
by Jesmin Akther | Jan 5, 2022 | MIS(Management Information System)
Strategic Business Objectives of MIS
Strategic planning for an organization involves long-term policy decisions, like location of a new plant, a new product, diversification etc.
Strategic planning is mostly influenced by:
- Decision of diversification i.e., expansion or integration of business
- Market dynamics, demand and supply
- Technological changes
- Competitive forces
- Various other threats, challenges and opportunities
Strategic planning sets targets for the workings and references for taking such long-term policy decisions and transforms the business objectives into functional and operational units. Strategic planning generally follows one of the four-way paths:
- Overall Company Strategy
- Growth orientation
- Product orientation
- Market orientation
In this chapter, let us discuss the Strategic Business Objectives of MIS with regards to the following aspects of a business:
- Operational Excellence
- New Products, Services and Business Models
- Services and Business Models
- Customer and Supplier Intimacy
- Improved Decision-making
- Competitive Advantage, and Survival
Operational Excellence
This relates to achieving excellence in business in operations to achieve higher profitability. For example, a consumer goods manufacturer may decide upon using a wide distribution network to get maximum reach to the customers and exposure.
A manufacturing company may pursue a strategy of aggressive marketing and mass production.
New Products, Services, and Business Models
This is part of growth strategy of an organization. A new product or a new service introduced, with a very fast growth potential provides a mean for steady growth business turnover.
With the help of information technology, a company might even opt for an entirely new business model, which will allow it to establish, consolidate and maintain a leadership in the existing market as well as provide a competitive edge in the industry.
For example, a company selling low priced detergent may opt for producing higher range detergents for washing machines, washing soaps, and bath soaps.
It involves market strategies also that includes planning for distribution, advertisement, market research and other related aspects.
Customer and Supplier Intimacy
When a Business really knows their Customers and serves them well, ‘the way they want to be served’, the Customers generally respond by returning and buying more from the firm. It raises revenues and profits.
Likewise with Suppliers, the more a Business engages its Suppliers, the better the Suppliers can provide vital information. This will lower the cost and bring huge improvements in the supply-chain management.
Improved Decision Making
A very important pre-requisite of strategic planning is to provide the right information at the right time to the right person, for making an informed decision.
Well planned Information Systems and technologies make it possible for the decision makers to use real-time data from the marketplace when making informed decisions.
Competitive Advantage and Survival
The following list illustrates some of the strategic planning that provides competitive advantage and survival:
- Planning for an overall growth for the company.
- Thorough market research to understand the market dynamics involving demandsupply.
- Various policies that will dominate the course and movement of business.
- Expansion and diversification to conquer new markets.
- Choosing a perfect product strategy that involves either expanding a family of products or an associated product.
- Strategies for choosing the market, distribution, pricing, advertising, packing, and other market-oriented strategies.
- Strategies driven by industry-level changes or Government regulations.
- Strategies for change management.
System Development Life Cycle (SDLC)
Like any other product development, system development requires careful analysis and design before implementation. System development generally has the following phases:
Planning and Requirement Analysis
The project planning part involves the following steps:
- Reviewing various project requests
- Prioritizing the project requests
- Allocating the resources
- Identifying the project development team
The techniques used in information system planning are:
- Critical Success Factor
- Business System Planning
- End/Mean Analysis
The requirement analysis part involves understanding the goals, processes and the constraints of the system for which the information system is being designed.
It is basically an iterative process involving systematic investigation of the processes and requirements. The analyst creates a blueprint of the entire system in minute details, using various diagramming techniques like:
- Data flow diagrams
- Context diagrams
Requirement analysis has the following sub-processes:
- Conducting preliminary investigation
- Performing detailed analysis activities
- Studying current system
- Determining user requirements
- Recommending a solution
Defining Requirements
The requirement analysis stage generally completes by creation of a ‘Feasibility Report’. This report contains:
- A preamble
- A goal statement
- A brief description of the present system
- Proposed alternatives in details
The feasibility report and the proposed alternatives help in preparing the costs and benefits study.
Based on the costs and benefits, and considering all problems that may be encountered due to human, organizational or technological bottlenecks, the best alternative is chosen by the end-users of the system.
Designing System Architecture
System design specifies how the system will accomplish this objective. System design consists of both logical design and physical design activity, which produces ‘system specification’ satisfying system requirements developed in the system analysis stage.
In this stage, the following documents are prepared:
- Detailed specification
- Hardware/software plan
Building or Developing the System
The most creative and challenging phase of the system life cycle is system design, which refers to the technical specifications that will be applied in implementing the candidate system. It also includes the construction of programmers and program testing.
It has the following stages:
- Acquiring hardware and software, if necessary
- Database design
- Developing system processes
- Coding and testing each module
The final report prior to implementation phase includes procedural flowcharts, record layout, report layout and plan for implementing the candidate system. Information on personnel, money, hardware, facility and their estimated cost must also be available. At this point projected cost must be close to actual cost of implementation.
Testing the System
System testing requires a test plan that consists of several key activities and steps for programs, strings, system, and user acceptance testing. The system performance criteria deals with turnaround time,backup,file protection and the human factors.
Testing process focuses on both:
- The internal logic of the system/software, ensuring that all statements have been tested;
- The external functions, by conducting tests to find errors and ensuring that the defined input will actually produce the required results.
In some cases, a ‘parallel run’ of the new system is performed, where both the current and the proposed system are run in parallel for a specified time period and the current system is used to validate the proposed system.
Deployment of the System
At this stage, system is put into production to be used by the end users. Sometime, we put system into a Beta stage where users’ feedback is received and based on the feedback, the system is corrected or improved before a final release or official release of the system.
System Evaluation and Maintenance
Maintenance is necessary to eliminate the errors in the working system during its working life and to tune the system to any variation in its working environment. Often small system deficiencies are found, as system is brought into operation and changes are made to remove them. System planner must always plan for resources availability to carry on these maintenance functions.
by Jesmin Akther | Jan 5, 2022 | MIS(Management Information System)
MIS Business Continuity Planning (BCP)
Business Continuity Planning BCPBCP or Business Continuity and Resiliency
Planning BCRPBCRP creates a guideline for continuing business operations under adverse conditions such as a natural calamity, an interruption in regular business processes, loss or damage to critical infrastructure, or a crime done against the business.
It is defined as a plan that “identifies an organization’s exposure to internal and external threats and synthesizes hard and soft assets to provide effective prevention and recovery for the organization, while maintaining competitive advantage and value system integrity.”
Understandably, risk management and disaster management are major components in business continuity planning.
Objectives of BCP
Following are the objectives of BCP:
- Reducing the possibility of any interruption in regular business processes using proper risk management.
- Minimizing the impact of interruption, if any.
- Teaching the staff their roles and responsibilities in such a situation to safeguard their own security and other interests.
- Handling any potential failure in supply chain system, to maintain the natural flow of business.
- Protecting the business from failure and negative publicity.
- Protecting customers and maintaining customer relationships.
- Protecting the prevalent and prospective market and competitive advantage of the business.
- Protecting profits, revenue and goodwill.
- Setting a recovery plan following a disruption to normal operating conditions. Fulfilling legislative and regulatory requirements.
Traditionally a business continuity plan would just protect the data center. With the advent of technologies, the scope of a BCP includes all distributed operations, personnel, networks, power and eventually all aspects of the IT environment.
Phases of BCP
The business continuity planning process involves recovery, continuation, and preservation of the entire business operation, not just its technology component. It should include contingency plans to protect all resources of the organization, e.g., human resource, financial resource and IT infrastructure, against any mishap.
It has the following phases:
- Project management & initiation
- Business Impact Analysis BIABIA
- Recovery strategies
- Plan design & development
- Testing, maintenance, awareness, training
Project Management and Initiation
This phase has the following sub-phases:
- Establish need riskanalysisriskanalysis
- Get management support
- Establish team functional,technical,BCC−BusinessContinuityCoordinatorfunctional,technical,BCC−Bus inessContinuityCoordinator
- Create work plan scope, goals, methods, timeline scope, goals, methods, timeline
- Initial report to management
- Obtain management approval to proceed
Business Impact Analysis
This phase is used to obtain formal agreement with senior management for each timecritical business resource. This phase has the following sub-phases:
- Deciding maximum tolerable downtime, also known as MAO Maximum Allowable
Outage Maximum Allowable Outage
- Quantifying loss due to business outage financial,extracostofrecovery,embarrassmentfinancial,extracostofrecovery,embarrassme nt, without estimating the probability of kinds of incidents, it only quantifies the consequences
- Choosing information gathering methods surveys,interviews,softwaretoolssurveys,interviews,softwaretools
- Selecting interviewees
- Customizing questionnaire
- Analyzing information
- Identifying time-critical business functions
- Assigning MTDs
- Ranking critical business functions by MTDs
- Reporting recovery options
- Obtaining management approval
Recovery Phase
This phase involves creating recovery strategies are based on MTDs, predefined and management-approved. These strategies should address recovery of:
- Business operations
- Facilities & supplies
- Users workersandend−usersworkersandend−users
- Network
- Data center technical
- Data off−sitebackupsofdataandapplicationsoff−sitebackupsofdataandapplications
BCP Development Phase
This phase involves creating detailed recovery plan that includes:
- Business & service recovery plans
- Maintenance plan
- Awareness & training plan
- Testing plan
The Sample Plan is divided into the following phases:
- Initial disaster response
- Resume critical business ops
- Resume non-critical business ops
- Restoration return to primary site return to primary site
- Interacting with external groups customers,media,emergencyresponderscustomers,media,emergencyresponders
Final Phase
The final phase is a continuously evolving process containing testing maintenance, and training.
The testing process generally follows procedures like structured walk-through, creating checklist, simulation, parallel and full interruptions.
Maintenance involves:
- Fixing problems found in testing
- Implementing change management
- Auditing and addressing audit findings
- Annual review of plan
Training is an ongoing process and it should be made a part of the corporate standards and the corporate culture.
Supply Chain Management SCM
Supply chain management is the systemic, strategic coordination of the traditional business functions and tactics across these business functions – both within a particular company and across businesses within the supply chain- all coordinated to improve the long-term performance of the individual companies and the supply chain as a whole.
In a traditional manufacturing environment, supply chain management meant managing movement and storage of raw materials, work-in-progress inventory, and finished goods from point of origin to point of consumption.
It involves managing the network of interconnected smaller business units, networks of channels that take part in producing a merchandise of a service package required by the end users or customers.
With businesses crossing the barriers of local markets and reaching out to a global scenario, SCM is now defined as:
Design, planning, execution, control, and monitoring of supply chain activities with the objective of creating net value, building a competitive infrastructure, leveraging worldwide logistics, synchronizing supply with demand and measuring performance globally.
SCM consists of:
- operations management
- logistics
- procurement
- information technology
- integrated business operations Objectives of SCM
- To decrease inventory cost by more accurately predicting demand and scheduling production to match it.
- To reduce overall production cost by streamlining production and by improving information flow.
- To improve customer satisfaction.
Features of SCM
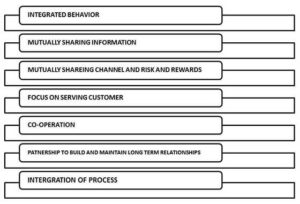
Scope of SCM
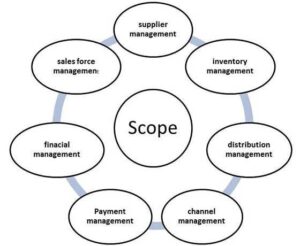
SCM Processes
- Customer Relationship Management
- Customer Service Management
- Demand Management
- Customer Order Fulfillment
- Manufacturing Flow Management
- Procurement Management
- Product Development and Commercialization
- Returns Management
Advantages of SCM
SCM have multi-dimensional advantages:
- To the suppliers:
- Help in giving clear-cut instruction o Online data transfer reduce paper work Inventory Economy:
- Low cost of handling inventory
- Low cost of stock outage by deciding optimum size of replenishment orders o Achieve excellent logistical performance such as just in time Distribution Point:
- Satisfied distributor and whole seller ensure that the right products reach the right place at right time
- Clear business processes subject to fewer errors o Easy accounting of stock and cost of stock Channel Management:
- Reduce total number of transactions required to provide product assortment o Organization is logically capable of performing customization requirements Financial management: o Low cost o Realistic analysis
- Operational performance:
- It involves delivery speed and consistency.
- External customer:
- Conformance of product and services to their requirements o Competitive prices o Quality and reliability o Delivery o After sales services
- To employees and internal customers: o Teamwork and cooperation o Efficient structure and system
Quality work o Delivery
by Jesmin Akther | Jan 5, 2022 | MIS(Management Information System)
Business Intelligence System (BIS)
The term ‘Business Intelligence’ has evolved from the decision support systems and gained strength with the technology and applications like data warehouses, Executive Information Systems and Online Analytical Processing OLAPOLAP.
Business Intelligence System is basically a system used for finding patterns from existing data from operations.
Characteristics of BIS
- It is created by procuring data and information for use in decision-making.
- It is a combination of skills, processes, technologies, applications and practices.
- It contains background data along with the reporting tools.
- It is a combination of a set of concepts and methods strengthened by fact-based support systems.
- It is an extension of Executive Support System or Executive Information System. It collects, integrates, stores, analyzes, and provides access to business information
- It is an environment in which business users get reliable, secure, consistent, comprehensible, easily manipulated and timely information.
- It provides business insights that lead to better, faster, more relevant decisions.
Benefits of BIS Improved Management Processes.
- Planning, controlling, measuring and/or applying changes that results in increased revenues and reduced costs.
- Improved business operations.
- Fraud detection, order processing, purchasing that results in increased revenues and reduced costs.
- Intelligent prediction of future.
Approaches of BIS
For most companies, it is not possible to implement a proactive business intelligence system at one go. The following techniques and methodologies could be taken as approaches to BIS:
- Improving reporting and analytical capabilities
- Using scorecards and dashboards
- Enterprise Reporting
- On-line Analytical Processing OLAPOLAP Analysis
- Advanced and Predictive Analysis
- Alerts and Proactive Notification
- Automated generation of reports with user subscriptions and “alerts” to problems and/or opportunities.
Capabilities of BIS
- Data Storage and Management:
o Data ware house o Ad hoc analysis o Data quality o Data mining
- Information Delivery o Dashboard o Collaboration /search o Managed reporting o Visualization o Scorecard
- Query, Reporting and Analysis o Ad hoc Analysis o Production reporting o OLAP analysis
Enterprise Application Integration (EAI)
An organization may use various information systems: Supply Chain Management: For managing suppliers, inventory and shipping, etc.
- Human Resource Management: For managing personnel, training and recruiting talents;
- Employee Health Care: For managing medical records and insurance details of employees;
- Customer Relationship Management: For managing current and potential customers;
- Business Intelligence Applications: For finding the patterns from existing data from business operations.
All these systems work as individual islands of automation. Most often these systems are standalone and do not communicate with each other due to incompatibility issues such as:
- Operating systems they are residing on; Database system used in the system; Legacy systems not supported anymore.
