satisfaction” so the statement contradicts the writer‟s claims.
35. ANSWER: NOT GIVEN
Explain Staff should be allowed to choose when they take breaks during the working day.
– Key words: staff, allowed, choose, breaks, working day
– In the last paragraph, it is stated that “allowing adequate breaks during the working day” is a way to retain good staff. However, this does not mean that staff should be allowed to choose when they take breaks. The statement is therefore NOT GIVEN.
36. ANSWER: RESTAURANTS
Explain Tews, Michel and Stafford carried out research on staff in an American chain of …
– Key words: Tews, Michel, Stafford, research, staff, American chain
– Using the skim and scan skill, we can locate the information about Tews, Michael and Stafford‟s study in paragraph 11. The study (research) focused on “staff from a chain of themed restaurants in the United States”. Thus, the answer is clearly “restaurants”
o Research = study
o American = United States
QUESTIONS 36-40: COMPLETE THE SUMMARY BELOW.
37. ANSWER: PERFOMANCE
Explain They discovered that activities designed for staff to have fun improved their … ,
– Continue to read paragraph 11. According to these researchers, “It was found that fun activities had a favourable impact on performace”, meaning that fun activities improved staff performance. The answer for question 37 is “performance”.
– Next, “manager support for fun had a favourable impact in reducing turnover”. In this context, “manager support for fun” can be paraphrased into “manager involvement”.
o Discover = find
o Lower = reduce
– Thus, the answer for question 38 is “turnover”.
38. ANSWER: TURNOVER
Explain and that management involvement led to lower staff …
– Continue to read paragraph 11. According to these researchers, “It was found that fun activities had a favourable impact on performace”, meaning that fun activities improved staff performance. The answer for question 37 is “performance”.
– Next, “manager support for fun had a favourable impact in reducing turnover”. In this context, “manager support for fun” can be paraphrased into “manager involvement”.
o Discover = find
o Lower = reduce
– Thus, the answer for question 38 is “turnover”.
39. ANSWER: GOALS
Explain They also found that the activities needed to fit both the company’s …
– Key words: activities, needed, fit, company’s,
– Continuing to read paragraph 11, according to Tews, Michel and Stafford, the “framing of that fun” must be aligned with two things: organizational goals (paraphrased into company‟s goals) and employee characteristics. Thus, it is clear that the correct answers are “goals” and “characteristics”, respectively.
o Fit = align with
40. ANSWER: CHARACTERISTICS
Explain and the … of the staff
– Key words: activities, needed, fit, company’s,
– Continuing to read paragraph 11, according to Tews, Michel and Stafford, the “framing of that fun” must be aligned with two things: organizational goals (paraphrased into company‟s goals) and employee characteristics. Thus, it is clear that the correct answers are “goals” and “characteristics”, respectively.
PASSAGE 1: CUTTY SARK: THE FASTEST SAILING SHIP OF ALL TIME
QUESTIONS 1-8: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
1. CLIPPERS WERE ORIGINALLY INTENDED TO BE USED AS PASSENGER SHIPS
Key words: clippers, originally, passenger At the beginning of paragraph 2, we find the statement: “The fastest commercial sailing vessels of all time were clippers, three-masted ships built to transport goods around the world, although some also took passengers”. So, clippers were built/used originally to transport goods, not to carry passengers.
– ships = vessels
The statement is FALSE.
2. CUTTY SARK WAS GIVEN THE NAME OF A CHARACTER IN A POEM
Key words: name, character, poem In paragraph 3, the writer explains how the ship was given its name: “Cutty Sark’s unusual name comes from the poem Tam O’Shanter by the Scottish poet, Robert Burns. Tam, a farmer, is chased by a witch called Nannie, who is wearing a ‘cutty sark’ – an oldScottish name for a short nightdress”. A cutty sark, therefore, is a short nightdress, not the name of a character in the poem. It was a piece of clothing worn by the witch in the poem. The statement is FALSE.
3. THE CONTRACT BETWEEN JOHN WILLIS AND SCOTT & LINTON FAVOURED WILLIS
Key words: contract, Willis, Scott & Linton In paragraph 4, we find the key words: “To carry out construction, Willis chose a new shipbuilding firm, Scott & Linton, and ensured that the contract with them put him in a very strong position. In the end, the firm was forced out of business…” To be ‘in a strong position’ means that the contract gave Willis an advantage in the business deal. In other words, the contract favoured Willis so much, that the shipbuilding company had to close before the ship was finished.
– favoured ~ put in a very strong position
The statement is TRUE.
4. JOHN WILLIS WANTED CUTTY SARK TO BE THE FASTEST TEA CLIPPER TRAVELLING BETWEEN THE UK AND CHINA
Key words: Willis, fastest, UK, China At the beginning of paragraph 5, we find some of the key words: Willis, Britain (the UK) and China. “Willis’s company was active in the tea trade between China and Britain, where speed could bring ship owners both profits and prestige, so Cutty Sark was designed to make the journey more quickly than any other ship”. So the idea of Willis was that Cutty Sark would transport the tea between China and the UK faster than any other ship.
– the fastest tea clipper ~ more quickly than any other ship.
The statement is TRUE.
5. DESPITE STORM DAMAGE, CUTTY SARK BEAT THERMOPYLAE BACK TO LONDON
Key words: storm damage, beat Thermopylae, London
We need to find information on the race from China to London between these tea clippers. At the end of paragraph 5, we learn that: “…in 1872, the ship and a rival clipper, Thermopylae, left port in China on the same day…” Although Cutty Sark gained a lead, she was damaged: “…but then her rudder was severely damaged in stormy seas…Cutty Sark reached London a week afterThermopylae”.
Cutty Sark was damaged by a storm, so she only reached London after Thermopylae. The statement is FALSE.
6. THE OPENING OF THE SUEZ CANAL MEANT THAT STEAM SHIPS COULD TRAVEL BETWEEN BRITAIN AND CHINA FASTER THAN CLIPPERS
Key words: Suez Canal, steam ships, faster The key words are found at the beginning of paragraph 6: “Steam ships posed a growing threat to clippers, as their speed and cargo capacity increased. In addition, the opening of the Suez Canal in 1869…had a serious impact”. The writer then explains why only steam ships could make use of the Suez Canal, and this meant that the steam ships could make the journey faster than clippers, using this short route: “Steam ships reduced the journey time between Britain and China by approximately two months”.
– travel faster ~ reduced the journey time
The statement is TRUE.
7. STEAM SHIPS SOMETIMES USED THE OCEAN ROUTE TO TRAVEL BETWEEN LONDON AND CHINA
Key words: ocean route, London and China Although the writer says in paragraph 6 that only steam ships were able to use the Suez Canal, there is no information whether steam ships sometimes chose to make the journey between London and China using the longer ocean route. The statement is NOT GIVEN.
8. CAPTAIN WOODGET PUT CUTTY SARK AT RISK OF HITTING AN ICEBERG
Key words: Captain Woodget, risk, iceberg Captain Woodget is mentioned in paragraph 8. An excellent navigator, he took Cutty Sark on a route travelling a long way south to take advantage of the winds: “…Woodget took her further south than any previous captain, bringing her dangerously close to icebergs off the southern tip of South America. His gamble paid off, though, and the ship was the fastest vessel in the wool trade for ten years”. So, Woodget took a risk by travelling this southern route, close to icebergs. However, he was successful.