EAI is an integration framework, a middleware, made of a collection of technologies and services that allows smooth integration of all such systems and applications throughout the enterprise and enables data sharing and more automation of business processes.
Characteristics of EAI
- EAI is defined as “the unrestricted sharing of data and business processes among any connected applications and data sources in the enterprise.”
- EAI, when used effectively allows integration without any major changes to current infrastructure.
- Extends middleware capabilities to cope with application integration.
- Uses application logic layers of different middleware systems as building blocks.
- Keeps track of information related to the operations of the enterprise e.g. Inventory, sales ledger and execute the core processes that create and manipulate this information.
Need for Enterprise-wise Integration
- Unrestricted sharing of data and business processes across an organization.
- Linkage between customers, suppliers and regulators.
- The linking of data, business processes and applications to automate business processes.
- Ensure consistent qualities of service security,reliabilityetc.security,reliabilityetc..
- Reduce the on-going cost of maintenance and reduce the cost of rolling out new systems.
Challenges of EAI
-
- Hub and spoke architecture concentrates all of the processing into a single server/cluster.
- Often became hard to maintain and evolve efficiently.
- Hard to extend to integrate 3rd parties on other technology platforms.
- The canonical data model introduces an intermediary step.
- Added complexity and additional processing effort.
- EAI products typified.
- Heavy customization required to implement the solution.
- Lock-In: Often built using proprietary technology and required specialist skills.
- Lack of flexibility: Hard to extend or to integrate with other EAI products! Requires organization to be EAI ready.
Types of EAI
- Data Level – Process, techniques and technology of moving data between data stores.
- Application Interface Level – Leveraging of interfaces exposed by custom or packaged applications.
- Method Level – Sharing of the business logic.
- User Interface Level – Packaging applications by using their user interface as a common point of integration.
by Jesmin Akther | Jan 5, 2022 | MIS(Management Information System)
Content Management System (CMS)
A Content Management System CMSCMS allows publishing, editing, and modifying content as well as its maintenance by combining rules, processes and/or workflows, from a central interface, in a collaborative environment.
A CMS may serve as a central repository for content, which could be, textual data, documents, movies, pictures, phone numbers, and/or scientific data.
Functions of Content Management
- Creating content
- Storing content
- Indexing content
- Searching content
- Retrieving content
- Publishing content
- Archiving content
- Revising content
- Managing content end-to-end Content Management Workflow
- Designing content template, for example web administrator designs webpage template for web content management.
- Creating content blocks, for example, a web administrator adds empower CMS tags called “content blocks” to webpage template using CMS.
- Positioning content blocks on the document, for example, web administrator positions content blocks in webpage.
- Authoring content providers to search, retrieve, view and update content.
Advantages of CMS
Content management system helps to secure privacy and currency of the content and enhances performance by:
- Ensuring integrity and accuracy of content by ensuring only one user modifies the content at a time.
- Implementing audit trails to monitor changes made in content over time.
- Providing secured user access to content.
- Organization of content into related groups and folders.
- Allowing searching and retrieval of content.
- Recording information and meta-data related to the content, like author and title of content, version of content, date and time of creating the content etc.
- Workflow based routing of content from one user to another.
- Converting paper-based content to digital format.
- Organizing content into groups and distributing it to target audience.
Executive Support System (ESS)
Executive support systems are intended to be used by the senior managers directly to provide support to non-programmed decisions in strategic management.
These information are often external, unstructured and even uncertain. Exact scope and context of such information is often not known beforehand.
This information is intelligence based:
- Market intelligence
- Investment intelligence
- Technology intelligence
Examples of Intelligent Information
Following are some examples of intelligent information, which is often the source of an ESS:
- External databases
- Technology reports like patent records etc.
- Technical reports from consultants
- Market reports
- Confidential information about competitors
- Speculative information like market conditions
- Government policies
- Financial reports and information
Features of Executive Information System
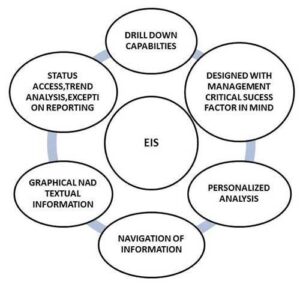
Advantages of ESS
- Easy for upper level executive to use
- Ability to analyze trends
- Augmentation of managers’ leadership capabilities
- Enhance personal thinking and decision-making
- Contribution to strategic control flexibility
- Enhance organizational competitiveness in the market place
- Instruments of change
- Increased executive time horizons.
- Better reporting system
- Improved mental model of business executive
- Help improve consensus building and communication
- Improve office automation
- Reduce time for finding information
- Early identification of company performance
- Detail examination of critical success factor
- Better understanding
- Time management
- Increased communication capacity and quality
Disadvantage of ESS
- Functions are limited
- Hard to quantify benefits
- Executive may encounter information overload
- System may become slow
- Difficult to keep current data
- May lead to less reliable and insecure data
Excessive cost for small company
by Jesmin Akther | Jan 5, 2022 | MIS(Management Information System)
MIS Decision Support System, Knowledge Management System
Decision support systems (DSS) are interactive software-based systems intended to help managers in decision-making by accessing large volumes of information generated from various related information systems involved in organizational business processes, such as office automation system, transaction processing system, etc.
DSS uses the summary information, exceptions, patterns, and trends using the analytical models. A decision support system helps in decision-making but does not necessarily give a decision itself. The decision makers compile useful information from raw data, documents, personal knowledge, and/or business models to identify and solve problems and make decisions.
Programmed and Non-programmed Decisions
There are two types of decisions – programmed and non-programmed decisions.
Programmed decisions are basically automated processes, general routine work, where:
- These decisions have been taken several times.
- These decisions follow some guidelines or rules.
For example, selecting a reorder level for inventories, is a programmed decision.
Non-programmed decisions occur in unusual and non-addressed situations, so:
- It would be a new decision.
- There will not be any rules to follow.
- These decisions are made based on the available information.
- These decisions are based on the manger’s discretion, instinct, perception and judgment.
For example, investing in a new technology is a non-programmed decision.
Decision support systems generally involve non-programmed decisions. Therefore, there will be no exact report, content, or format for these systems. Reports are generated on the fly.
Attributes of a DSS
- Adaptability and flexibility
- High level of Interactivity
- Ease of use
- Efficiency and effectiveness
- Complete control by decision-makers
- Ease of development
- Extendibility
- Support for modeling and analysis
- Support for data access
Standalone, integrated, and Web-based
Characteristics of a DSS
Support for decision-makers in semi-structured and unstructured problems.
- Support for managers at various managerial levels, ranging from top executive to line managers.
- Support for individuals and groups. Less structured problems often requires the involvement of several individuals from different departments and organization level.
- Support for interdependent or sequential decisions.
- Support for intelligence, design, choice, and implementation.
- Support for variety of decision processes and styles.
- DSSs are adaptive over time.
Benefits of DSS
- Improves efficiency and speed of decision-making activities.
- Increases the control, competitiveness and capability of futuristic decision-making of the organization.
- Facilitates interpersonal communication.
- Encourages learning or training.
- Since it is mostly used in non-programmed decisions, it reveals new approaches and sets up new evidences for an unusual decision.
- Helps automate managerial processes.
Components of a DSS
Following are the components of the Decision Support System:
- Database Management System DBMSDBMS: To solve a problem the necessary data may come from internal or external database. In an organization, internal data are generated by a system such as TPS and MIS. External data come from a variety of sources such as newspapers, online data services, databases financial,marketing,humanresourcesfinancial,marketing,humanresources.
- Model Management System: It stores and accesses models that managers use to make decisions. Such models are used for designing manufacturing facility, analyzing the financial health of an organization, forecasting demand of a product or service, etc.
Support Tools: Support tools like online help; pulls down menus, user interfaces, graphical analysis, error correction mechanism, facilitates the user interactions with the system.
Classification of DSS
There are several ways to classify DSS. Hoi Apple and Whinstone classifies DSS as follows:
Text Oriented DSS: It contains textually represented information that could have a bearing on decision. It allows documents to be electronically created, revised and viewed as needed.
- Database Oriented DSS: Database plays a major role here; it contains organized and highly structured data.
- Spreadsheet Oriented DSS: It contains information in spread sheets that allows create, view, modify procedural knowledge and also instructs the system to execute self-contained instructions. The most popular tool is Excel and Lotus 1-2-3.
- Solver Oriented DSS: It is based on a solver, which is an algorithm or procedure written for performing certain calculations and particular program type.
- Rules Oriented DSS: It follows certain procedures adopted as rules.
- Rules Oriented DSS: Procedures are adopted in rules oriented DSS. Export system is the example.
- Compound DSS: It is built by using two or more of the five structures explained above.
Types of DSS
Following are some typical DSSs:
- Status Inquiry System: It helps in taking operational, management level, or middle level management decisions, for example daily schedules of jobs to machines or machines to operators.
- Data Analysis System: It needs comparative analysis and makes use of formula or an algorithm, for example cash flow analysis, inventory analysis etc.
- Information Analysis System: In this system data is analyzed and the information report is generated. For example, sales analysis, accounts receivable systems, market analysis etc.
- Accounting System: It keeps track of accounting and finance related information, for example, final account, accounts receivables, accounts payables, etc. that keep track of the major aspects of the business.
- Model Based System: Simulation models or optimization models used for decisionmaking are used infrequently and creates general guidelines for operation or management.
Knowledge Management System (KMS)
All the systems we are discussing here come under knowledge management category. A knowledge management system is not radically different from all these information systems, but it just extends the already existing systems by assimilating more information.
As we have seen, data is raw facts, information is processed and/or interpreted data, and knowledge is personalized information.
What is Knowledge?
- Personalized information
- State of knowing and understanding
An object to be stored and manipulated
- A process of applying expertise
- A condition of access to information
- Potential to influence action
Sources of Knowledge of an Organization
- Intranet
- Data warehouses and knowledge repositories
- Decision support tools
- Groupware for supporting collaboration
- Networks of knowledge workers
- Internal expertise
Definition of KMS
A knowledge management system comprises a range of practices used in an organization to identify, create, represent, distribute, and enable adoption to insight and experience. Such insights and experience comprise knowledge, either embodied in individual or embedded in organizational processes and practices.
Purpose of KMS
- Improved performance
- Competitive advantage
- Innovation
- Sharing of knowledge
- Integration
- Continuous improvement by:
o Driving strategy o Starting new lines of business o Solving problems faster o Developing professional skills o Recruit and retain talent
Activities in Knowledge Management
- Start with the business problem and the business value to be delivered first.
- Identify what kind of strategy to pursue to deliver this value and address the KM problem.
- Think about the system required from a people and process point of view.
- Finally, think about what kind of technical infrastructure are required to support the people and processes.
- Implement system and processes with appropriate change management and iterative staged release.
Level of Knowledge Management
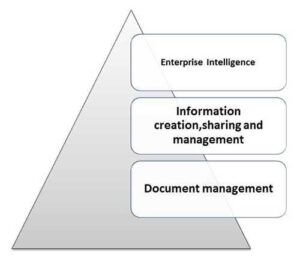
by Jesmin Akther | Jan 4, 2022 | MIS(Management Information System)
Enterprise applications
Enterprise applications are specifically designed for the sole purpose of promoting the needs and objectives of the organizations.
Enterprise applications provide business-oriented tools supporting electronic commerce, enterprise communication and collaboration, and web-enabled business processes both within a networked enterprise and with its customers and business partners.
Services Provided by Enterprise Applications
Some of the services provided by an enterprise application includes:
- Online shopping, billing and payment processing
- Interactive product catalogue
- Content management
- Customer relationship management
- Manufacturing and other business processes integration
- IT services management
- Enterprise resource management
- Human resource management
- Business intelligence management
- Business collaboration and security
- Form automation
Basically these applications intend to model the business processes, i.e., how the entire organization works. These tools work by displaying, manipulating and storing large amounts of data and automating the business processes with these data.
Most Commonly Used Enterprise Applications
Multitude of applications comes under the definition of Enterprise Applications. In this section, let us briefly cover the following applications:
- Management information system(MIS)
- Enterprise Resource Planning(ERP)
- Customer Relationship Management (CRM)
- Decision Support System(DSS)
- Knowledge Management Systems (KMS)
- Content Management System (CMS)
- Executive Support System (ESS)
- Business Intelligence System (BIS)
- Enterprise Application Integration (EAI)
- Business Continuity Planning (BCP)
- Supply Chain Management (SCM)
Management Information System
To the managers, Management Information System is an implementation of the organizational systems and procedures. To a programmer it is nothing but file structures and file processing. However, it involves much more complexity.
The three components of MIS provide a more complete and focused definition, where System suggests integration and holistic view, Information stands for processed data, and Management is the ultimate user, the decision makers.
Management information system can thus be analyzed as follows:
Management
Management covers the planning, control, and administration of the operations of a concern. The top management handles planning; the middle management concentrates on controlling; and the lower management is concerned with actual administration.
Information
Information, in MIS, means the processed data that helps the management in planning, controlling and operations. Data means all the facts arising out of the operations of the concern. Data is processed i.e. recorded, summarized, compared and finally presented to the management in the form of MIS report.
System
Data is processed into information with the help of a system. A system is made up of inputs, processing, output and feedback or control.
Thus MIS means a system for processing data in order to give proper information to the management for performing its functions.
Definition
Management Information System or ‘MIS’ is a planned system of collecting, storing, and disseminating data in the form of information needed to carry out the functions of management.
Objectives of MIS
The goals of an MIS are to implement the organizational structure and dynamics of the enterprise for the purpose of managing the organization in a better way and capturing the potential of the information system for competitive advantage.
Following are the basic objectives of an MIS:
- Capturing Data: Capturing contextual data, or operational information that will contribute in decision making from various internal and external sources of organization.
- Processing Data: The captured data is processed into information needed for planning, organizing, coordinating, directing and controlling functionalities at strategic, tactical and operational level. Processing data means: o making calculations with the data o sorting data o classifying data and o summarizing data
- Information Storage: Information or processed data need to be stored for future use.
- Information Retrieval: The system should be able to retrieve this information from the storage as and when required by various users.
- Information Propagation: Information or the finished product of the MIS should be circulated to its users periodically using the organizational network.
Characteristics of MIS
Following are the characteristics of an MIS: It should be based on a long-term planning.
- It should provide a holistic view of the dynamics and the structure of the organization.
- It should work as a complete and comprehensive system covering all interconnecting sub-systems within the organization.
- It should be planned in a top-down way, as the decision makers or the management should actively take part and provide clear direction at the development stage of the MIS.
- It should be based on need of strategic, operational and tactical information of managers of an organization.
- It should also take care of exceptional situations by reporting such situations.
- It should be able to make forecasts and estimates, and generate advanced information, thus providing a competitive advantage. Decision makers can take actions on the basis of such predictions.
- It should create linkage between all sub-systems within the organization, so that the decision makers can take the right decision based on an integrated view.
- It should allow easy flow of information through various sub-systems, thus avoiding redundancy and duplicity of data. It should simplify the operations with as much practicability as possible.