– risk = gamble – put Cutty Sark at risk of hitting an iceberg ~ bringing her dangerously close to icebergs
The statement is TRUE.
QUESTIONS 9-13: COMPLETE THE SENTENCES BELOW.
9. AFTER 1880, CUTTY SARK CARRIED ………….. AS ITS MAIN CARGO DURING ITS MOST SUCCESSFUL TIME
Key words: 1880, cargo, most successful Looking for the key words, we find these in paragraph 7. In 1880, two captains of the ship lost their jobs. Then, a new captain was appointed: “This marked a turnaround and the beginning of the most successful period in Cutty Sark’s working life, transporting wool from Australia to Britain”. Thus, after 1880 the ship had its most successful period, carrying wool.
– carry = transport
– time ~ period
The answer is wool.
10. AS A CAPTAIN AND ……………… , WOODGET WAS VERY SKILLED
Key words: captain, Woodget, skilled The key words are in paragraph 8: “The ship’s next captain, Richard Woodget, was an excellent navigator, who got the best out of both his ship and his crew”. The writer, therefore, tells us that Woodget was a good captain and a skilled navigator. The answer is navigator.
11. FERREIRA WENT TO FALMOUTH TO REPAIR DAMAGE THAT A ………… HAD CAUSED
Key words: Ferreira, Falmouth, repair In paragraph 9, we find a reference to the Ferreira. The Cutty Sark “…was sold to a Portuguese firm, which renamed her Ferreira”. In paragraph 10, we learn what caused the damage: “Badly damaged in a gale in 1922, she was put into Falmouth harbour, in southwest England, for repairs”. A gale (= a strong, stormy wind) damaged the ship. The answer is gale.
12. BETWEEN 1923 AND 1954, CUTTY SARK WAS USED FOR …………….
Key words: 1923, 1954, used In paragraph 10, we learn that the ship returned to Falmouth one year after it was repaired: “…the ship returned to Falmouth the following year (= 1923) and had her original name restored”. Then in paragraph 11, we learn what happened between 1923 and 1954. The new owner, a man named Dowman: “…used Cutty Sark as a training ship, and she continued in this role after his death. When she was no longer required, in 1954, she was transferred to dry dock at Greenwich to go on public display”. So, between these years, the ship was used for training. The answer is training.
13. CUTTY SARK HAS TWICE BEEN DAMAGED BY ……………. IN THE 21ST CENTURY
Key words: twice, damaged, 21st century
In the final paragraph, we find the most recent information about the ship in the 21st century: “The ship suffered from fire in 2007, and again, less seriously, in 2014….”
– damaged by ~ suffered from
The answer is fire.
PASSAGE 2: SAVING THE SOIL
QUESTIONS 14-17: COMPLETE THE SUMMARY BELOW.
14. HEALTHY SOIL CONTAINS A LARGE VARIETY OF BACTERIA AND OTHER MICROORGANISMS, AS WELL AS PLANT REMAINS AND……………
Key words: healthy, bacteria, microorganisms, plant remains We need to find information on the contents of healthy soil, using the key words. We find these words in the first part of paragraph B: “A single gram of healthy soil might contain 100 million bacteria, as well as other microorganisms such as viruses and fungi, living amid decomposing plants and various minerals”.
Thus, we have a list of the things which healthy soil contains – bacteria, microorganisms, plant remains and minerals.
– plant remains = decomposing plants
The answer is minerals.
15. IT PROVIDES US WITH FOOD AND ALSO WITH ANTIBIOTICS, AND ITS FUNCTION IN STORING …………… HAS A SIGNIFICANT EFFECT ON THE CLIMATE.
Key words: food, antibiotics, storing, climate The second part of paragraph B gives us the answer: “…soils do not just grow our food, but are the source of nearly all our existing antibiotics, and could be our best hope in the fight against antibiotic-resistant bacteria. Soil is also an ally against climate change: as microorganisms within soil digest dead animals and plants, they lock in their carbon content, holding three times the amount of carbon as does the entire atmosphere”. In other words, soil holds carbon, preventing its release into the atmosphere and so helping to prevent global warming.
– provides us with ~ are the source of – store = lock in – a significant effect on the climate ~ an ally against climate change.
The answer is carbon.
16. IN ADDITION, IT PREVENTS DAMAGE TO PROPERTY AND INFRASTRUCTURE BECAUSE IT HOLDS …………….
Key words: prevents, damage, property and infrastructure, holds Continuing to look for key words in paragraph B, we find the answer: “Soils also storewater, preventing flood damage: in the UK, damage to buildings, roads and bridges from floods caused by soil degradation costs £233 million every year”.
Soils hold water. This reduces the problem of flooding and the damage which is caused by flooding.
– hold = store – buildings, roads and bridges ~ property and infrastructure
The answer is water.
17. THE MAIN FACTOR CONTRIBUTING TO SOIL DEGRADATION IS THE ……………… CARRIED OUT BY HUMANS
Key words: main factor, degradation, humans We find the answer in paragraph C: “Agriculture is by far the biggestproblem……Humans tend not to return unused parts of harvested crops directly to the soil to enrich it, meaning that the soil gradually becomes less fertile”.
So, agriculture is the biggest problem. The way that it is practiced/carried out means that the soil becomes less fertile.
– main factor ~ biggest problem – soil degradation ~ the soil gradually becomes less fertile
The answer is agriculture.
QUESTIONS 18-21: COMPLETE EACH SENTENCE WITH THE CORRECT ENDING, A-F
18. NUTRIENTS CONTAINED IN THE UNUSED PARTS OF HARVESTED CROPS
Key words: nutrients, unused, harvested crops We find these key words in the second part of paragraph C: “…when the plants die and decay these nutrients are returned directly to the soil. Humans tend not to return unused parts of harvested crops directly to the soil to enrich it, meaning that the soil gradually becomes less fertile”. Ending C gives us the following sentence: ‘Nutrients contained in the unused parts of harvested crops may not be put back into the soil’.
– may not be put back ~ tend not to return
Therefore, the answer is C.
19. SYNTHETIC FERTILISERS PRODUCED WITH THE HABER-BOSCH PROCESS
Key words: synthetic fertilisers, Haber-Bosch Paragraph D contains these key words: “A solution came in the early 20th century with the Haber-Bosch process for manufacturing ammonium nitrate. Farmers have been putting this synthetic fertiliser on their fields ever since.” Continuing to read, we find out the problems of using these synthetic fertilisers: “Chemical fertilisers can release polluting nitrous oxide into the atmosphere and excess is often washed away with rain, releasing nitrogen into rivers. More recently, we have found that indiscriminate use of fertilisers hurts the soil itself, turning it acidic and salty…” Ending E gives us the following sentence: ‘Synthetic fertilisers produced with the Haber-Bosch process may cause damage to different aspects of the environment’. These different aspects are the atmosphere, rivers and the soil.