- Although the MIS is an integrated, complete system, it should be made in such a flexible way that it could be easily split into smaller sub-systems as and when required.
- A central database is the backbone of a well-built MIS.
Characteristics of Computerized MIS
Following are the characteristics of a well-designed computerized MIS:
- It should be able to process data accurately and with high speed, using various techniques like operations research, simulation, heuristics, etc.
- It should be able to collect, organize, manipulate, and update large amount of raw data of both related and unrelated nature, coming from various internal and external sources at different periods of time.
- It should provide real time information on ongoing events without any delay.
- It should support various output formats and follow latest rules and regulations in practice.
- It should provide organized and relevant information for all levels of management:
strategic, operational, and tactical.
- It should aim at extreme flexibility in data storage and retrieval.
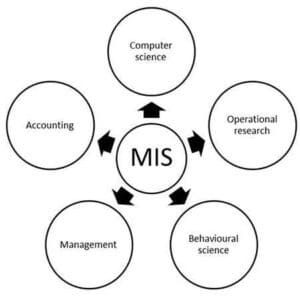
Nature and Scope of MIS
The following diagram shows the nature and scope of MIS:
Enterprise Resource Planning (ERP)
ERP is an integrated, real-time, cross-functional enterprise application, an enterprise-wide transaction framework that supports all the internal business processes of a company.
It supports all core business processes such as sales order processing, inventory management and control, production and distribution planning, and finance.
Why of ERP?
ERP is very helpful in the following areas:
- Business integration and automated data update
- Linkage between all core business processes and easy flow of integration
- Flexibility in business operations and more agility to the company
- Better analysis and planning capabilities
- Critical decision-making
- Competitive advantage
- Use of latest technologies
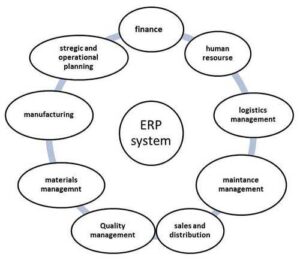
Features of ERP
The following diagram illustrates the features of ERP:
Scope of ERP
- Finance: Financial accounting, Managerial accounting, treasury management, asset management, budget control, costing, and enterprise control.
- Logistics: Production planning, material management, plant maintenance, project management, events management, etc.
- Human resource: Personnel management, training and development, etc.
- Supply Chain: Inventory control, purchase and order control, supplier scheduling, planning, etc.
- Work flow: Integrate the entire organization with the flexible assignment of tasks and responsibility to locations, position, jobs, etc.
Advantages of ERP
- Reduction of lead time
- Reduction of cycle time
- Better customer satisfaction
- Increased flexibility, quality, and efficiency
- Improved information accuracy and decision making capability
- Onetime shipment
- Improved resource utilization
- Improve supplier performance
- Reduced quality costs
- Quick decision-making
- Forecasting and optimization
- Better transparency
Disadvantage of ERP
- Expense and time in implementation
- Difficulty in integration with other system
- Risk of implementation failure
- Difficulty in implementation change
- Risk in using one vendor
Customer Relationship Management (CRM)
CRM is an enterprise application module that manages a company’s interactions with current and future customers by organizing and coordinating, sales and marketing, and providing better customer services along with technical support.
Atul Parvatiyar and Jagdish N. Sheth provide an excellent definition for customer relationship management in their work titled – ‘Customer Relationship Management: Emerging Practice, Process, and Discipline‘:
Customer Relationship Management is a comprehensive strategy and process of acquiring, retaining, and partnering with selective customers to create superior value for the company and the customer. It involves the integration of marketing, sales, customer service, and the supply-chain functions of the organization to achieve greater efficiencies and effectiveness in delivering customer value.
Why CRM?
- To keep track of all present and future customers.
- To identify and target the best customers.
- To let the customers know about the existing as well as the new products and services.
- To provide real-time and personalized services based on the needs and habits of the existing customers.
- To provide superior service and consistent customer experience.
- To implement a feedback system.
Scope of CRM
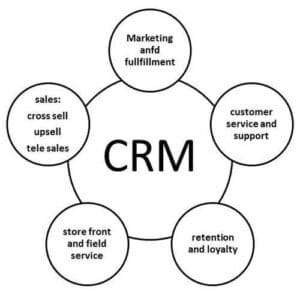
Advantages of CRM
- Provides better customer service and increases customer revenues.
- Discovers new customers.
- Cross-sells and up-sells products more effectively.
- Helps sales staff to close deals faster.
- Makes call centers more efficient.
- Simplifies marketing and sales processes.
Disadvantages of CRM
- Sometimes record loss is a major problem.
- Overhead costs.
- Giving training to employees is an issue in small organizations.
by Jesmin Akther | Jan 4, 2022 | MIS(Management Information System)
MIS Basic Information Concepts
Information can be defined as meaningfully interpreted data. If we give you a number 1- 212-290-4700, it does not make any sense on its own. It is just a raw data. However if we say Tel: +1-212-290-4700, it starts making sense. It becomes a telephone number. If I gather some more data and record it meaningfully like: Address: 350 Fifth Avenue, 34th floor New York, NY 10118-3299 USA Tel: +1-212-290-4700 Fax: +1-212-736-1300
It becomes a very useful information – the address of New York office of Human Rights Watch, a non-profit, non-governmental human rights organization.
So, from a system analyst’s point of view, information is a sequence of symbols that can be construed to a useful message. An Information System is a system that gathers data and disseminates information with the sole purpose of providing information to its users. The main object of an information system is to provide information to its users. Information systems vary according to the type of users who use the system. A Management Information System is an information system that evaluates, analyzes, and processes an organization’s data to produce meaningful and useful information based on which the management can take right decisions to ensure future growth of the organization.
Information Definition
According to Wikipedia: “Information can be recorded as signs, or transmitted as signals. Information is any kind of event that affects the state of a dynamic system that can interpret the information.
Conceptually, information is the message utter anceor expression utter anceor expression being conveyed. Therefore, in a general sense, information is “Knowledge communicated or received, concerning a particular fact or circumstance”. Information cannot be predicted and resolves uncertainty.”
Information Vs Data
Data can be described as unprocessed facts and figures. Plain collected data as raw facts cannot help in decision-making. However, data is the raw material that is organized, structured, and interpreted to create useful information systems.
Data is defined as ‘groups of non-random symbols in the form of text, images, voice representing quantities, action and objects’.
Information is interpreted data; created from organized, structured, and processed data in a particular context.
According to Davis and Olson: “Information is a data that has been processed into a form that is meaningful to recipient and is of real or perceived value in the current or the prospective action or decision of recipient.”
Information, Knowledge and Business Intelligence
Professor Ray R. Larson of the School of Information at the University of California, Berkeley, provides an Information Hierarchy, which is:
- Data – The raw material of information.
- Information – Data organized and presented by someone.
- Knowledge – Information read, heard, or seen, and understood.
- Wisdom – Distilled and integrated knowledge and understanding.
Scott Andrews’ explains Information Continuum as follows:
- Data – A Fact or a piece of information, or a series thereof.
- Information – Knowledge discerned from data.
- Business Intelligence – Information Management pertaining to an organization’s policy or decision-making, particularly when tied to strategic or operational objectives.
Information/Data Collection Techniques
The most popular data collection techniques include:
- Surveys: A questionnaires is prepared to collect the data from the field.
- Secondary data sources or archival data: Data is collected through old records, magazines, company website etc.
- Objective measures or tests: An experimental test is conducted on the subject and the data is collected.
- Interviews: Data is collected by the system analyst by following a rigid procedure and collecting the answers to a set of pre-conceived questions through personal interviews.
Classification of Information
Information can be classified in a number of ways and in this chapter, you will learn two of the most important ways to classify information.
Classification by Characteristic
Based on Anthony’s classification of Management, information used in business for decision-making is generally categorized into three types:
- Strategic Information: Strategic information is concerned with long term policy decisions that defines the objectives of a business and checks how well these objectives are met. For example, acquiring a new plant, a new product, diversification of business etc, comes under strategic information.
- Tactical Information: Tactical information is concerned with the information needed for exercising control over business resources, like budgeting, quality control, service level, inventory level, productivity level etc.
- Operational Information: Operational information is concerned with plant/business level information and is used to ensure proper conduction of specific operational tasks as planned/intended. Various operator specific, machine specific and shift specific jobs for quality control checks comes under this category.
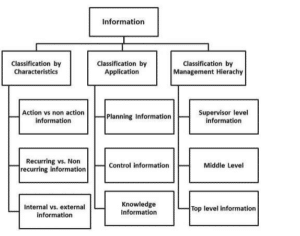
Classification by Application
In terms of applications, information can be categorized as:
- Planning Information: These are the information needed for establishing standard norms and specifications in an organization. This information is used in strategic, tactical, and operation planning of any activity. Examples of such information are time standards, design standards.
- Control Information: This information is needed for establishing control over all business activities through feedback mechanism. This information is used for controlling attainment, nature and utilization of important processes in a system. When such information reflects a deviation from the established standards, the system should induce a decision or an action leading to control.
- Knowledge Information: Knowledge is defined as “information about information”. Knowledge information is acquired through experience and learning, and collected from archival data and research studies.
- Organizational Information: Organizational information deals with an organization’s environment, culture in the light of its objectives. Karl Weick’s Organizational Information Theory emphasizes that an organization reduces its equivocality or uncertainty by collecting, managing and using these information prudently. This information is used by everybody in the organization; examples of such information are employee and payroll information.
- Functional/Operational Information: This is operation specific information. For example, daily schedules in a manufacturing plant that refers to the detailed assignment of jobs to machines or machines to operators. In a service oriented business, it would be the duty roster of various personnel. This information is mostly internal to the organization.
- Database Information: Database information construes large quantities of information that has multiple usage and application. Such information is stored, retrieved and managed to create databases. For example, material specification or supplier information is stored for multiple users.
Quality of Information
Information is a vital resource for the success of any organization. Future of an organization lies in using and disseminating information wisely. Good quality information placed in right context in right time tells us about opportunities and problems well in advance.
Good quality information: Quality is a value that would vary according to the users and uses of the information.
According to Wang and Strong, following are the dimensions or elements of Information Quality:
- Intrinsic: Accuracy, Objectivity, Believability, Reputation
- Contextual: Relevancy, Value-Added, Timeliness, Completeness, Amount of information
- Representational: Interpretability, Format, Coherence, Compatibility
- Accessibility: Accessibility, Access security
Various authors propose various lists of metrics for assessing the quality of information. Let us generate a list of the most essential characteristic features for information quality:
- Reliability – It should be verifiable and dependable.
- Timely – It must be current and it must reach the users well in time, so that important decisions can be made in time.
- Relevant – It should be current and valid information and it should reduce uncertainties.
- Accurate – It should be free of errors and mistakes, true, and not deceptive.
- Sufficient – It should be adequate in quantity, so that decisions can be made on its basis.
- Unambiguous – It should be expressed in clear terms. In other words, in should be comprehensive.
- Complete – It should meet all the needs in the current context.
- Unbiased – It should be impartial, free from any bias. In other words, it should have integrity.
- Explicit – It should not need any further explanation.
- Comparable – It should be of uniform collection, analysis, content, and format.
- Reproducible – It could be used by documented methods on the same data set to achieve a consistent result.
Information Need & Objective
Information processing beyond doubt is the dominant industry of the present century. Following factors states few common factors that reflect on the needs and objectives of the information processing:
- Increasing impact of information processing for organizational decision making.
- Dependency of services sector including banking, financial organization, health care, entertainment, tourism and travel, education and numerous others on information.
- Changing employment scene world over, shifting base from manual agricultural to machine-based manufacturing and other industry related jobs.
- Information revolution and the overall development scenario.
- Growth of IT industry and its strategic importance.
- Strong growth of information services fuelled by increasing competition and reduced product life cycle.
- Need for sustainable development and quality life.
- Improvement in communication and transportation brought in by use of information processing.
- Use of information processing in reduction of energy consumption, reduction in pollution and a better ecological balance in future.
- Use of information processing in land record managements, legal delivery system, educational institutions, natural resource planning, customer relation management and so on.
In a nutshell:
- Information is needed to survive in the modern competitive world.
- Information is needed to create strong information systems and keep these systems up to date. Implications of Information in Business Information processing has transformed our society in numerous ways. From a business perspective, there has been a huge shift towards increasingly automated business processes and communication. Access to information and capability of information processing has helped in achieving greater efficiency in accounting and other business processes. A complete business information system, accomplishes the following functionalities:
- Collection and storage of data.
- Transform these data into business information useful for decision making.
- Provide controls to safeguard data.
- Automate and streamline reporting. The following list summarizes the five main uses of information by businesses and other organizations:
- Planning – At the planning stage, information is the most important ingredient in decision making. Information at planning stage includes that of business resources, assets, liabilities, plants and machineries, properties, suppliers, customers, competitors, market and market dynamics, fiscal policy changes of the Government, emerging technologies, etc.
- Recording – Business processing these days involves recording information about each transaction or event. This information collected, stored and updated regularly at the operational level.
- Controlling – A business need to set up an information filter, so that only filtered data is presented to the middle and top management. This ensures efficiency at the operational level and effectiveness at the tactical and strategic level.
- Measuring – A business measures its performance metrics by collecting and analyzing sales data, cost of manufacturing, and profit earned.
- Decision-making – MIS is primarily concerned with managerial decision-making, theory of organizational behavior, and underlying human behavior in organizational context. Decision-making information includes the socio-economic impact of competition, globalization, democratization, and the effects of all these factors on an organizational structure.
In short, this multi-dimensional information evolves from the following logical foundations:
- Operations research and management science
- Theory of organizational behavior
- Computer science: o Data and file structure o Data theory design and implementation 9 o Computer networking o Expert systems and artificial intelligence
- Information theory Following factors arising as an outcome of information processing help speed up of business events and achieves greater efficiency:
- Directly and immediate linkage to the system
- Faster communication of an order
- Electronic transfer of funds for faster payment
- Electronically solicited pricing helps in determining the best price helps in determining the best price
MIS Need for Information Systems
Managers make decisions. Decision-making generally takes a four-fold path:
- Understanding the need for decision or the opportunity,
- Preparing alternative course of actions,
- Evaluating all alternative course of actions,
- Deciding the right path for implementation.
MIS is an information system that provides information in the form of standardized reports and displays for the managers. MIS is a broad class of information systems designed to provide information needed for effective decision making.
Data and information created from an accounting information system and the reports generated thereon are used to provide accurate, timely and relevant information needed for effective decision making by managers.
Management information systems provide information to support management decision making, with the following goals:
- Pre-specified and preplanned reporting to managers.
- Interactive and ad-hoc support for decision making.
- Critical information for top management.
MIS is of vital importance to any organization, because:
- It emphasizes on the management decision making, not only processing of data generated by business operations.
- It emphasizes on the systems framework that should be used for organizing information systems applications.

by Jesmin Akther | Jan 4, 2022 | Internet of Things (IOT)
IOT (Internet of Things)
IoT tutorial provides basic and advanced concepts of IoT. Our Internet of Things tutorial is designed for beginners and professionals. The Internet of Things (IoT) refers to the use of the Internet to access and control everyday useful equipment and gadgets. Our IoT tutorial covers all aspects of IoT, including its introduction, features, benefits, and drawbacks.
What is an Internet of Things (IoT)
Let’s take a closer look at our smartphone, which includes GPS tracking, a mobile gyroscope, adaptive brightness, voice detection, and face detection, among other features. These components each have their own unique characteristics, but what if they all worked together to create a better environment? The brightness of my phone, for example, is modified based on my GPS location or direction. The Internet of Things (IoT) is a concept that connects everyday objects integrated with electronics, software, and sensors to the internet, allowing them to collect and exchange data without the need for human contact (IoT). In the Internet of Things, “things” refers to anything and everything in daily life that may be accessible or connected via the internet.
IoT Introduction
IoT is an advanced automation and analytics system which deals with artificial intelligence, sensor, networking, electronic, cloud messaging etc. to deliver complete systems for the product or services. The system created by IoT has greater transparency, control, and performance.
As we have a platform such as a cloud that contains all the data through which we connect all the things around us. For example, a house, where we can connect our home appliances such as air conditioner, light, etc. through each other and all these things are managed at the same platform. Since we have a platform, we can connect our car, track its fuel meter, speed level, and also track the location of the car.
If there is a common platform where all these things can connect to each other would be great because based on my preference, I can set the room temperature. For example, if I love the room temperature to to be set at 25 or 26-degree Celsius when I reach back home from my office, then according to my car location, my AC would start before 10 minutes I arrive at home. This can be done through the Internet of Things (IoT).
How does Internet of Thing (IoT) Work?
The working of IoT is different for different IoT echo system (architecture). However, the key concept of there working are similar. The entire working process of IoT starts with the device themselves, such as smartphones, digital watches, electronic appliances, which securely communicate with the IoT platform. The platforms collect and analyze the data from all multiple devices and platforms and transfer the most valuable data with applications to devices.
Features of IOT
The most important features of IoT on which it works are connectivity, analyzing, integrating, active engagement, and many more. Some of them are listed below:
Connectivity: Connectivity refers to establish a proper connection between all the things of IoT to IoT platform it may be server or cloud. After connecting the IoT devices, it needs a high speed messaging between the devices and cloud to enable reliable, secure and bi-directional communication.
Analyzing: After connecting all the relevant things, it comes to real-time analyzing the data collected and use them to build effective business intelligence. If we have a good insight into data gathered from all these things, then we call our system has a smart system.
Integrating: IoT integrating the various models to improve the user experience as well.
Artificial Intelligence: IoT makes things smart and enhances life through the use of data. For example, if we have a coffee machine whose beans have going to end, then the coffee machine itself order the coffee beans of your choice from the retailer.
Sensing: The sensor devices used in IoT technologies detect and measure any change in the environment and report on their status. IoT technology brings passive networks to active networks. Without sensors, there could not hold an effective or true IoT environment.
Active Engagement: IoT makes the connected technology, product, or services to active engagement between each other.
Endpoint Management: It is important to be the endpoint management of all the IoT system otherwise, it makes the complete failure of the system. For example, if a coffee machine itself order the coffee beans when it goes to end but what happens when it orders the beans from a retailer and we are not present at home for a few days, it leads to the failure of the IoT system. So, there must be a need for endpoint management.
Small Devices − Devices, as predicted, have become smaller, cheaper, and more powerful over time. IoT exploits purpose-built small devices to deliver its precision, scalability, and versatility.
IoT Advantages
The advantages of IoT span across every area of lifestyle and business. Here is a list of some of the advantages that IoT has to offer −
- Improved Customer Engagement − Current analytics suffer from blind-spots and significant flaws in accuracy; and as noted, engagement remains passive. IoT completely transforms this to achieve richer and more effective engagement with audiences.
- Technology Optimization − The same technologies and data which improve the customer experience also improve device use, and aid in more potent improvements to technology. IoT unlocks a world of critical functional and field data.
- Reduced Waste − IoT makes areas of improvement clear. Current analytics give us superficial insight, but IoT provides real-world information leading to more effective management of resources.
- Enhanced Data Collection − Modern data collection suffers from its limitations and its design for passive use. IoT breaks it out of those spaces, and places it exactly where humans really want to go to analyze our world. It allows an accurate picture of everything.
IoT Disadvantages
Though IoT delivers an impressive set of benefits, it also presents a significant set of challenges. Here is a list of some its major issues −
- Security − IoT creates an ecosystem of constantly connected devices communicating over networks. The system offers little control despite any security measures. This leaves users exposed to various kinds of attackers.
- Privacy − The sophistication of IoT provides substantial personal data in extreme detail without the user’s active participation.
- Complexity − Some find IoT systems complicated in terms of design, deployment, and maintenance given their use of multiple technologies and a large set of new enabling technologies.
- Flexibility − Many are concerned about the flexibility of an IoT system to integrate easily with another. They worry about finding themselves with several conflicting or locked systems.
- Compliance − IoT, like any other technology in the realm of business, must comply with regulations. Its complexity makes the issue of compliance seem incredibly challenging when many consider standard software compliance a battle.

by Jesmin Akther | Oct 19, 2021 | C Programming
Conversion from uppercase to lower case using c program
#include<stdio.h>
#include<string.h>
int main(){
char str[20];
int i;
printf("Enter any string->");
scanf("%s",str);
printf("The string is->%s",str);
for(i=0;i<=strlen(str);i++){
if(str[i]>=65&&str[i]<=90)
str[i]=str[i]+32;
}
printf("\nThe string in lower case is->%s",str);
return 0;
}
Algorithm:
ASCII value of ‘A’ is 65 while ‘a’ is 97. Difference between them is 97 – 65 = 32
So if we will add 32 in the ASCII value of ‘A’ then it will be ‘a’ and if will we subtract 32 in ASCII value of ‘a’ it will be ‘A’. It is true for all alphabets.
In general rule:
Upper case character = Lower case character – 32
Lower case character = Upper case character + 32
Write a c program to convert the string from lower case to upper case
#include<stdio.h>
int main(){
char str[20];
int i;
printf("Enter any string->");
scanf("%s",str);
printf("The string is->%s",str);
for(i=0;i<=strlen(str);i++){
if(str[i]>=97&&str[i]<=122)
str[i]=str[i]-32;
}
printf("\nThe string in lowercase is->%s",str);
return 0;
}
Algorithm:
ASCII value of ‘A’ is 65 while ‘a’ is 97. Difference between them is 97 – 65 = 32
So if we will add 32 in the ASCII value of ‘A’ then it will be ‘a’ and if will we subtract 32 in ASCII value of ‘a’ it will be ‘A’. It is true for all alphabets.
In general rule:
Upper case character = Lower case character – 32
Lower case character = Upper case character + 32
COUNTING DIFFERENT CHARACTERS IN A STRING USING C PROGRAM
#include <stdio.h>
int isvowel(char chk);
int main(){
char text[1000], chk;
int count;
count = 0;
while((text[count] = getchar()) != '\n')
count++;
text[count] = '\0';
count = 0;
while ((chk = text[count]) != '\0'){
if (isvowel(chk)){
if((chk = text[++count]) && isvowel(chk)){
putchar(text[count -1]);
putchar(text[count]);
putchar('\n');
}
}
else
++count;
}
return 0;
}
int isvowel(char chk){
if(chk == 'a' || chk == 'e' || chk == 'i' || chk == 'o' || chk == 'u')
return 1;
return 0;
}
Program for sorting of string in c language
#include<stdio.h>
int main(){
int i,j,n;
char str[20][20],temp[20];
puts("Enter the no. of string to be sorted");
scanf("%d",&n);
for(i=0;i<=n;i++)
gets(str[i]);
for(i=0;i<=n;i++)
for(j=i+1;j<=n;j++){
if(strcmp(str[i],str[j])>0){
strcpy(temp,str[i]);
strcpy(str[i],str[j]);
strcpy(str[j],temp);
}
}
printf("The sorted string\n");
for(i=0;i<=n;i++)
puts(str[i]);
return 0;
}
Concatenation of two strings in c programming language
#include<stdio.h>
int main(){
int i=0,j=0;
char str1[20],str2[20];
puts(“Enter first string”);
gets(str1);
puts(“Enter second string”);
gets(str2);
printf(“Before concatenation the strings are\n”);
puts(str1);
puts(str2);
while(str1[i]!=’\0′){
i++;
}
while(str2[j]!=’\0′){
str1[i++]=str2[j++];
}
str1[i]=’\0′;
printf(“After concatenation the strings are\n”);
puts(str1);
return 0;
}
Concatenation of two strings using pointer in c programming language
#include<stdio.h>
int main(){
int i=0,j=0;
char *str1,*str2,*str3;
puts("Enter first string");
gets(str1);
puts("Enter second string");
gets(str2);
printf("Before concatenation the strings are\n");
puts(str1);
puts(str2);
while(*str1){
str3[i++]=*str1++;
}
while(*str2){
str3[i++]=*str2++;
}
str3[i]='\0';
printf("After concatenation the strings are\n");
puts(str3);
return 0;
}
C code which prints initial of any name
#include<stdio.h>
int main(){
char str[20];
int i=0;
printf("Enter a string: ");
gets(str);
printf("%c",*str);
while(str[i]!='\0'){
if(str[i]==' '){
i++;
printf("%c",*(str+i));
}
i++;
}
return 0;
}
Sample output:
Enter a string: Robert De Niro
RDN
Write a c program to print the string from given character
#include<string.h>
#include<stdio.h>
int main(){
char *p;
char s[20],s1[1];
printf("\nEnter a string: ");
scanf("%[^\n]",s);
fflush(stdin);
printf("\nEnter character: ");
gets(s1);
p=strpbrk(s,s1);
printf("\nThe string from the given character is: %s",p);
return 0;
}
Reverse a string in c without using temp
String reverse using strrev in c programming language
#include<stdio.h>
#include<string.h>
int main(){
char str[50];
char *rev;
printf("Enter any string : ");
scanf("%s",str);
rev = strrev(str);
printf("Reverse string is : %s",rev);
return 0;
}
String reverse in c without using strrev
String reverse in c without using string function
How to reverse a string in c without using reverse function
#include<stdio.h>
int main(){
char str[50];
char rev[50];
int i=-1,j=0;
printf("Enter any string : ");
scanf("%s",str);
while(str[++i]!='\0');
while(i>=0)
rev[j++] = str[--i];
rev[j]='\0';
printf("Reverse of string is : %s",rev);
return 0;
}
Sample output:
Enter any string : cquestionbank.blogspot.com
Reverse of string is : moc.topsgolb.knabnoitseuqc
C code to reverse a string by recursion:
#include<stdio.h>
#define MAX 100
char* getReverse(char[]);
int main(){
char str[MAX],*rev;
printf("Enter any string: ");
scanf("%s",str);
rev = getReverse(str);
printf("Reversed string is: %s",rev);
return 0;
}
char* getReverse(char str[]){
static int i=0;
static char rev[MAX];
if(*str){
getReverse(str+1);
rev[i++] = *str;
}
return rev;
}
Sample output:
Enter any string: mona
Reversed string is: anom
String concatenation in c without using string functions
#include<stdio.h>
void stringConcat(char[],char[]);
int main(){
char str1[100],str2[100];
int compare;
printf("Enter first string: ");
scanf("%s",str1);
printf("Enter second string: ");
scanf("%s",str2);
stringConcat(str1,str2);
printf("String after concatenation: %s",str1);
return 0;
}
void stringConcat(char str1[],char str2[]){
int i=0,j=0;
while(str1[i]!='\0'){
i++;
}
while(str2[j]!='\0'){
str1[i] = str2[j];
i++;
j++;
}
str1[i] = '\0';
}
Sample output:
Enter first string: cquestionbank
Enter second string: @blogspot.com
String after concatenation: [email protected]
C program to compare two strings without using string functions
#include<stdio.h>
int stringCompare(char[],char[]);
int main(){
char str1[100],str2[100];
int compare;
printf("Enter first string: ");
scanf("%s",str1);
printf("Enter second string: ");
scanf("%s",str2);
compare = stringCompare(str1,str2);
if(compare == 1)
printf("Both strings are equal.");
else
printf("Both strings are not equal");
return 0;
}
int stringCompare(char str1[],char str2[]){
int i=0,flag=0;
while(str1[i]!='\0' && str2[i]!='\0'){
if(str1[i]!=str2[i]){
flag=1;
break;
}
i++;
}
if (flag==0 && str1[i]=='\0' && str2[i]=='\0')
return 1;
else
return 0;
}
Sample output:
Enter first string: cquestionbank.blogspot.com
Enter second string: cquestionbank.blogspot.com
Both strings are equal.
String copy without using strcpy in c programming language
#include<stdio.h>
void stringCopy(char[],char[]);
int main(){
char str1[100],str2[100];
printf("Enter any string: ");
scanf("%s",str1);
stringCopy(str1,str2);
printf("After copying: %s",str2);
return 0;
}
void stringCopy(char str1[],char str2[]){
int i=0;
while(str1[i]!='\0'){
str2[i] = str1[i];
i++;
}
str2[i]='\0';
}
Sample output:
Enter any string: cquestionbank.blogspot.com
After copying: cquestionbank.blogspot.com
Program to convert string into ASCII values in c programming language:
#include<stdio.h>
int main(){
char str[100];
int i=0;
printf("Enter any string: ");
scanf("%s",str);
printf("ASCII values of each characters of given string: ");
while(str[i])
printf("%d ",str[i++]);
return 0;
}
Sample Output:
Enter any string: cquestionbank.blogspot.com
ASCII values of each characters of given string: 99 113 117 101 115 116 105 111 110 98 97 110 107 46 98 108 111 103 115 112 111 116 46 99 111 109
by Jesmin Akther | Oct 10, 2021 | C Programming
Example 1: C program to check perfect number
What is perfect number?
Perfect number is a positive number which sum of all positive divisors excluding that number is equal to that number. For example 6 is perfect number since divisor of 6 are 1, 2 and 3. Sum of its divisor is
1 + 2+ 3 =6 Note: 6 is the smallest perfect number.
Next perfect number is 28 since 1+ 2 + 4 + 7 + 14 = 28
Some more perfect numbers: 496, 8128
#include<stdio.h>
int main(){
int n,i=1,sum=0;
printf("Enter a number: ");
scanf("%d",&n);
while(i<n){
if(n%i==0)
sum=sum+i;
i++;
}
if(sum==n)
printf("%d is a perfect number",i);
else
printf("%d is not a perfect number",i);
return 0;
}
Sample output:
Enter a number: 6
6 is a perfect number
Similar Example:
Write a c program to check given number is perfect number or not.
Tips:
if(sum==n)
printf(“%d is a perfect number”,i);
else
printf(“%d is not a perfect number”,i);
Example 2: How to print prime numbers from 1 to 100 in c
Definition of prime number:
A natural number greater than one has not any other divisors except 1 and itself. In other word we can say which has only two divisors 1 and number itself. For example: 5
Their divisors are 1 and 5.