– damage =hurt
The answer is E.
20. ADDITION OF A MIXTURE DEVELOPED BY PIUS FLORIS TO THE SOIL
Key words: addition, mixture, Pius Floris The name Pius Floris is mentioned in paragraph E. He “…developed a cocktail of beneficial bacteria, fungi and humus”. Researchers then “…used this cocktail on soils destroyed by years of fertiliser overuse. When they applied Floris’s mix to the desert-like plots, a good crop of plants emerged that were not just healthy at the surface, but had roots strong enough to pierce dirt as hard as rock. The few plants that grew in the control plots, fed with traditional fertilisers, were small and weak”. Ending A gives us the following sentence: ‘Addition of a mixture developed by Pius Floris to the soil may improve the number and quality of plants growing there’. This is exactly what took place on the plots (= the soil) to which Floris’s mixture/mix was added – more plants grew there, and the plants were stronger.
– mixture = cocktail
The answer is A.
21. THE IDEA OF ZERO NET SOIL DEGRADATION
Key words: idea, zero, degradation In paragraph G, we find a reference to ‘zero net land degradation’. It is a goal which policy- makers can easily understand, like “…the idea of carbon neutrality”. Scientists have therefore proposed this goal to “…shape expectations and encourage action”: “We need ways of presenting the problem that bring it home to governments and the wider public’, says Pamela Chasek at the International Institute for Sustainable Development, in Winnipeg, Canada”. Ending D gives us the following sentence: ‘The idea of zero net soil degradation may help governments to be more aware of soil-related issues”.
– be more aware of soil-related issues ~ bring the problem home to governments
The answer is D.
QUESTIONS 22-26: READING PASSAGE 2 HAS SEVEN PARAGRAPHS, A-G.
22. A REFERENCE TO ONE PERSON’S MOTIVATION FOR A SOIL-IMPROVEMENT PROJECT
Key words: motivation, soil-improvement project In paragraph E, Pius Floris is mentioned. His motivation to improve the soil came from “…running a tree-care business in the Netherlands”. The writer tells us that: “He came to realise that the best way to ensure his trees flourished was to take care of the soil, and has developed a cocktail of beneficial bacteria, fungi and humus to do this”. Therefore, the ‘one person’ referred to is Pius Floris. The answer is E.
23. AN EXPLANATION OF HOW SOIL STAYED HEALTHY BEFORE THE DEVELOPMENT OF FARMING
Key words: explanation, soil, healthy, before, farming We find the answer in paragraph C: “Humans tend not to return unused parts of harvested crops directly to the soil to enrich it, meaning that the soil gradually becomes less fertile. In the past we developed strategies to get around the problem, such as regularly varying the types of crops grown, or leaving fields uncultivated for a season”. So, two different strategies are described to explain how – before farming became very developed – the problem of keeping the soil healthy was solved. The answer is C.
24. EXAMPLES OF DIFFERENT WAYS OF COLLECTING INFORMATION ON SOIL DEGRADATION
Key words: ways, collecting information, soil degradation In paragraph F, we learn that: “…the UN has created the Global Soil Map Project. Researchers from nine countries are working together to create a map linked to a database that can be fed measurements from field surveys, drone surveys, satellite imagery, lab analyses and so on to provide real-time data on the state of the soil”. Several different ways of collecting information (measurements) are given as examples of ways to determine the state of the soil, and how much it has been degraded.
– information ~ real-time data
The answer is F.
25. A SUGGESTION FOR A WAY OF KEEPING SOME TYPES OF SOIL SAFE IN THE NEAR FUTURE
Key words: soil, safe, near future
In the final paragraph, we find the following statement: “Several researchers are agitating for the immediate creation of protected zones for endangered soils”. The suggestion of the researchers is to keep some soil types safe by creating protected zones.
– keeping some types of soil safe ~ creation of protected zones
– the near future = immediate
The answer is G.
26. A REASON WHY IT IS DIFFICULT TO PROVIDE AN OVERVIEW OF SOIL DEGRADATION
Key words: difficult, overview, soil degradation We find the answer in paragraph F: “To assess our options on a global scale we first need an accurate picture of what types of soil are out there, and the problems they face. That’s not easy. For one thing, there is no agreed international system for classifyingsoil”. Therefore, we need to have an accurate picture of soil types and the dangers to them. The reason that is difficult is that we have no agreed way of doing this.
– overview = accurate picture
– difficult ~ not easy – a reason ~ for one thing
The answer is F.
PASSAGE 3: BOOK REVIEW
QUESTIONS 27-29: CHOOSE THE CORRECT LETTER, A, B, C, OR D
27. WHAT IS THE REVIEWER’S ATTITUDE TO ADVOCATES OF POSITIVE PSYCHOLOGY?
A. They are wrong to reject the ideas of Bentham B. They are over-influenced by their study of Bentham’s theories C. They have a fresh new approach to ideas on human happiness
D. They are ignorant about the ideas they should be considering Key words: attitude, advocates, positive psychology In paragraph 1, the reviewer introduces the beliefs of the ‘advocates of positive psychology’. At the beginning of paragraph 2, we find the reviewer’s opinion of these beliefs: “It is an astonishingly crude and simple-minded way of thinking, and for that very reason increasingly popular. Those who think in this way are oblivious to the vast philosophical literature in which the meaning and value of happiness have been explored, and write as if nothing of anyimportance had been thought on the subject until it came to their attention”. The attitude of the reviewer is that advocates of positive philosophy are completely ignorant of all that has been thought and written about happiness by earlier thinkers.
– ignorant about = oblivious to
The answer is D.
28. THE REVIEWER REFERS TO THE GREEK PHILOSOPHER ARISTOTLE IN ORDER TO SUGGEST THAT HAPPINESS
A. may not be just pleasure and the absence of pain B. should not be the main goal of humans
C. it is not something which should be fought for D. is not just an abstract concept Key words: Greek, Aristotle Also in paragraph 2, we find a reference to Aristotle: “For Bentham it was obvious that the human good consists of pleasure and the absence of pain. The Greek philosopher Aristotle may have identified happiness with self-realisation in the 4th century BC and thinkers throughout the ages may have struggled to reconcile the pursuit of happiness with other human values”.
Thus, the reviewer, contrasts the views of Bentham with those of Aristotle. For Aristotle, happiness was not simply the experience of pleasure and the absence of pain – it also consisted of ideas such as self-realisation. The answer is A.
29. ACCORDING TO DAVIES, BENTHAM’S SUGGESTION FOR LINKING THE PRICE OF GOODS TO HAPPINESS WAS SIGNIFICANT BECAUSE
A. it was the first successful way of assessing happiness B. it established a connection between work and psychology
C. it was the first successful example of psychological research
D. it involved consideration of the rights of consumers Key words: linking, price, significant
In paragraph 4, Davies writes about Bentham’s views on the connection between price and pleasure/happiness: “…if two different goods have the same price, it can be concluded that they produce the same quantity of pleasure in the consumer….. By associating money so closely to inner experience, Davies writes, Bentham ‘set the stage for the entangling of psychological research and capitalism that would shape the business practices of the twentieth century”.