Note: 2 is only even prime number.
Logic for prime number in c
We will take a loop and divide number from 2 to number/2. If the number is not divisible by any of the numbers then we will print it as prime number.
Example of prime numbers : 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199 etc.
#include<stdio.h>
int main(){
int num,i,count;
for(num = 1;num<=100;num++){
count = 0;
for(i=2;i<=num/2;i++){
if(num%i==0){
count++;
break;
}
}
if(count==0 && num!= 1)
printf("%d ",num);
}
return 0;
}
Output:
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97
Write a c program to check whether a number is strong or not
Definition of strong number:
A number is called strong number if sum of the factorial of its digit is equal to number itself. For example: 145 since
1! + 4! + 5! = 1 + 24 + 120 = 145
#include<stdio.h>
int main(){
int num,i,f,r,sum,temp;
int min,max;
printf("Enter minimum range: ");
scanf("%d",&min);
printf("Enter maximum range: ");
scanf("%d",&max);
printf("Strong numbers in given range are: ");
for(num=min; num <= max; num++){
temp = num;
sum=0;
while(temp){
i=1;
f=1;
r=temp%10;
while(i<=r){
f=f*i;
i++;
}
sum=sum+f;
temp=temp/10;
}
if(sum==num)
printf("%d ",num);
}
return 0;
}
Sample output:
Enter minimum range: 100
Enter maximum range: 100000
Strong numbers in given range are: 145 40585
C program for odd or even number
Algorithm:
Number is called even number if it is divisible by two otherwise odd.
Example of even numbers: 0,2,4,8,9,10 etc.
Example of odd numbers: 1, 3,5,7,9 etc.
- C program to check even or odd
- C determine odd or even
- How to check odd number in c
- How to determine odd or even in c
- C even odd test
#include<stdio.h>
int main(){
int number;
printf("Enter any integer: ");
scanf("%d",&number);
if(number % 2 ==0)
printf("%d is even number.",number);
else
printf("%d is odd number.",number);
return 0;
}
Sample output:
Enter any integer: 5
5 is odd number.
check the given number is palindrome number or not using c program
- Write a c program for palindrome
- C program to find palindrome of a number
- Palindrome number in c language
#include<stdio.h>
int main(){
int num,r,sum,temp;
int min,max;
printf("Enter the minimum range: ");
scanf("%d",&min);
printf("Enter the maximum range: ");
scanf("%d",&max);
printf("Palindrome numbers in given range are: ");
for(num=min;num<=max;num++){
temp=num;
sum=0;
while(temp){
r=temp%10;
temp=temp/10;
sum=sum*10+r;
}
if(num==sum)
printf("%d ",num);
}
return 0;
}
Sample output:
Enter the minimum range: 1
Enter the maximum range: 50
Palindrome numbers in given range are: 1 2 3 4 5 6 7 8 9 11 22 33 44
Code 3: How to check if a number is a palindrome using for loop
#include<stdio.h>
int main(){
int num,r,sum=0,temp;
printf("Enter a number: ");
scanf("%d",&num);
for(temp=num;num!=0;num=num/10){
r=num%10;
sum=sum*10+r;
}
if(temp==sum)
printf("%d is a palindrome",temp);
else
printf("%d is not a palindrome",temp);
return 0;
}
Sample output:
Enter a number: 1221
1221 is a palindrome
Code 4: C program to check ifa number is palindrome using recursion
#include<stdio.h>
int checkPalindrome(int);
int main(){
int num,sum;
printf("Enter a number: ");
scanf("%d",&num);
sum = checkPalindrome(num);
if(num==sum)
printf("%d is a palindrome",num);
else
printf("%d is not a palindrome",num);
return 0;
}
int checkPalindrome(int num){
static int sum=0,r;
if(num!=0){
r=num%10;
sum=sum*10+r;
checkPalindrome(num/10);
}
return sum;
}
Sample output:
Enter a number: 25
25 is not a palindrome
Write a c program to check given string is palindrome number or not
Definition of Palindrome string:
A string is called palindrome if it symmetric. In other word a string is called palindrome if string remains same if its characters are reversed. For example: asdsa
If we will reverse it will remain same i.e. asdsa
Example of string palindrome: a,b, aa,aba,qwertrewq etc.
#include<string.h>
#include<stdio.h>
int main(){
char *str,*rev;
int i,j;
printf("\nEnter a string:");
scanf("%s",str);
for(i=strlen(str)-1,j=0;i>=0;i--,j++)
rev[j]=str[i];
rev[j]='\0';
if(strcmp(rev,str))
printf("\nThe string is not a palindrome");
else
printf("\nThe string is a palindrome");
return 0;
}
TO FIND FIBONACCI SERIES USING C PROGRAM
Code 1:
- Write a program to generate the Fibonacci series in c
- Write a program to print Fibonacci series in c
- Basic c programs Fibonacci series
- How to print Fibonacci series in c
- How to find Fibonacci series in c programming
- Fibonacci series in c using for loop
#include<stdio.h>
int main(){
int k,r;
long int i=0l,j=1,f;
//Taking maximum numbers form user
printf("Enter the number range:");
scanf("%d",&r);
printf("FIBONACCI SERIES: ");
printf("%ld %ld",i,j); //printing firts two values.
for(k=2;k<r;k++){
f=i+j;
i=j;
j=f;
printf(" %ld",j);
}
return 0;
}
Sample output:
Enter the number range: 15
FIBONACCI SERIES: 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
What is Fibonacci series?
Logic of Fibonacci series Definition of Fibonacci numbers:
We assume first two Fibonacci are 0 and 1. A series of numbers in which each sequent number is sum of its two previous numbers is known as Fibonacci series and each numbers are called Fibonacci numbers. So Fibonacci numbers is
Algorithm for Fibonacci series
Fn = Fn-2 + Fn-1
Example of Fibonacci series:0 , 1 ,1 , 2 , 3 , 5 , 8 , 13 , 21 , 34 , 55 …
5 is Fibonacci number since sum of its two previous number i.e. 2 and 3 is 5
8 is Fibonacci number since sum of its two previous number i.e. 3 and 5 is 8 and so on.
TO FIND FACTORIAL OF A NUMBER USING C PROGRAM
Factorial value
Factorial of number is defined as:
Factorial (n) = 1*2*3 … * n
For example: Factorial of 5 = 1*2*3*4*5 = 120
Note: Factorial of zero = 1
- C code for factorial of a number
- C program to find the factorial of a given number
- Factorial program in c using while loop
4.Factorial program in c without using recursion
#include<stdio.h>
int main(){
int i=1,f=1,num;
printf("Enter a number: ");
scanf("%d",&num);
while(i<=num){
f=f*i;
i++;
}
printf("Factorial of %d is: %d",num,f);
return 0;
}
Sample output:
Enter a number: 5
Factorial of 5 is: 120
Code 2:
- Factorial program in c using for loop
- Simple factorial program in c
- C program to calculate factorial
#include<stdio.h>
int main(){
int i,f=1,num;
printf("Enter a number: ");
scanf("%d",&num);
for(i=1;i<=num;i++)
f=f*i;
printf("Factorial of %d is: %d",num,f);
return 0;
}
Write a c program for Floyd’s triangle.
What is Floyd’s triangle?
Definition of floyd’s triangle:
Floyd’s triangle is a right angled-triangle using the natural numbers. Examples of floyd’s triangle:
Example 1
1
2 3
4 5 6
7 8 9 10
Example 2:
1
2 3
4 5 6
7 8 9 10
11 12 13 14 15
16 17 18 19 20 21
- Write a c program to print Floyd’s triangle
- C program to display Floyd’s triangle
- How to print Floyd’s triangle in c
#include<stdio.h>
int main(){
int i,j,r,k=1;
printf("Enter the range: ");
scanf("%d",&r);
printf("FLOYD'S TRIANGLE\n\n");
for(i=1;i<=r;i++){
for(j=1;j<=i;j++,k++)
printf(" %d",k);
printf("\n");
}
return 0;
}
Sample output:
Enter the range: 10
FLOYD’S TRIANGLE
1
2 3
4 5 6
7 8 9 10
11 12 13 14 15
16 17 18 19 20 21
22 23 24 25 26 27 28
29 30 31 32 33 34 35 36
37 38 39 40 41 42 43 44 45
46 47 48 49 50 51 52 53 54 55
Write a c program to print Pascal triangle.
Sample output:
Enter the no. of lines: 8
1
1 1
1 2 1
1 3 3 1
1 4 6 4 1
1 5 10 10 5 1
1 6 15 20 15 6 1
1 7 21 35 35 21 7 1
- Pascal triangle in c without using array
- C code to print Pascal triangle
- 3. Simple c program for Pascal triangle
- C program to generate Pascal triangle
- Pascal triangle program in c language
- C program to print Pascal triangle using for loop
#include<stdio.h>
long fact(int);
int main(){
int line,i,j;
printf("Enter the no. of lines: ");
scanf("%d",&line);
for(i=0;i<line;i++){
for(j=0;j<line-i-1;j++)
printf(" ");
for(j=0;j<=i;j++)
printf("%ld ",fact(i)/(fact(j)*fact(i-j)));
printf("\n");
}
return 0;
}
long fact(int num){
long f=1;
int i=1;
while(i<=num){
f=f*i;
i++;
}
return f;
}
TO FIND MULTIPLICATION TABLE USING C PROGRAM
- Multiplication tables in c program
- Write a c program to print multiplication table
- Code for multiplication table in c
- Multiplication table in c language
- Write a c program to print multiplication table
#include<stdio.h>
int main(){
int r,i,j,k;
printf("Enter the number range: ");
scanf("%d",&r);
for(i=1;i<=r;i++){
for(j=1;j<=10;j++)
printf("%d*%d=%d ",i,j,i*j);
printf("\n");
}
return 0;
}
Sample Output:
Enter the number range: 5
1*1=1 1*2=2 1*3=3 1*4=4 1*5=5 1*6=6 1*7=7 1*8=8 1*9=9 1*10=10
2*1=2 2*2=4 2*3=6 2*4=8 2*5=10 2*6=12 2*7=14 2*8=16 2*9=18 2*10=20
3*1=3 3*2=6 3*3=9 3*4=12 3*5=15 3*6=18 3*7=21 3*8=24 3*9=27 3*10=30
4*1=4 4*2=8 4*3=12 4*4=16 4*5=20 4*6=24 4*7=28 4*8=32 4*9=36 4*10=40
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25 5*6=30 5*7=35 5*8=40 5*9=45 5*10=50
PRINTING ASCII VALUE USING C PROGRAM
Printing ascii value using c program
C code for ASCII table
C program to display ASCII values
#include<stdio.h>
int main(){
int i;
for(i=0;i<=255;i++)
printf("ASCII value of character %c: %d\n",i,i);
return 0;}
Output:
ASCII value of character : 0
ASCII value of character ☺: 1
ASCII value of character ☻: 2
ASCII value of character ♥: 3
ASCII value of character ♦: 4
ASCII value of character ♣: 5
ASCII value of character ♠: 6
ASCII value of character : 7
ASCII value of character: 8
ASCII value of character :
ASCII value of character
: 10
ASCII value of character ♂: 11
ASCII value of character ♀: 12
: 13I value of character
ASCII value of character ♫: 14
ASCII value of character ☼: 15
ASCII value of character ►: 16
ASCII value of character ◄: 17
ASCII value of character ↕: 18
ASCII value of character ‼: 19
ASCII value of character ¶: 20
ASCII value of character §: 21
ASCII value of character ▬: 22
ASCII value of character ↨: 23
ASCII value of character ↑: 24
ASCII value of character ↓: 25
ASCII value of character →: 26
ASCII value of character ←: 27
ASCII value of character ∟: 28
ASCII value of character ↔: 29
ASCII value of character ▲: 30
ASCII value of character ▼: 31
ASCII value of character : 32
ASCII value of character !: 33
ASCII value of character “: 34
ASCII value of character #: 35
ASCII value of character $: 36
ASCII value of character %: 37
ASCII value of character &: 38
ASCII value of character ‘: 39
ASCII value of character (: 40
ASCII value of character ): 41
ASCII value of character *: 42
ASCII value of character +: 43
ASCII value of character ,: 44
ASCII value of character -: 45
ASCII value of character .: 46
ASCII value of character /: 47
ASCII value of character 0: 48
ASCII value of character 1: 49
ASCII value of character 2: 50
ASCII value of character 3: 51
ASCII value of character 4: 52
ASCII value of character 5: 53
ASCII value of character 6: 54
ASCII value of character 7: 55
ASCII value of character 8: 56
ASCII value of character 9: 57
ASCII value of character :: 58
ASCII value of character ;: 59
ASCII value of character <: 60
ASCII value of character =: 61
ASCII value of character >: 62
ASCII value of character ?: 63
ASCII value of character @: 64
ASCII value of character A: 65
ASCII value of character B: 66
ASCII value of character C: 67
ASCII value of character D: 68
ASCII value of character E: 69
ASCII value of character F: 70
ASCII value of character G: 71
ASCII value of character H: 72
ASCII value of character I: 73
ASCII value of character J: 74
ASCII value of character K: 75
ASCII value of character L: 76
ASCII value of character M: 77
ASCII value of character N: 78
ASCII value of character O: 79
ASCII value of character P: 80
ASCII value of character Q: 81
ASCII value of character R: 82
ASCII value of character S: 83
ASCII value of character T: 84
ASCII value of character U: 85
ASCII value of character V: 86
ASCII value of character W: 87
ASCII value of character X: 88
ASCII value of character Y: 89
ASCII value of character Z: 90
ASCII value of character [: 91
ASCII value of character \: 92
ASCII value of character ]: 93
ASCII value of character ^: 94
ASCII value of character _: 95
ASCII value of character `: 96
ASCII value of character a: 97
ASCII value of character b: 98
ASCII value of character c: 99
ASCII value of character d: 100
ASCII value of character e: 101
ASCII value of character f: 102
ASCII value of character g: 103
ASCII value of character h: 104
ASCII value of character i: 105
ASCII value of character j: 106
ASCII value of character k: 107
ASCII value of character l: 108
ASCII value of character m: 109
ASCII value of character n: 110
ASCII value of character o: 111
ASCII value of character p: 112
ASCII value of character q: 113
ASCII value of character r: 114
ASCII value of character s: 115
ASCII value of character t: 116
ASCII value of character u: 117
ASCII value of character v: 118
ASCII value of character w: 119
ASCII value of character x: 120
ASCII value of character y: 121
ASCII value of character z: 122
ASCII value of character {: 123
ASCII value of character |: 124
ASCII value of character }: 125
ASCII value of character ~: 126
ASCII value of character ⌂: 127
ASCII value of character Ç: 128
ASCII value of character ü: 129
ASCII value of character é: 130
ASCII value of character â: 131
ASCII value of character ä: 132
ASCII value of character à: 133
ASCII value of character å: 134
ASCII value of character ç: 135
ASCII value of character ê: 136
ASCII value of character ë: 137
ASCII value of character è: 138
ASCII value of character ï: 139
ASCII value of character î: 140
ASCII value of character ì: 141
ASCII value of character Ä: 142
ASCII value of character Å: 143
ASCII value of character É: 144
ASCII value of character æ: 145
ASCII value of character Æ: 146
ASCII value of character ô: 147
ASCII value of character ö: 148
ASCII value of character ò: 149
ASCII value of character û: 150
ASCII value of character ù: 151
ASCII value of character ÿ: 152
ASCII value of character Ö: 153
ASCII value of character Ü: 154
ASCII value of character ¢: 155
ASCII value of character £: 156
ASCII value of character ¥: 157
ASCII value of character ₧: 158
ASCII value of character ƒ: 159
ASCII value of character á: 160
ASCII value of character í: 161
ASCII value of character ó: 162
ASCII value of character ú: 163
ASCII value of character ñ: 164
ASCII value of character Ñ: 165
ASCII value of character ª: 166
ASCII value of character º: 167
ASCII value of character ¿: 168
ASCII value of character ⌐: 169
ASCII value of character ¬: 170
ASCII value of character ½: 171
ASCII value of character ¼: 172
ASCII value of character ¡: 173
ASCII value of character «: 174
ASCII value of character »: 175
ASCII value of character ░: 176
ASCII value of character ▒: 177
ASCII value of character ▓: 178
ASCII value of character │: 179
ASCII value of character ┤: 180
ASCII value of character ╡: 181
ASCII value of character ╢: 182
ASCII value of character ╖: 183
ASCII value of character ╕: 184
ASCII value of character ╣: 185
ASCII value of character ║: 186
ASCII value of character ╗: 187
ASCII value of character ╝: 188
ASCII value of character ╜: 189
ASCII value of character ╛: 190
ASCII value of character ┐: 191
ASCII value of character └: 192
ASCII value of character ┴: 193