– linking the price of goods to happiness ~ associating money so closely to inner experience
– linking = associating
– a connection between work and psychology ~ the entangling of psychological research and capitalism
– work ~ capitalism/business
– was significant ~ set the stage for
The answer is B.
QUESTIONS 30-34: COMPLETE THE SUMMARY USING THE LIST OF WORDS, A-G, BELOW:
30. IN THE 1790S HE SUGGESTED A TYPE OF TECHNOLOGY TO IMPROVE ………….. FOR DIFFERENT GOVERNMENT DEPARTMENTS.
Key words: 1790s, technology, improve, government departments In paragraph 3, Davies writes about Bentham’s active interest in other areas, outside philosophy. “In the 1790s, he wrote to the Home Office suggesting that the departments of government be linked together through a set of ‘conversation tubes’…..”
In other words, these ‘conversation tubes’ would ‘link together’ government departments, and improve communication between them.
– conversation ~ communication
The answer is F.
31. HE DEVELOPED A NEW WAY OF PRINTING BANKNOTES TO INCREASE………..
Key words: printing banknotes, increase. The reference to ‘printing’ and ‘banknotes’ is also in paragraph 3. Bentham suggested a design to the Bank of England: “…for a printing device that could produce unforgeable banknotes”. If banknotes cannot be forged, then the purpose is to make them more difficult to copy by criminals. This will increase security. The answer is B.
32. …AND ALSO DESIGNED A METHOD FOR THE ……………… OF FOOD.
Key words: method, food In paragraph 3, we learn that Bentham “…drew up plans for a ‘frigidarium’ to keepprovisions such as meat, fish, fruit and vegetables fresh”. Thus, in order to keep food fresh, the frigidarium was designed to preserve food in cold storage.
– designed ~ drew up plans
– food = provisions
The answer is G.
33. HE ALSO DREW UP PLANS FOR A PRISON WHICH ALLOWED THE …………….. OF PRISONERS AT ALL TIMES, AND BELIEVED THE SAME DESIGN COULD BE USED FOR OTHER INSTITUTIONS AS WELL.
Key words: prison, same design, other institutions The writer continues in paragraph 3: “His celebrated design for a prison to be known as a ‘Panopticon’, in which prisoners would be kept in solitary confinement while beingvisible at all times to the guards, was very nearly adopted”. The writer tells us that this ‘Panopticon’ was also designed as an instrument of control that could be used in schools and factories, not only prisons. As the prisoners were visible to the guards, the guards would be able to observe the prisoners at all times. The word required is ‘observable’.
The answer is E.
34. WHEN RESEARCHING HAPPINESS, HE INVESTIGATED POSSIBILITIES FOR ITS …………. , AND SUGGESTED SOME METHODS OF DOING THIS.
Key words: researching, possibilities, methods At the beginning of paragraph 4, the writer tells us: “Bentham was also a pioneer of the ‘science of happiness’. If happiness is to be regarded as a science, it has to be measured, and Bentham suggested two ways in which this might be done”.
– possibilities ~ ways in which this might be done
– methods = ways
Thus, Bentham suggested ways in which to measure happiness. The word required is ‘measurement’. The answer is A.
QUESTIONS 35-40: DO THE FOLLOWING STATEMENTS AGREE WITH THE CLAIMS OF THE WRITER IN READING PASSAGE 3?
35. ONE STRENGTH OF THE HAPPINESS INDUSTRY IS ITS DISCUSSION OF THE RELATIONSHIP BETWEEN PSYCHOLOGY AND ECONOMICS
Key words: strength, relationship, psychology and economics At the beginning of paragraph 5, we are told about this book in terms of psychology and economics: “The Happiness Industry describes how the project of a science of happiness has become integral to capitalism. We learn much that is interesting about how economic problems are being redefined and treated as psychological maladies”.
So, this book discusses how, in capitalist societies, an attempt has been made to consider economic problems as simply psychological problems. The book is interesting because it shows how this has been done by writers trying to make a ‘science of happiness’. In other words, this is one strong point of the book. The answer is YES.
36. IT IS MORE DIFFICULT TO MEASURE SOME EMOTIONS THAN OTHERS
Key words: more difficult, measure, emotions
The only reference in the passage to measurement and emotions is in paragraph 5. Here, we only learn that: “In addition, Davies shows how the belief that inner states of pleasure and displeasure can be objectively measured has informed management studies and advertising”. There is no information about the measurement of different emotions and how such measurements can be compared.
– emotions = inner states
The answer is NOT GIVEN.
37. WATSON’S IDEAS ON BEHAVIOURISM WERE SUPPORTED BY RESEARCH ON HUMANS HE CARRIED OUT BEFORE 1915.
Key words: Watson, behaviourism, humans, before 1915. The ideas of Watson are discussed in paragraph 5. “The tendency of thinkers such as J.B. Watson, the founder of behaviourism, was that human beings could be shaped, or manipulated, by policymakers and managers. Watson had no basis for his view of human action. When he became president of the American Psychological Association in 1915 he ‘had never even studied a single human being’: his research had been confined to experiments on white rats”.
Thus, before 1915, Watson had conducted no research on humans, only on white rats. The answer is NO.
38. WATSON’S IDEAS HAVE BEEN MOST INFLUENTIAL ON GOVERNMENTS OUTSIDE AMERICA
Key words: Watson, influential, outside America The influence of Watson’s ideas are discussed in paragraph 5. “…Watson’s reductive model is now widely applied, with ‘behaviour change’ becoming the goal of governments”. Although the writer then continues, giving the example of Britain, there is no reference to Watson’s ideas becoming most influential on governments outside America – we only know that his ideas are ‘widely applied’. The answer is NOT GIVEN.
39. THE NEED FOR HAPPINESS IS LINKED TO INDUSTRIALISATION
Key words: need, linked, industrialisation In the last paragraph, the writer states: “Modern industrial societies appear to need the possibility of ever-increasing happiness to motivate them in their labours”. Thus, the need for more and more happiness is linked to industrial societies and motivation to work.
– industrialisation ~ industrial societies
The answer is YES.
40. A MAIN AIM OF GOVERNMENT SHOULD BE TO INCREASE THE HAPPINESS OF THE POPULATION
Key words: aim, government, increase, population It is stated in the last paragraph that: “…whatever its intellectual pedigree, the idea that governments should be responsible for promoting happiness is always a threat to human freedom”. The writer believes that if governments take responsibility for increasing the happiness of the population, then people will lose their freedom. The writer is definitely against this aim.
Cambridge IELTS 13 is the latest IELTS exam preparation.https://draftsbook.com/ will help you to answer all questions in cambridge ielts 13 reading test 3 with detail explanations.
PASSAGE 1: THE COCONUT PALM
QUESTIONS 1-8: COMPLETE THE TABLE BELOW.
1.TRUNK – TIMBER FOR HOUSES AND THE MAKING OF……….
Key words: trunk, timber, houses, making Looking for the key words, we find the reference to the trunk and its uses in paragraph 2. The writer says that: “This is an important source of timber for building houses, and is increasingly being used as a replacement for endangered hardwoods in the furnitureconstruction industry”. Thus, the trunk is used to build houses and also to make furniture.