ASCII value of character ┬: 194
ASCII value of character ├: 195
ASCII value of character ─: 196
ASCII value of character ┼: 197
ASCII value of character ╞: 198
ASCII value of character ╟: 199
ASCII value of character ╚: 200
ASCII value of character ╔: 201
ASCII value of character ╩: 202
ASCII value of character ╦: 203
ASCII value of character ╠: 204
ASCII value of character ═: 205
ASCII value of character ╬: 206
ASCII value of character ╧: 207
ASCII value of character ╨: 208
ASCII value of character ╤: 209
ASCII value of character ╥: 210
ASCII value of character ╙: 211
ASCII value of character ╘: 212
ASCII value of character ╒: 213
ASCII value of character ╓: 214
ASCII value of character ╫: 215
ASCII value of character ╪: 216
ASCII value of character ┘: 217
ASCII value of character ┌: 218
ASCII value of character █: 219
ASCII value of character ▄: 220
ASCII value of character ▌: 221
ASCII value of character ▐: 222
ASCII value of character ▀: 223
ASCII value of character α: 224
ASCII value of character ß: 225
ASCII value of character Γ: 226
ASCII value of character π: 227
ASCII value of character Σ: 228
ASCII value of character σ: 229
ASCII value of character µ: 230
ASCII value of character τ: 231
ASCII value of character Φ: 232
ASCII value of character Θ: 233
ASCII value of character Ω: 234
ASCII value of character δ: 235
ASCII value of character ∞: 236
ASCII value of character φ: 237
ASCII value of character ε: 238
ASCII value of character ∩: 239
ASCII value of character ≡: 240
ASCII value of character ±: 241
ASCII value of character ≥: 242
ASCII value of character ≤: 243
ASCII value of character ⌠: 244
ASCII value of character ⌡: 245
ASCII value of character ÷: 246
ASCII value of character ≈: 247
ASCII value of character °: 248
ASCII value of character ∙: 249
ASCII value of character ·: 250
ASCII value of character √: 251
ASCII value of character ⁿ: 252
ASCII value of character ²: 253
ASCII value of character ■: 254
ASCII value of character : 255
C program to print hello world without using semicolon
#include<stdio.h>
void main(){
if(printf("Hello world")){
}
}
Solution: 2
#include<stdio.h>
void main(){
while(!printf("Hello world")){
}
}
Solution: 3
#include<stdio.h>
void main(){
switch(printf("Hello world")){
}
}
CONVERSION OF DECIMAL TO BINARY USING C PROGRAM
#include<stdio.h>
int main(){
long int m,no=0,a=1;
int n,rem;
printf("Enter any decimal number->");
scanf("%d",&n);
m=n;
while(n!=0){
rem=n%2;
no=no+rem*a;
n=n/2;
a=a*10;
}
printf("The value %ld in binary is->",m);
printf("%ld",no);
return 0;
}
C code for binary to decimal conversion:
#include<stdio.h>
int main(){
long int binaryNumber,decimalNumber=0,j=1,remainder;
printf("Enter any number any binary number: ");
scanf("%ld",&binaryNumber);
while(binaryNumber!=0){
remainder=binaryNumber%10;
decimalNumber=decimalNumber+remainder*j;
j=j*2;
binaryNumber=binaryNumber/10;
}
printf("Equivalent decimal value: %ld",decimalNumber);
return 0;
}
Sample output:
Enter any number any binary number: 1101
Equivalent decimal value: 13
Algorithm:
Binary number system: It is base 2 number system which uses the digits from 0 and 1.
Decimal number system:
It is base 10 number system which uses the digits from 0 to 9
Convert from binary to decimal algorithm:
For this we multiply each digit separately from right side by 1, 2, 4, 8, 16 … respectively then add them.
Binary number to decimal conversion with example:
For example we want to convert binary number 101111 to decimal:
Step1: 1 * 1 = 1
Step2: 1 * 2 = 2
Step3: 1 * 4 = 4
Step4: 1 * 8 = 8
Step5: 0 * 16 = 0
Step6: 1 * 32 = 32
Its decimal value: 1 + 2 + 4+ 8+ 0+ 32 = 47
That is (101111)2 = (47)10
by Jesmin Akther | Sep 22, 2021 | C Programming
Input Output in C
In C programming, Input provides a set of built-in functions to read the given input and feed it to the program as per requirement. When we say Output, it means to display some data on screen, printer, or in any file.
The getchar() and putchar() Functions
The int getchar(void) function reads the next available character from the screen and returns it as an integer. This function reads only single character at a time. You can use this method in the loop in case you want to read more than one character from the screen.
The int putchar(int c) function puts the passed character on the screen and returns the same character. This function puts only single character at a time. You can use this method in the loop in case you want to display more than one character on the screen. Check the following example −
#include <stdio.h>
int main( ) {
int c;
printf( "Enter a value :");
c = getchar( );
printf( "\nYou entered: ");
putchar( c );
return 0;
}
When the above code is compiled and executed, it waits for you to input some text. When you enter a text and press enter, then the program proceeds and reads only a single character and displays it as follows −
$./a.out
Enter a value : this is test
You entered: t
The gets() and puts() Functions
The char *gets(char *s) function reads a line from stdin into the buffer pointed to by s until either a terminating newline or EOF (End of File).
The int puts(const char *s) function writes the string ‘s’ and ‘a’ trailing newline to stdout.
#include <stdio.h>
int main( ) {
char str[100];
printf( "Enter a value :");
gets( str );
printf( "\nYou entered: ");
puts( str );
return 0;
}
When the above code is compiled and executed, it waits for you to input some text. When you enter a text and press enter, then the program proceeds and reads the complete line till end, and displays it as follows −
$./a.out
Enter a value : this is test
You entered: this is test
The scanf() and printf() Functions
The int scanf(const char *format, …) function reads the input from the standard input stream stdin and scans that input according to the format provided.
The int printf(const char *format, …) function writes the output to the standard output stream stdout and produces the output according to the format provided.
The format can be a simple constant string, but you can specify %s, %d, %c, %f, etc., to print or read strings, integer, character or float respectively. There are many other formatting options available which can be used based on requirements. Let us now proceed with a simple example to understand the concepts better −
#include <stdio.h>
int main( ) {
char str[100];
int i;
printf( "Enter a value :");
scanf("%s %d", str, &i);
printf( "\nYou entered: %s %d ", str, i);
return 0;
}
When the above code is compiled and executed, it waits for you to input some text. When you enter a text and press enter, then program proceeds and reads the input and displays it as follows −
$./a.out
Enter a value : seven 7
You entered: seven 7
It should be noted that scanf() expects input in the same format as you provided %s and %d, which means you have to provide valid inputs like “string integer”. If you provide “string string” or “integer integer”, then it will be assumed as wrong input. Secondly, while reading a string, scanf() stops reading as soon as it encounters a space, so “this is test” are three strings for scanf().
Type Casting in C
Converting one datatype into another is known as type casting or, type-conversion. For example, if you want to store a ‘long’ value into a simple integer then you can type cast ‘long’ to ‘int’. You can convert the values from one type to another explicitly using the cast operator as follows −
(type_name) expression
Consider the following example where the cast operator causes the division of one integer variable by another to be performed as a floating-point operation:
#include <stdio.h>
main() {
int sum = 17, count = 5;
double mean;
mean = (double) sum / count;
printf("Value of mean : %f\n", mean );
}
When the above code is compiled and executed, it produces the following result :
Value of mean : 3.400000
It should be noted here that the cast operator has precedence over division, so the value of sum is first converted to type double and finally it gets divided by count yielding a double value.
Type conversions can be implicit which is performed by the compiler automatically, or it can be specified explicitly through the use of the cast operator. It is considered good programming practice to use the cast operator whenever type conversions are necessary.
Memory Management in C
The C programming language provides several functions for memory allocation and management. These functions can be found in the <stdlib.h> header file.
| Sr.No. |
Function & Description |
| 1 |
void *calloc(int num, int size);
This function allocates an array of num elements each of which size in bytes will be size. |
| 2 |
void free(void *address);
This function releases a block of memory block specified by address. |
| 3 |
void *malloc(size_t size);
This function allocates an array of num bytes and leave them uninitialized. |
| 4 |
void *realloc(void *address, int newsize);
This function re-allocates memory extending it upto newsize. |
Allocating Memory Dynamically
While programming, if you are aware of the size of an array, then it is easy and you can define it as an array. For example, to store a name of any person, it can go up to a maximum of 100 characters, so you can define something as follows:
char name[100];
But now let us consider a situation where you have no idea about the length of the text you need to store, for example, you want to store a detailed description about a topic. Here we need to define a pointer to character without defining how much memory is required and later, based on requirement, we can allocate memory as shown in the below example:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char name[100];
char *description;
strcpy(name, "Zara Ali");
/* allocate memory dynamically */
description = malloc( 200 * sizeof(char) );
if( description == NULL ) {
fprintf(stderr, "Error - unable to allocate required memory\n");
} else {
strcpy( description, "Zara ali a DPS student in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
}
When the above code is compiled and executed, it produces the following result.
Name = Zara Ali
Description: Zara ali a DPS student in class 10th
Same program can be written using calloc(); only thing is you need to replace malloc with calloc as follows:
calloc(200, sizeof(char));
So you have complete control and you can pass any size value while allocating memory, unlike arrays where once the size defined, you cannot change it.
Resizing and Releasing Memory
When your program comes out, operating system automatically release all the memory allocated by your program but as a good practice when you are not in need of memory anymore then you should release that memory by calling the function free().
Alternatively, you can increase or decrease the size of an allocated memory block by calling the function realloc(). Let us check the above program once again and make use of realloc() and free() functions −
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main() {
char name[100];
char *description;
strcpy(name, "Zara Ali"); /* allocate memory dynamically */
description = malloc( 30 * sizeof(char) );
if( description == NULL ) {
fprintf(stderr, "Error - unable to allocate required memory\n");
} else {
strcpy( description, "Zara ali a DPS student.");
} /* suppose you want to store bigger description */
description = realloc( description, 100 * sizeof(char) );
if( description == NULL ) {
fprintf(stderr, "Error - unable to allocate required memory\n");
} else {
strcat( description, "She is in class 10th");
}
printf("Name = %s\n", name );
printf("Description: %s\n", description );
/* release memory using free() function */
free(description);
}
When the above code is compiled and executed, it produces the following result.
Name = Zara Ali
Description: Zara ali a DPS student.She is in class 10th
You can try the above example without re-allocating extra memory, and strcat() function will give an error due to lack of available memory in description.
by Jesmin Akther | Sep 22, 2021 | C Programming
Union – C
A union is a special data type available in C that allows to store different data types in the same memory location. You can define a union with many members, but only one member can contain a value at any given time. Unions provide an efficient way of using the same memory location for multiple-purpose.
Defining a Union
To define a union, you must use the union statement in the same way as you did while defining a structure. The union statement defines a new data type with more than one member for your program. The format of the union statement is as follows −
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];
The union tag is optional and each member definition is a normal variable definition, such as int i; or float f; or any other valid variable definition. At the end of the union’s definition, before the final semicolon, you can specify one or more union variables but it is optional. Here is the way you would define a union type named Data having three members i, f, and str −
union Data {
int i;
float f;
char str[20];
} data;
Now, a variable of Data type can store an integer, a floating-point number, or a string of characters. It means a single variable, i.e., same memory location, can be used to store multiple types of data. You can use any built-in or user defined data types inside a union based on your requirement.
The memory occupied by a union will be large enough to hold the largest member of the union. For example, in the above example, Data type will occupy 20 bytes of memory space because this is the maximum space which can be occupied by a character string. The following example displays the total memory size occupied by the above union −
#include <stdio.h>
#include <string.h>
union Data {
int i; float f; char str[20];
};
int main( ) {
union Data data;
printf( "Memory size occupied by data : %d\n", sizeof(data));
return 0;
}
When the above code is compiled and executed, it produces the following result −
Memory size occupied by data : 20
Accessing Union Members
To access any member of a union, we use the member access operator (.). The member access operator is coded as a period between the union variable name and the union member that we wish to access. You would use the keyword union to define variables of union type. The following example shows how to use unions in a program −
#include <stdio.h>
#include <string.h>
union Data {
int i; float f; char str[20];
};
int main( ) {
union Data data;
data.i = 10;
data.f = 220.5;
strcpy( data.str, "C Programming");
printf( "data.i : %d\n", data.i);
printf( "data.f : %f\n", data.f);
printf( "data.str : %s\n", data.str);
return 0;
}
When the above code is compiled and executed, it produces the following result −
data.i : 1917853763
data.f : 4122360580327794860452759994368.000000
data.str : C Programming
The C programming language provides a keyword called typedef, which you can use to give a type a new name. Following is an example to define a term BYTE for one-byte numbers −
typedef unsigned char BYTE;
After this type definition, the identifier BYTE can be used as an abbreviation for the type unsigned char, for example..