– making = construction
The answer is furniture.
2. FLOWERS – STEMS PROVIDE SAP, USED AS A DRINK OR A SOURCE OF ……….
Key words: flowers, sap, drink, source Coconut flowers are also mentioned in paragraph 2: “The flower stems may be tapped for their sap to produce a drink, and the sap can also be reduced by boiling to produce atype of sugar used for cooking”. Thus, the sap from the flower stems can be used as a drink or to boil and make a kind of sugar.
The answer is sugar.
3. FRUITS – MIDDLE LAYER (COIR FIBRES) USED FOR ………. , ETC
Key words: fruits, middle, coir fibres Look for the information relating to fruits, and we find this in paragraph 3: “The thick fibrous middle layer produces coconut fibre, coir, which has numerous uses and isparticularly important in manufacturing ropes”. So, the fibre from the middle layer, coir, is used to make ropes. The answer is ropes.
4. FRUITS – INNER LAYER (SHELL): A SOURCE OF ……….
Key words: inner, shell, source At the end of paragraph 3, the uses of the ‘woody inner layer’ of coconut shells are described: “An importantproduct obtained from the shell is charcoal, which is widely used in various industries…” The inner layer of the shell, therefore, provides charcoal for industries and also for cooking. The answer is charcoal.
5. FRUITS – INNER LAYER (SHELL): WHEN HALVED USED FOR ……….
Key words: inner, shell, halved As we continue reading paragraph 3, the other use of the inner layer – the shell – is mentioned: “When broken in half, the shells are also used as bowls in many parts of Asia”. Halves of shells are used as bowls.
– halved = broken in half
The answer is bowls.
6. FRUITS – COCONUT WATER: A SOURCE OF ………. FOR OTHER PLANTS
Key words: coconut water, source, other plants In paragraph 4, we find the uses of coconut water: “…coconut water, which is enjoyed as a drink but also provides the hormones which encourage other plants to grow more rapidly and produced higher yields”. The coconut water provides hormones for other plants, therefore it is a source of hormones for those plants. The answer is hormones.
7. FRUITS – COCONUT FLESH: OIL AND MILK FOR COOKING AND ……….
Key words: coconut flesh, oil, milk, cooking The author continues in paragraph 4: “Dried coconut flesh, copra, is made into coconut oil and coconut milk, which are widely used in cooking in different parts of the world, as well as in cosmetics”. Thus, coconut oil and milk are used for cooking and for making cosmetics. The answer is cosmetics.
Key words: coconut flesh, glycerine, ingredient It is also stated in paragraph 4 that: “A derivative of coconut fat, glycerine, acquired strategic importance in a quite different sphere, as Alfred Nobel introduced the world to his nitroglycerine-based invention: dynamite”. ‘Nitroglycerine-based means that glycerine was one of the basic ingredients. Nobel’s invention was dynamite. The answer is dynamite.
QUESTIONS 9-13: DO THE FOLLOWING STATEMENTS AGREE WITH THE INFORMATION GIVEN IN READING PASSAGE 1?
9. COCONUT SEEDS NEED SHADE IN ORDER TO GERMINATE
Key words: seeds, shade, germinate These key words can be found in paragraph 5. There, the writer tells us how coconut seeds germinate: “Literally cast onto desert island shores, with little more than sand to grow in and exposed to the full glare of the tropical sun, coconut seeds are able togerminate and root”. ‘Glare’ means to shine with a very bright and unpleasant light – we often wear sunglasses to protect against the glare of the sun. It is the opposite of the shade. So, coconut seeds do not need shade in order to germinate, they can germinate in the sun. The statement is FALSE.
10. COCONUTS WERE PROBABLY TRANSPORTED TO ASIA FROM AMERICA IN THE 16TH CENTURY
Key words: transported, Asia, America, 16th century In the last paragraph, the writer tells us about the origins of coconuts. “16th century trade and human migration patterns reveal that Arab traders and European sailors are likely to have moved coconuts from South and Southeast Asia to Africa and then acrossthe Atlantic to the east coast of America”. This sentence tells us that coconuts were probably moved from Asia to America – via Africa. This route is the opposite of the statement.
– probably = likely – transported = moved
The statement is FALSE.
11. COCONUTS FOUND ON THE WEST COAST OF AMERICA WERE A DIFFERENT TYPE FROM THOSE FOUND ON THE EAST COAST
Key words: west coast, America, different, east coast In the last paragraph, the writer simply tells us that: “In America, there are close coconut relatives, but no evidence that coconuts are indigenous”. Thus, we do not know if the coconuts on the west and east coasts of America are different. The statement is NOT GIVEN.
12. ALL THE COCONUTS FOUND IN ASIA ARE CULTIVATED VARIETIES.
Key words: all, Asia, cultivated This information is also given in the last paragraph: “In Asia there is a large degree of coconut diversity and evidence of millennia of human use – but there are no relativesgrowing in the wild”. As there are no wild coconuts growing in Asia, all the varieties must be cultivated.
– varieties = relatives
The statement is TRUE.
13. COCONUTS ARE CULTIVATED IN DIFFERENT WAYS IN AMERICA AND THE PACIFIC.
The key words are also found in the last paragraph. Here, it is stated that: “In America there are close coconut relatives, but no evidence that coconuts are indigenous. These problems have led to the intriguing suggestion that coconuts originated on coral islands in the Pacific and were dispersed from there”.
Thus, the only information given here is that the origins of coconuts are not known for certain, but nothing is stated about the methods of cultivation, either in America or the Pacific. The statement is NOT GIVEN.
PASSAGE 2: HOW BABY TALK GIVES INFANT BRAINS A BOOST
QUESTIONS 14-17: LOOK AT THE FOLLOWING IDEAS (QUESTIONS 14-17) AND THE LIST OF RESEARCHERS BELOW.
14. THE IMPORTANCE OF ADULTS GIVING BABIES INDIVIDUAL ATTENTION WHEN TALKING TO THEM
Key words: adults, babies, individual attention, talking In paragraph D, the author writes about the study of Nairan Ramirez-Esparza. She says: “We also found that it really matters whether you use baby talk in a one-on-one context…The more parents use baby talk one-on-one, the more babies babble, and the more they babble, the more words they produce later in life”. A ‘one-on-one context’ means a situation in which the parent is alone with the baby, talking to the baby and giving it individual attention.
– importance ~ it really matters
– individual = one-on-one
The answer is B.
15. THE CONNECTION BETWEEN WHAT BABIES HEAR AND THEIR OWN EFFORTS TO CREATE SPEECH
Key words: connection, hear, efforts, speech
In paragraph F, the author refers to a study in which Patricia Kuhl took part: “The results suggest that listening to baby talk prompts infant brains to start practicing their language skills”. Thus, when babies listen to (= hear) baby talk, this stimulates their brains to try to practice their own language skills. The passage continues: “Finding activation in the motor areas of the brain when infants are simply listening is significant, because it means the baby brain is engaged in trying to talk back right from the start, and suggests that seven-month-olds’ brains are already trying to figure out how to make the right movements that will produce words”.
– create speech = produce words
The answer is C.