BYTE b1, b2;
By convention, uppercase letters are used for these definitions to remind the user that the type name is really a symbolic abbreviation, but you can use lowercase, as follows −
typedef unsigned char byte;
You can use typedef to give a name to your user defined data types as well. For example, you can use typedef with structure to define a new data type and then use that data type to define structure variables directly as follows −
#include <stdio.h>
#include <string.h>
typedef struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
}
Book;
int main( ) {
Book book;
strcpy( book.title, "C Programming");
strcpy( book.author, "Nuha Ali");
strcpy( book.subject, "C Programming Tutorial");
book.book_id = 6495407;
printf( "Book title : %s\n", book.title);
printf( "Book author : %s\n", book.author);
printf( "Book subject : %s\n", book.subject);
printf( "Book book_id : %d\n", book.book_id);
return 0;
}
When the above code is compiled and executed, it produces the following result −
Book title : C Programming
Book author : Nuha Ali
Book subject : C Programming Tutorial
Book book_id : 6495407
typedef vs #define
#define is a C-directive which is also used to define the aliases for various data types similar to typedef but with the following differences −
- typedef is limited to giving symbolic names to types only where as #define can be used to define alias for values as well, q., you can define 1 as ONE etc.
- typedef interpretation is performed by the compiler whereas #define statements are processed by the pre-processor.
The following example shows how to use #define in a program −
#include <stdio.h>
#define TRUE 1
#define FALSE 0
int main( ) {
printf( "Value of TRUE : %d\n", TRUE);
printf( "Value of FALSE : %d\n", FALSE);
return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of TRUE : 1
Value of FALSE : 0
by Jesmin Akther | Sep 22, 2021 | C Programming
C- Strings
Strings are actually one-dimensional array of characters terminated by a null character ‘\0’. Thus a null-terminated string contains the characters that comprise the string followed by a null.
The following declaration and initialization create a string consisting of the word “Hello”. To hold the null character at the end of the array, the size of the character array containing the string is one more than the number of characters in the word “Hello.”
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
If you follow the rule of array initialization then you can write the above statement as follows −
char greeting[] = "Hello";
Following is the memory presentation of the above defined string in C/C++ −
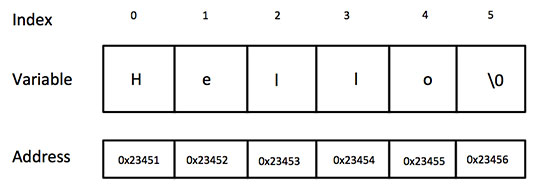
Actually, you do not place the null character at the end of a string constant. The C compiler automatically places the ‘\0’ at the end of the string when it initializes the array. Let us try to print the above mentioned string −
#include <stdio.h>
int main () {
char greeting[6] = {'H', 'e', 'l', 'l', 'o', '\0'};
printf("Greeting message: %s\n", greeting );
return 0;
}
When the above code is compiled and executed, it produces the following result −
Greeting message: Hello
C supports a wide range of functions that manipulate null-terminated strings −
| Sr.No. |
Function & Purpose |
| 1 |
strcpy(s1, s2);
Copies string s2 into string s1. |
| 2 |
strcat(s1, s2);
Concatenates string s2 onto the end of string s1. |
| 3 |
strlen(s1);
Returns the length of string s1. |
| 4 |
strcmp(s1, s2);
Returns 0 if s1 and s2 are the same; less than 0 if s1<s2; greater than 0 if s1>s2. |
| 5 |
strchr(s1, ch);
Returns a pointer to the first occurrence of character ch in string s1. |
| 6 |
strstr(s1, s2);
Returns a pointer to the first occurrence of string s2 in string s1. |
The following example uses some of the above-mentioned functions:
#include <stdio.h>
#include <string.h>
int main () {
char str1[12] = "Hello";
char str2[12] = "World";
char str3[12];
int len ; /* copy str1 into str3 */
strcpy(str3, str1);
printf("strcpy( str3, str1) : %s\n", str3 ); /* concatenates str1 and str2 */
strcat( str1, str2);
printf("strcat( str1, str2): %s\n", str1 ); /* total lenghth of str1 after concatenation */
len = strlen(str1);
printf("strlen(str1) : %d\n", len );
return 0;
}
When the above code is compiled and executed, it produces the following result −
strcpy( str3, str1) : Hello strcat( str1, str2): HelloWorld strlen(str1) : 10
C- Structures
Arrays allow to define type of variables that can hold several data items of the same kind. Similarly structure is another user defined data type available in C that allows to combine data items of different kinds.
Structures are used to represent a record. Suppose you want to keep track of your books in a library. You might want to track the following attributes about each book −
- Title
- Author
- Subject
- Book ID
Defining a Structure
To define a structure, you must use the struct statement. The struct statement defines a new data type, with more than one member. The format of the struct statement is as follows −
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];
The structure tag is optional and each member definition is a normal variable definition, such as int i; or float f; or any other valid variable definition. At the end of the structure’s definition, before the final semicolon, you can specify one or more structure variables but it is optional. Here is the way you would declare the Book structure −
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
} book;
Accessing Structure Members
To access any member of a structure, we use the member access operator (.). The member access operator is coded as a period between the structure variable name and the structure member that we wish to access. You would use the keyword struct to define variables of structure type. The following example shows how to use a structure in a program:
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id;
};
int main( ) {
struct Books Book1; /* Declare Book1 of type Book */
struct Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407;
/* book 2 specification */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700;
/* print Book1 info */
printf( "Book 1 title : %s\n", Book1.title);
printf( "Book 1 author : %s\n", Book1.author);
printf( "Book 1 subject : %s\n", Book1.subject);
printf( "Book 1 book_id : %d\n", Book1.book_id);
/* print Book2 info */
printf( "Book 2 title : %s\n", Book2.title);
printf( "Book 2 author : %s\n", Book2.author);
printf( "Book 2 subject : %s\n", Book2.subject);
printf( "Book 2 book_id : %d\n", Book2.book_id);
return 0;
}
When the above code is compiled and executed, it produces the following result −
Book 1 title : C Programming
Book 1 author : Nuha Ali
Book 1 subject : C Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : Telecom Billing
Book 2 author : Zara Ali
Book 2 subject : Telecom Billing Tutorial
Book 2 book_id : 6495700
Structures as Function Arguments
You can pass a structure as a function argument in the same way as you pass any other variable or pointer.
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id; }; /* function declaration */
void printBook( struct Books book );
int main( ) {
struct Books Book1; /* Declare Book1 of type Book */
struct Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407; /* book 2 specification */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700; /* print Book1 info */
printBook( Book1 ); /* Print Book2 info */
printBook( Book2 );
return 0;
}
void printBook( struct Books book ) {
printf( "Book title : %s\n", book.title);
printf( "Book author : %s\n", book.author);
printf( "Book subject : %s\n", book.subject);
printf( "Book book_id : %d\n", book.book_id);
}
When the above code is compiled and executed, it produces the following result −
Book title : C Programming
Book author : Nuha Ali
Book subject : C Programming Tutorial
Book book_id : 6495407
Book title : Telecom Billing
Book author : Zara Ali
Book subject : Telecom Billing Tutorial
Book book_id : 6495700
Pointers to Structures
You can define pointers to structures in the same way as you define pointer to any other variable −
struct Books *struct_pointer;
Now, you can store the address of a structure variable in the above defined pointer variable. To find the address of a structure variable, place the ‘&’; operator before the structure’s name as follows −
struct_pointer = &Book1;
To access the members of a structure using a pointer to that structure, you must use the → operator as follows −
struct_pointer->title;
Let us re-write the above example using structure pointer.
#include <stdio.h>
#include <string.h>
struct Books {
char title[50];
char author[50];
char subject[100];
int book_id; }; /* function declaration */
void printBook( struct Books *book );
int main( ) {
struct Books Book1; /* Declare Book1 of type Book */
struct Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
strcpy( Book1.title, "C Programming");
strcpy( Book1.author, "Nuha Ali");
strcpy( Book1.subject, "C Programming Tutorial");
Book1.book_id = 6495407; /* book 2 specification */
strcpy( Book2.title, "Telecom Billing");
strcpy( Book2.author, "Zara Ali");
strcpy( Book2.subject, "Telecom Billing Tutorial");
Book2.book_id = 6495700; /* print Book1 info by passing address of Book1 */
printBook( &Book1 ); /* print Book2 info by passing address of Book2 */ printBook( &Book2 );
return 0;
}
void printBook( struct Books *book ) {
printf( "Book title : %s\n", book->title);
printf( "Book author : %s\n", book->author);
printf( "Book subject : %s\n", book->subject);
printf( "Book book_id : %d\n", book->book_id);
}
When the above code is compiled and executed, it produces the following result −
Book title : C Programming
Book author : Nuha Ali
Book subject : C Programming Tutorial
Book book_id : 6495407
Book title : Telecom Billing
Book author : Zara Ali
Book subject : Telecom Billing Tutorial
Book book_id : 6495700
Bit Fields
Bit Fields allow the packing of data in a structure. This is especially useful when memory or data storage is at a premium. Typical examples include −
- Packing several objects into a machine word. e.g. 1 bit flags can be compacted.
- Reading external file formats — non-standard file formats could be read in, e.g., 9-bit integers.
C allows us to do this in a structure definition by putting :bit length after the variable. For example −
struct packed_struct {
unsigned int f1:1;
unsigned int f2:1;
unsigned int f3:1;
unsigned int f4:1;
unsigned int type:4;
unsigned int my_int:9;
} pack;
Here, the packed_struct contains 6 members: Four 1 bit flags f1..f3, a 4-bit type and a 9-bit my_int.
C automatically packs the above bit fields as compactly as possible, provided that the maximum length of the field is less than or equal to the integer word length of the computer. If this is not the case, then some compilers may allow memory overlap for the fields while others would store the next field in the next word.
by Jesmin Akther | Sep 22, 2021 | C Programming
C – Pointer
Pointers in C are easy and fun to learn. Some C programming tasks are performed more easily with pointers, and other tasks, such as dynamic memory allocation, cannot be performed without using pointers. So it becomes necessary to learn pointers to become a perfect C programmer. Let’s start learning them in simple and easy steps.
As you know, every variable is a memory location and every memory location has its address defined which can be accessed using ampersand (&) operator, which denotes an address in memory. Consider the following example, which prints the address of the variables defined −
#include <stdio.h>
int main () {
int var1; char var2[10];
printf("Address of var1 variable: %x\n", &var1 );
printf("Address of var2 variable: %x\n", &var2 );
return 0;
}
When the above code is compiled and executed, it produces the following result −
Address of var1 variable: bff5a400
Address of var2 variable: bff5a3f6
What are Pointers?
A pointer is a variable whose value is the address of another variable, i.e., direct address of the memory location. Like any variable or constant, you must declare a pointer before using it to store any variable address. The general form of a pointer variable declaration is −
type *var-name;
Here, type is the pointer’s base type; it must be a valid C data type and var-name is the name of the pointer variable. The asterisk * used to declare a pointer is the same asterisk used for multiplication. However, in this statement the asterisk is being used to designate a variable as a pointer. Take a look at some of the valid pointer declarations −
int *ip; /* pointer to an integer */
double *dp; /* pointer to a double */
float *fp; /* pointer to a float */
char *ch /* pointer to a character */
The actual data type of the value of all pointers, whether integer, float, character, or otherwise, is the same, a long hexadecimal number that represents a memory address. The only difference between pointers of different data types is the data type of the variable or constant that the pointer points to.
How to Use Pointers?
There are a few important operations, which we will do with the help of pointers very frequently. (a) We define a pointer variable, (b) assign the address of a variable to a pointer and (c) finally access the value at the address available in the pointer variable. This is done by using unary operator * that returns the value of the variable located at the address specified by its operand. The following example makes use of these operations −
#include <stdio.h>
int main () {
int var = 20; /* actual variable declaration */
int *ip; /* pointer variable declaration */
ip = &var; /* store address of var in pointer variable*/
printf("Address of var variable: %x\n", &var );
/* address stored in pointer variable */
printf("Address stored in ip variable: %x\n", ip );
/* access the value using the pointer */
printf("Value of *ip variable: %d\n", *ip );
return 0;
}
When the above code is compiled and executed, it produces the following result −
Address of var variable: bffd8b3c
Address stored in ip variable: bffd8b3c
Value of *ip variable: 20
NULL Pointers
It is always a good practice to assign a NULL value to a pointer variable in case you do not have an exact address to be assigned. This is done at the time of variable declaration. A pointer that is assigned NULL is called a null pointer.
The NULL pointer is a constant with a value of zero defined in several standard libraries. Consider the following program −
#include <stdio.h>
int main () {
int *ptr = NULL;
printf("The value of ptr is : %x\n", ptr );
return 0;
}
When the above code is compiled and executed, it produces the following result −
The value of ptr is 0
In most of the operating systems, programs are not permitted to access memory at address 0 because that memory is reserved by the operating system. However, the memory address 0 has special significance; it signals that the pointer is not intended to point to an accessible memory location. But by convention, if a pointer contains the null (zero) value, it is assumed to point to nothing.
To check for a null pointer, you can use an ‘if’ statement as follows −
if(ptr) /* succeeds if p is not null */
if(!ptr) /* succeeds if p is null */
C – Pointer arithmetic
A pointer in c is an address, which is a numeric value. Therefore, you can perform arithmetic operations on a pointer just as you can on a numeric value. There are four arithmetic operators that can be used on pointers: ++, –, +, and –
To understand pointer arithmetic, let us consider that ptr is an integer pointer which points to the address 1000. Assuming 32-bit integers, let us perform the following arithmetic operation on the pointer −
ptr++
After the above operation, the ptr will point to the location 1004 because each time ptr is incremented, it will point to the next integer location which is 4 bytes next to the current location. This operation will move the pointer to the next memory location without impacting the actual value at the memory location. If ptr points to a character whose address is 1000, then the above operation will point to the location 1001 because the next character will be available at 1001.
Incrementing a Pointer
We prefer using a pointer in our program instead of an array because the variable pointer can be incremented, unlike the array name which cannot be incremented because it is a constant pointer. The following program increments the variable pointer to access each succeeding element of the array −
#include <stdio.h>
const int MAX = 3; int main () {
int var[] = {10, 100, 200};
int i, *ptr; /* let us have array address in pointer */
ptr = var; for ( i = 0; i < MAX; i++) {
printf("Address of var[%d] = %x\n", i, ptr );
printf("Value of var[%d] = %d\n", i, *ptr );
/* move to the next location */
ptr++;
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Address of var[0] = bf882b30
Value of var[0] = 10
Address of var[1] = bf882b34
Value of var[1] = 100
Address of var[2] = bf882b38
Value of var[2] = 200
Decrementing a Pointer
The same considerations apply to decrementing a pointer, which decreases its value by the number of bytes of its data type as shown below:
#include <stdio.h>
const int MAX = 3;
int main () {
int var[] = {10, 100, 200};
int i, *ptr; /* let us have array address in pointer */
ptr = &var[MAX-1];
for ( i = MAX; i > 0; i--) {
printf("Address of var[%d] = %x\n", i-1, ptr );
printf("Value of var[%d] = %d\n", i-1, *ptr );
/* move to the previous location */ ptr--;
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Address of var[2] = bfedbcd8
Value of var[2] = 200
Address of var[1] = bfedbcd4
Value of var[1] = 100
Address of var[0] = bfedbcd0
Value of var[0] = 10
Pointer Comparisons
Pointers may be compared by using relational operators, such as ==, <, and >. If p1 and p2 point to variables that are related to each other, such as elements of the same array, then p1 and p2 can be meaningfully compared.