16. THE ADVANTAGE FOR THE BABY OF HAVING TWO PARENTS EACH SPEAKING IN A DIFFERENT WAY
Key words: advantage, two parents, different way In paragraph C, the author tells us about the study of Mark VanDam. He found that mothers and fathers (the two parents) each spoke to children in a different way: “The idea is that a kid gets to practice a certain kind of speech with mom and another kind of speech with dad, so the kid then has a wider repertoire of kinds of speech to practice”. The advantage for the baby when parent speak in these different ways, is that it grows up having a wider range (= repertoire) of kinds of speech, which it can then practice.
– a different way ~ another kind
The answer is A.
17. THE CONNECTION BETWEEN THE AMOUNT OF BABY TALK BABIES HEAR AND HOW MUCH VOCALISING THEY DO THEMSELVES
Key words: connection, amount of baby talk, vocalising In the middle of paragraph D, the author writes about a study which found that “…the more baby talk parents used, the more their youngsters began to babble”. Nairan Ramirez-Esparza adds: “Those children who listened to a lot of baby talk were talking more than the babies that listened to more adult talk or standard speech”.
She found, therefore, that there is a connection between the amount of baby talk which babies listened to, and how much talking the babies did.
– vocalising = babble/ talking
The answer is B.
QUESTIONS 18-23: COMPLETE THE SUMMARY.
18. RESEARCHERS AT WASHINGTON STATE UNIVERSITY USED ………………….. , TOGETHER WITH SPECIALISED COMPUTER PROGRAMS, TO ANALYSE HOW PARENTS INTERACTED WITH THEIR BABIES DURING A NORMAL DAY.
Key words: Washington State University, computer programs, interacted, normal day We find a reference to Washington State University in paragraph C. “Mark VanDam of Washington State University at Spokane and colleagues equipped parents with recording devices and speech-recognition software to study the way they interacted with their youngsters during a normal day”.
19. THE STUDY REVEALED THAT ……………….. TENDED NOT TO MODIFY THEIR ORDINARY SPEECH PATTERNS WHEN INTERACTING WITH THEIR BABIES.
Key words: not modify, speech patterns, interacting Also in paragraph C, VanDam explains: “Dads didn’t raise their pitch or fundamental frequency when they talked to kids”.
In other words, fathers spoke to their babies in a similar way that they would speak normally. Their ‘pitch and fundamental frequency’ refers to the ‘ordinary speech patterns’ which fathers use to talk to their babies.
– interacting with ~ talked to
– babies ~ kids
The answer is dads/fathers.
20. ACCORDING TO AN IDEA KNOWN AS THE ……………….. , THEY MAY USE A MORE ADULT TYPE OF SPEECH TO PREPARE INFANTS FOR THE LANGUAGE THEY WILL HEAR OUTSIDE THE FAMILY HOME.
Key words: idea, adult, speech, prepare, language, outside Continuing with the findings of the study in paragraph C, the author says of fathers: “Their role may be rooted in what is called the bridge hypothesis, which dates back to 1975. It suggests that fathers use less familiar language to provide their children with a bridge to the kind of speech they’ll hear in public”.
So, the author suggests that fathers may use ‘less familiar’ (= more adult) language to talk to their babies, which helps to prepare these infants for what they will hear when they are not in the family home.
– idea = hypothesis – language = speech – outside the family home ~ in public
The answer is bridge hypothesis.
21. ACCORDING TO THE RESEARCHERS, HEARING BABY TALK FROM ONE PARENT AND ‘NORMAL’ LANGUAGE FROM THE OTHER EXPANDS THE BABY’S ………………. OF TYPES OF SPEECH WHICH THEY CAN PRACTICE.
Key words: normal language, expands, types of speech We find the answer at the end of paragraph C. We know from the previous question that fathers speak to babies using less ‘baby talk’ and more normal speech, using adult language. “The idea is that a kid gets to practice a certain kind of speech with mom and another kind of speech with dad, so the kid then has a wider repertoire of kinds ofspeech to practice’, says VanDam”. A repertoire refers to all the things that a person – in this case, a baby – is able to do. So, the baby is able to practice different kinds of speech with each parent. The answer is repertoire.
22. MEANWHILE ANOTHER STUDY CARRIED OUT BY SCIENTISTS FROM THE UNIVERSITY OF WASHINGTON AND THE UNIVERSITY OF CONNECTICUT RECORDED SPEECH AND SOUND USING SPECIAL …………. THAT THE BABIES WERE EQUIPPED WITH.
Key words: Washington, Connecticut, recorded, equippedIn paragraph D, we find a reference to the University of Washington and the University of Connecticut. This enables us to know where to look for the answer: “Scientists from the University of Washington and the University of Connecticut collected thousands of 30-second conversations between parents and their babies, fitting 26 children withaudio-recording vests that captured language and sound….”Thus, these scientists recorded the language and sounds, using audio-recording vests fitted to the babies.
– recorded = captured The answer is (audio-recording) vests.
23. WHEN THEY STUDIED THE BABIES AGAIN AT AGE TWO, THEY FOUND THAT THOSE WHO HAD HEARD A LOT OF BABY TALK IN INFANCY HAD A MUCH LARGER …………… THAN THOSE WHO HAD NOT.
Key words: age two, babies again, larger We now have to find more information on the study conducted by the scientists mentioned in the previous question. Again, the answer is in paragraph D: “And when researchers saw the same babies at age two, they found that frequent baby talk haddramatically boosted vocabulary….”
At the age of two, babies who had heard a lot of baby talk, had more vocabulary than those who had not heard much baby talk.
– a lot of ~ frequent – had a much larger vocabulary ~ dramatically boosted vocabulary
The answer is vocabulary.
QUESTIONS 24-26: READING PASSAGE 2 HAS SIX PARAGRAPHS, A-F.
24. A REFERENCE TO A CHANGE WHICH OCCURS IN BABIES’ BRAIN ACTIVITY BEFORE THE END OF THEIR FIRST YEAR
Key words: change, brain activity, end of first year The answer is in paragraph F. The author writes about a publication called Proceedings of the National Academy of Sciences. In this publication, a study was reported which was carried out with babies of 7 months and 11.5 months – in other words, before the end of their first year. “The infants were placed in a brain-activation scanner thatrecorded activity in a brain region known to guide the motor movements that produce speech. The results suggest that listening to baby talk prompts infant brains to start practicing their language skills”.
So, listening to baby talk leads to changes in the activity of ‘infant brains’. The answer is F.
25. AN EXAMPLE OF WHAT SOME PARENTS DO FOR THEIR BABY’S BENEFIT BEFORE BIRTH
Key words: example, baby’s benefit, before birth The answer can be found in paragraph A. “Most babies start developing their hearing while still in the womb, prompting some hopeful parents to play classical music to theirpregnant bellies”. Most babies, therefore, start to hear when they are still inside the body of the mother. So, some parents start to play music for these unborn babies to stimulate their hearing.
– before birth ~ still in the womb
The answer is A.
26. A MENTION OF BABIES’ PREFERENCE FOR THE SOUNDS THAT OTHER BABIES MAKE
Key words: preference, sounds, other babies The answer is at the beginning of paragraph E. “Another study suggests that parents might want to pair their youngsters up so they can babble more with their own kind. Researchers from McGill University and Universite du Quebec a Montreal found that babies seem to like listening to each other rather than adults…” More details of this study are given in the paragraph, and these refer specifically to the sounds made by babies: “…the ‘infant’ sounds held babies’ attention nearly 40 percent longer” than the sounds made by adults.
– preference ~ seem to like
The answer is E.
PASSAGE 3: WHATEVER HAPPENED TO THE HARAPPAN CIVILISATION?
QUESTIONS 27-31: READING PASSAGE 3 HAS EIGHT PARAGRAPHS, A-H.
27. PROPOSED EXPLANATIONS FOR THE DECLINE OF THE HARAPPAN CIVILISATION
Key words: explanations, decline Causes for the decline of the Harappan civilisation are found in paragraph C. There are different suggestions or explanations: changes affecting water supply and agriculture, population growth, a breakdown of trade, invasion and even environmental changes related to climate. “It is unlikely that there was a single cause for the decline of the civilisation”.
– explanation = cause
The answer is C.
28. REFERENCE TO A PRESENT-DAY APPLICATION OF SOME ARCHAEOLOGICAL RESEARCH FINDINGS
Key words: present-day application, archaeological, findings The final paragraph relates what we can learn from the archaeological research into the Harappan civilisation to tackle some issues today. “By investigating responses to environmental pressures and threats, we can learn fromthe past to engage with the public, and the relevant governmental and administrative bodies, to be more proactive in issues such as the management and administration of water supply, the balance of urban and rural development, and the importance of preserving cultural heritage in the future”. The answer is H.
29. A DIFFERENCE BETWEEN THE HARAPPAN CIVILISATION AND ANOTHER CULTURE OF THE SAME PERIOD
Key words: difference, another culture, same period The question asks us to look for a comparison between the Harappan civilisation and another particular culture at that same time. The answer is in paragraph A. The people of the Harappan culture did not leave pictures of themselves, “But their lack of self-imagery – at at time when the Eyptians were carving and painting representations of themselves all over their temples – is only part of the mystery”. Thus, a contrast is made between the Harappan civilisation and Egyptian culture at the same period. The answer is A.
30. A DESCRIPTION OF SOME FEATURES OF HARAPPAN URBAN DESIGN
Key words: features, urban design In paragraph B, Dr Cameron Petrie describes Harappan cities. They had: “…great baths, craft workshops, palaces and halls laid out in distinct sectors. Houses were arranged in blocks, with wide main streets and narrow alleyways, and many had their own wells and drainage systems”. All of these are features of urban design – things that we find in the sites of Harappan cities. The answer is B.
31. REFERENCE TO THE DISCOVERY OF ERRORS MADE BY PREVIOUS ARCHAEOLOGISTS
Key words: errors, previous archaeologists In paragraph D, we find several references to the mistakes made by previous archaeologists: “…many of the archaeological sites were not where they were supposedto be, completely altering understanding of the way that this region was inhabited in the past. The new research team “…found inaccuracies in the published geographiclocations of ancient settlements ranging from several hundred metres to many kilometres”. The result was that “…any attempts to usethe existing data were likely tobe fundamentally flawed”. All of these are errors of previous archaeologists, discovered by the research team of Dr Petrie and Dr Singh. The answer is D.
QUESTIONS 32-36: COMPLETE THE SUMMARY BELOW.
32. BY COLLECTING THE …………… OF SNAILS AND ANALYSING THEM, THEY DISCOVERED…..
Key words: collecting, snails, analysing In paragraph E, we find a reference to the research of Yama Dixit and David Hodell. “The researchers gathered shells of Melanoides tuberculata snails from the sediment of an ancient lake and used geochemical analysis as a means of tracing the climate history of the region”. Therefore, the researchers collected and analysed the shells of snails.
– collect = gather
The answer is shells.
33. THEY DISCOVERED EVIDENCE OF A CHANGE IN WATER LEVELS IN A ………….. IN THE REGION
Key words: change, water levels In paragraph E, the author continues: “As today, the major source of water into the lake is likely to have been the summer monsoon’, says Dixit. ‘But we have observed that there was an abrupt change about 4,100 years ago, when the amount of evaporationfrom the lake exceeded the rainfall – indicative of a drought”. About 4,100 years ago, there was a sudden change, when the water level in the lake fell. The answer is lake.
34. THIS OCCURRED WHEN THERE WAS LESS ……………. THAN EVAPORATION, AND SUGGESTS THAT THERE WAS AN EXTENDED PERIOD OF DROUGHT
Key words: less, evaporation, drought In the same sentence in paragraph E, we find the answer. This is the same period “…when the amount of evaporation exceeded the rainfall – indicative of a drought”.
If the evaporation exceeded the rainfall, leading to a drought, this means that there was less rainfall than evaporation. The answer is rainfall.
35. PETRIE AND SINGH’S TEAM ARE USING ARCHAEOLOGICAL RECORDS TO LOOK AT ………….. FROM FIVE MILLENNIA AGO, IN ORDER TO KNOW WHETHER PEOPLE HAD ADAPTED THEIR AGRICULTURAL PRACTICES TO CHANGING CLIMATIC CONDITIONS.
Key words: Petrie, Singh, records, five millenia ago
We find the answer at the beginning of paragraph G. “Petrie and Singh’s team is now examining archaeological records and trying to understand details of how people led their lives in the region five millennia ago. They are analysing grains cultivated at the time and trying to work out whether they were grown under extreme conditions of water stress, and whether they were adjusting the combinations of crops they were growing for different weather systems”.
– look at ~ analyse – adapt = adjust – agricultural practices ~ combinations of crops – changing climatic conditions ~ different weather systems.
The answer is grains.
36. THEY ARE ALSO EXAMINING OBJECTS INCLUDING ……………. , SO AS TO FIND OUT ABOUT LINKS BETWEEN INHABITANTS OF DIFFERENT PARTS OF THE REGION AND WHETHER THESE CHANGED OVER TIME.
Key words: examining objects, links, inhabitants, changed The answer is also in paragraph G. The researchers “…are also looking at whether the types of pottery used, and other aspects of their material culture, were distinctive to specific regions or were more similar across larger areas. This gives us insight into the types of interactive networks that the population was involved in, and whether those changed”.
– look at ~ examine – links = interactive networks
– inhabitants = population
The answer is pottery.
QUESTIONS 37-40: LOOK AT THE FOLLOWING STATEMENTS AND THE LIST OF RESEARCHERS BELOW.
37. FINDING FURTHER INFORMATION ABOUT CHANGES TO ENVIRONMENTAL CONDITIONS IN THE REGION IS VITAL
Key words: changes, environmental conditions, vital We find the answer at the end of paragraph F: “Considering the vast area of the Harappan Civilisation with its variable weather systems’, explains Singh, ‘it is essentialthat we obtain more climate data from areas close to the two great cities at Mohenjodaro and Harappa and also from the Indian Punjab”.
Ravindanath Singh is saying that we must find more climate data about the variable weather systems in the area.
– information = data – changes to environmental conditions ~ variable weather systems
– vital = essential
The answer is B.
38. EXAMINING PREVIOUS PATTERNS OF BEHAVIOUR MAY HAVE LONG-TERM BENEFITS
Key words: previous, behaviour, long-term benefits In the last paragraph, Cameron Petrie’s ideas relate the work of archaeologists to possible benefits today from studying such work. Petrie says that: “By investigating responses to environmental pressures and threats, we can learn from the past to engagewith the public, and the relevant governmental and administrative bodies, to be more proactive in issues such as…..” Petrie believes that the work of archaeologists in investigating how past civilisations responded to environmental challenges, can help us to tackle such problems today. These are the potential long-term benefits.
– examining = investigating – patterns of behaviour ~ responses
The answer is A.
39. ROUGH CALCULATIONS INDICATE THE APPROXIMATE LENGTH OF A PERIOD OF WATER SHORTAGE
Key words: calculations, length, water shortage In paragraph E, Yama Dixit comments on the effects of drought on the drying of a great lake. However, it is David Hodell who comments on the possible length/duration of this drought: “Hodell adds: ‘We estimate that the weakening of the Indian summer monsoon climate lasted about 200 years before recovering to the previous conditions…”
– rough calculations ~ estimate
– approximate ~ about – a period of water shortage ~ weakening of the Indian summer monsoon climate
Therefore, it was David Hodell who made this rough calculation. The answer is D.
40. INFORMATION ABOUT THE DECLINE OF THE HARAPPAN CIVILISATION HAS BEEN LACKING
Key words: decline In paragraph B, Cameron Petrie says: “There is plenty of archaeological evidence to tell us about the rise of the Harappan Civilisation, but relatively little about its fall’, explains archaeologist Dr Cameron Petrie…”
– information ~ evidence decline = fall
As there is not much evidence about the fall/decline of the Harappan Civilisation, we know that this information is lacking. The answer is A.

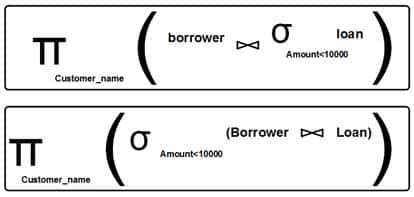
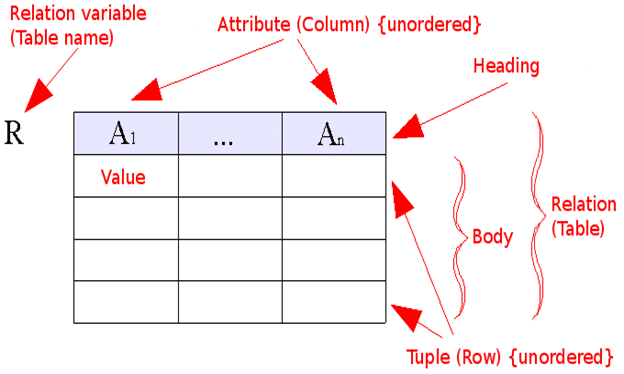
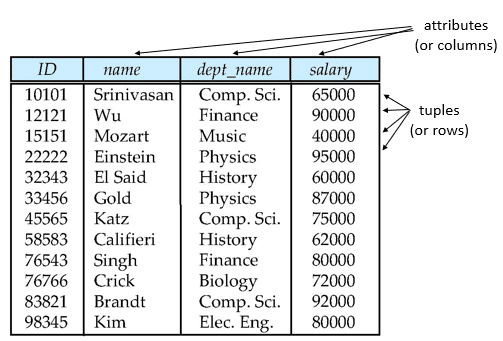
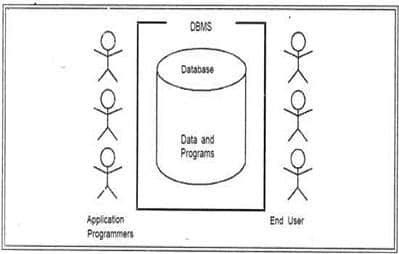
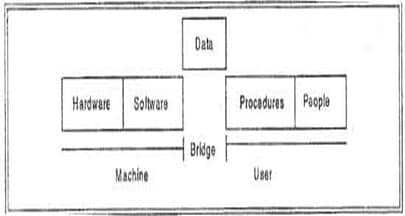
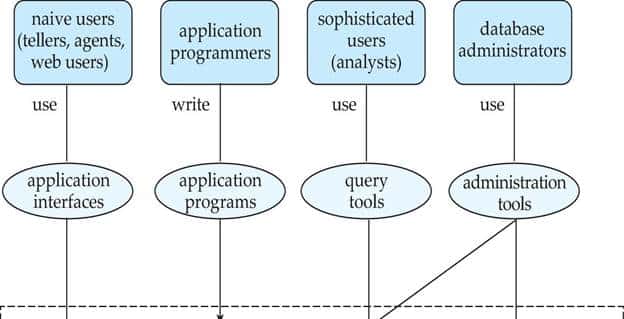
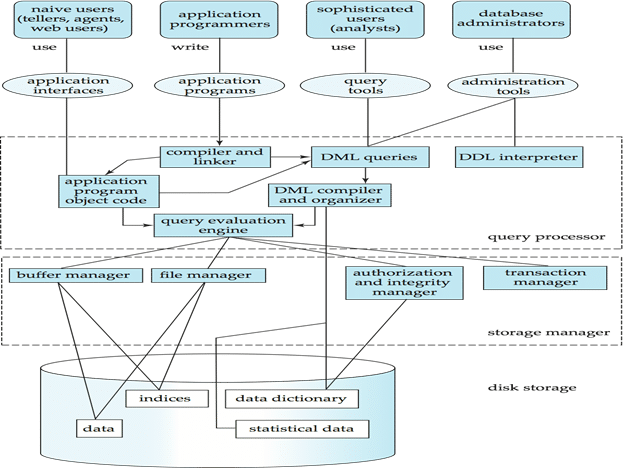
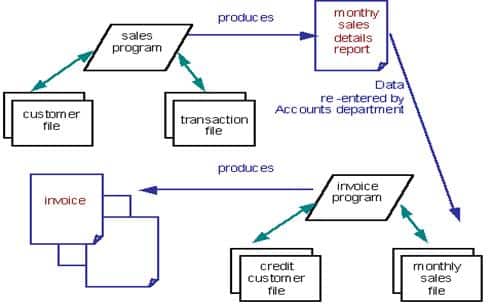




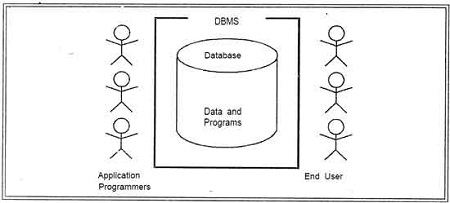{kind=link}
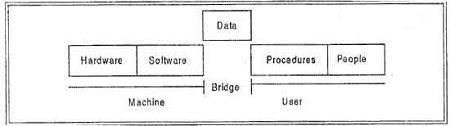{kind=link}