The following program modifies the previous example − one by incrementing the variable pointer so long as the address to which it points is either less than or equal to the address of the last element of the array, which is &var[MAX – 1] −
#include <stdio.h>
const int MAX = 3;
int main () {
int var[] = {10, 100, 200};
int i, *ptr;
/* let us have address of the first element in pointer */
ptr = var; i = 0;
while ( ptr <= &var[MAX - 1] ) {
printf("Address of var[%d] = %x\n", i, ptr );
printf("Value of var[%d] = %d\n", i, *ptr );
/* point to the next location */
ptr++;
i++;
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Address of var[0] = bfdbcb20
Value of var[0] = 10
Address of var[1] = bfdbcb24
Value of var[1] = 100
Address of var[2] = bfdbcb28
Value of var[2] = 200
C – Array of pointers
Before we understand the concept of arrays of pointers, let us consider the following example, which uses an array of 3 integers −
#include <stdio.h>
const int MAX = 3;
int main () {
int var[] = {10, 100, 200};
int i; for (i = 0; i < MAX; i++) {
printf("Value of var[%d] = %d\n", i, var[i] );
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of var[0] = 10
Value of var[1] = 100
Value of var[2] = 200
There may be a situation when we want to maintain an array, which can store pointers to an int or char or any other data type available. Following is the declaration of an array of pointers to an integer −
int *ptr[MAX];
It declares ptr as an array of MAX integer pointers. Thus, each element in ptr, holds a pointer to an int value. The following example uses three integers, which are stored in an array of pointers, as follows −
#include <stdio.h>
const int MAX = 3;
int main () {
int var[] = {10, 100, 200};
int i, *ptr[MAX];
for ( i = 0; i < MAX; i++) {
ptr[i] = &var[i];
/* assign the address of integer. */
}
for ( i = 0; i < MAX; i++) {
printf("Value of var[%d] = %d\n", i, *ptr[i] );
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of var[0] = 10
Value of var[1] = 100
Value of var[2] = 200
You can also use an array of pointers to character to store a list of strings as follows
#include <stdio.h>
const int MAX = 4;
int main ()
{ char *names[] = { "Zara Ali", "Hina Ali", "Nuha Ali", "Sara Ali" };
int i = 0; for ( i = 0; i < MAX; i++) {
printf("Value of names[%d] = %s\n", i, names[i] );
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of names[0] = Zara Ali
Value of names[1] = Hina Ali
Value of names[2] = Nuha Ali
Value of names[3] = Sara Ali
C – Pointer to Pointer
A pointer to a pointer is a form of multiple indirection, or a chain of pointers. Normally, a pointer contains the address of a variable. When we define a pointer to a pointer, the first pointer contains the address of the second pointer, which points to the location that contains the actual value as shown below.

A variable that is a pointer to a pointer must be declared as such. This is done by placing an additional asterisk in front of its name. For example, the following declaration declares a pointer to a pointer of type int −
int **var;
When a target value is indirectly pointed to by a pointer to a pointer, accessing that value requires that the asterisk operator be applied twice, as is shown below in the example −
#include <stdio.h>
int main () {
int var; int *ptr;
int **pptr; var = 3000;
/* take the address of var */
ptr = &var; /* take the address of ptr using address of operator & */
pptr = &ptr; /* take the value using pptr */
printf("Value of var = %d\n", var );
printf("Value available at *ptr = %d\n", *ptr );
printf("Value available at **pptr = %d\n", **pptr);
return 0;
}
When the above code is compiled and executed, it produces the following result −
Value of var = 3000
Value available at *ptr = 3000
Value available at **pptr = 3000
Passing pointers to functions
C programming allows passing a pointer to a function. To do so, simply declare the function parameter as a pointer type.
#include <stdio.h>
#include <time.h>
void getSeconds(unsigned long *par);
int main () {
unsigned long sec; getSeconds( &sec ); /* print the actual value */
printf("Number of seconds: %ld\n", sec );
return 0;
}
void getSeconds(unsigned long *par) {
/* get the current number of seconds */
*par = time( NULL );
return;
}
When the above code is compiled and executed, it produces the following result −
Number of seconds :1294450468
The function, which can accept a pointer, can also accept an array as shown in the following example :
#include <stdio.h> /* function declaration */
double getAverage(int *arr, int size);
int main () { /* an int array with 5 elements */
int balance[5] = {1000, 2, 3, 17, 50};
double avg; /* pass pointer to the array as an argument */
avg = getAverage( balance, 5 ) ;
/* output the returned value */
printf("Average value is: %f\n", avg );
return 0;
}
double getAverage(int *arr, int size) {
int i, sum = 0; double avg;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = (double)sum / size; return avg;
}
When the above code is compiled together and executed, it produces the following result −
Average value is: 214.40000
Return pointer from functions
We have seen in the last chapter how C programming allows to return an array from a function. Similarly, C also allows to return a pointer from a function. To do so, you would have to declare a function returning a pointer as in the following example −
int * myFunction() {
.
}
Second point to remember is that, it is not a good idea to return the address of a local variable outside the function, so you would have to define the local variable as static variable.
Now, consider the following function which will generate 10 random numbers and return them using an array name which represents a pointer, i.e., address of first array element.
#include <stdio.h>
#include <time.h>
/* function to generate and return random numbers. */
int * getRandom( ) {
static int r[10];
int i;
/* set the seed */
srand( (unsigned)time( NULL ) );
for ( i = 0; i < 10; ++i) {
r[i] = rand();
printf("%d\n", r[i] );
}
return r;
}
/* main function to call above defined function */
int main () {
/* a pointer to an int */
int *p;
int i;
p = getRandom();
for ( i = 0; i < 10; i++ ) {
printf("*(p + [%d]) : %d\n", i, *(p + i) );
}
return 0;
}
When the above code is compiled together and executed, it produces the following result −
1523198053
1187214107
1108300978
430494959
1421301276
930971084
123250484
106932140
1604461820
149169022
*(p + [0]) : 1523198053
*(p + [1]) : 1187214107
*(p + [2]) : 1108300978
*(p + [3]) : 430494959
*(p + [4]) : 1421301276
*(p + [5]) : 930971084
*(p + [6]) : 123250484
*(p + [7]) : 106932140
*(p + [8]) : 1604461820
*(p + [9]) : 149169022
by Jesmin Akther | Sep 22, 2021 | C Programming
Arrays in C
Arrays a kind of data structure that can store a fixed-size sequential collection of elements of the same type. An array is used to store a collection of data, but it is often more useful to think of an array as a collection of variables of the same type. Instead of declaring individual variables, such as number0, number1, …, and number99, you declare one array variable such as numbers and use numbers[0], numbers[1], and …, numbers[99] to represent individual variables. A specific element in an array is accessed by an index.
All arrays consist of contiguous memory locations. The lowest address corresponds to the first element and the highest address to the last element.

Declaring Arrays
type arrayName [ arraySize ];
This is called a single-dimensional array. The arraySize must be an integer constant greater than zero and type can be any valid C data type. For example, to declare a 10-element array called balance of type double, use this statement −
double balance[10];
Here balance is a variable array which is sufficient to hold up to 10 double numbers.
Initializing Arrays
You can initialize an array in C either one by one or using a single statement as follows −
double balance[5] = {1000.0, 2.0, 3.4, 7.0, 50.0};
The number of values between braces { } cannot be larger than the number of elements that we declare for the array between square brackets [ ].
If you omit the size of the array, an array just big enough to hold the initialization is created. Therefore, if you write −
double balance[] = {1000.0, 2.0, 3.4, 7.0, 50.0};
You will create exactly the same array as you did in the previous example. Following is an example to assign a single element of the array −
balance[4] = 50.0;
The above statement assigns the 5th element in the array with a value of 50.0. All arrays have 0 as the index of their first element which is also called the base index and the last index of an array will be total size of the array minus 1. Shown below is the pictorial representation of the array we discussed above −

Accessing Array Elements
An element is accessed by indexing the array name. This is done by placing the index of the element within square brackets after the name of the array. For example −
double salary = balance[9];
The above statement will take the 10th element from the array and assign the value to salary variable. The following example Shows how to use all the three above mentioned concepts viz. declaration, assignment, and accessing arrays.
#include <stdio.h>
int main () {
int n[ 10 ]; /* n is an array of 10 integers */
int i,j; /* initialize elements of array n to 0 */
for ( i = 0; i < 10; i++ ) {
n[ i ] = i + 100; /* set element at location i to i + 100 */
} /* output each array element's value */
for (j = 0; j < 10; j++ ) {
printf("Element[%d] = %d\n", j, n[j] );
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Element[0] = 100
Element[1] = 101
Element[2] = 102
Element[3] = 103
Element[4] = 104
Element[5] = 105
Element[6] = 106
Element[7] = 107
Element[8] = 108
Element[9] = 109
Multidimensional arrays
C programming language allows multidimensional arrays. Here is the general form of a multidimensional array declaration −
type name[size1][size2]...[sizeN];
For example, the following declaration creates a three dimensional integer array −
int threedim[5][10][4];
Two-dimensional Arrays
The simplest form of multidimensional array is the two-dimensional array. A two-dimensional array is, in essence, a list of one-dimensional arrays. To declare a two-dimensional integer array of size [x][y], you would write something as follows −
type arrayName [ x ][ y ];
Where type can be any valid C data type and arrayName will be a valid C identifier. A two-dimensional array can be considered as a table which will have x number of rows and y number of columns. A two-dimensional array a, which contains three rows and four columns can be shown as follows −
Thus, every element in the array a is identified by an element name of the form a[ i ][ j ], where ‘a’ is the name of the array, and ‘i’ and ‘j’ are the subscripts that uniquely identify each element in ‘a’.
Initializing Two-Dimensional Arrays
Multidimensional arrays may be initialized by specifying bracketed values for each row. Following is an array with 3 rows and each row has 4 columns.
int a[3][4] = {
{0, 1, 2, 3} , /* initializers for row indexed by 0 */
{4, 5, 6, 7} , /* initializers for row indexed by 1 */
{8, 9, 10, 11} /* initializers for row indexed by 2 */
};
The nested braces, which indicate the intended row, are optional. The following initialization is equivalent to the previous example −
int a[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11};
Accessing Two-Dimensional Array Elements
An element in a two-dimensional array is accessed by using the subscripts, i.e., row index and column index of the array. For example −
int val = a[2][3];
The above statement will take the 4th element from the 3rd row of the array. You can verify it in the above figure. Let us check the following program where we have used a nested loop to handle a two-dimensional array
#include <stdio.h>
int main () { /* an array with 5 rows and 2 columns*/
int a[5][2] = { {0,0}, {1,2}, {2,4}, {3,6},{4,8}};
int i, j; /* output each array element's value */
for ( i = 0; i < 5; i++ ) {
for ( j = 0; j < 2; j++ ) {
printf("a[%d][%d] = %d\n", i,j, a[i][j] );
} }
return 0;
}
When the above code is compiled and executed, it produces the following result −
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8
As explained above, you can have arrays with any number of dimensions, although it is likely that most of the arrays you create will be of one or two dimensions.
Passing Arrays as Function Arguments
Way-1
Formal parameters as a pointer −
void myFunction(int *param) {
.
}
Way-2
Formal parameters as a sized array −
void myFunction(int param[10]) {
.
}
Way-3
Formal parameters as an unsized array −
void myFunction(int param[]) {
. }
Example
Now, consider the following function, which takes an array as an argument along with another argument and based on the passed arguments, it returns the average of the numbers passed through the array as follows −
double getAverage(int arr[], int size) {
int i; double avg; double sum = 0;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = sum / size;
return avg;
}
Now, let us call the above function as follows −
#include <stdio.h> /* function declaration */
double getAverage(int arr[], int size);
int main () {
/* an int array with 5 elements */
int balance[5] = {1000, 2, 3, 17, 50};
double avg; /* pass pointer to the array as an argument */
avg = getAverage( balance, 5 ) ; /* output the returned value */
printf( "Average value is: %f ", avg );
return 0;
}
When the above code is compiled together and executed, it produces the following result −
Average value is: 214.400000
As you can see, the length of the array doesn’t matter as far as the function is concerned because C performs no bounds checking for formal parameters.
Return Arrays in C
If you want to return a single-dimension array from a function, you would have to declare a function returning a pointer as in the following example:
int * myFunction() {
.
}
Second point to remember is that C does not advocate to return the address of a local variable to outside of the function, so you would have to define the local variable as static variable.
Now, consider the following function which will generate 10 random numbers and return them using an array and call this function as follows −
#include <stdio.h> /* function to generate and return random numbers */
int * getRandom( ) {
static int r[10];
int i; /* set the seed */
srand( (unsigned)time( NULL ) );
for ( i = 0; i < 10; ++i) {
r[i] = rand();
printf( "r[%d] = %d\n", i, r[i]);
}
return r;
} /* main function to call above defined function */
int main () {
/* a pointer to an int */
int *p; int i;
p = getRandom();
for ( i = 0; i < 10; i++ ) {
printf( "*(p + %d) : %d\n", i, *(p + i));
}
return 0;
}
When the above code is compiled together and executed, it produces the following result −
r[0] = 313959809
r[1] = 1759055877
r[2] = 1113101911
r[3] = 2133832223
r[4] = 2073354073
r[5] = 167288147
r[6] = 1827471542
r[7] = 834791014
r[8] = 1901409888
r[9] = 1990469526
*(p + 0) : 313959809
*(p + 1) : 1759055877
*(p + 2) : 1113101911
*(p + 3) : 2133832223
*(p + 4) : 2073354073
*(p + 5) : 167288147
*(p + 6) : 1827471542
*(p + 7) : 834791014
*(p + 8) : 1901409888
*(p + 9) : 1990469526
Pointer to an Arrays
It is most likely that you would not understand this section until you are through with the chapter ‘Pointers’. Assuming you have some understanding of pointers in C, let us start: An array name is a constant pointer to the first element of the array. Therefore, in the declaration −
double balance[50];
balance is a pointer to &balance[0], which is the address of the first element of the array balance. Thus, the following program fragment assigns p as the address of the first element of balance −
double *p;
double balance[10];
p = balance;
It is legal to use array names as constant pointers, and vice versa. Therefore, *(balance + 4) is a legitimate way of accessing the data at balance[4].
Once you store the address of the first element in ‘p’, you can access the array elements using *p, *(p+1), *(p+2) and so on. Given below is the example to show all the concepts discussed above:
#include <stdio.h>
int main () { /* an array with 5 elements */
double balance[5] = {1000.0, 2.0, 3.4, 17.0, 50.0};
double *p; int i;
p = balance; /* output each array element's value */
printf( "Array values using pointer\n");
for ( i = 0; i < 5; i++ ) {
printf("*(p + %d) : %f\n", i, *(p + i) );
}
printf( "Array values using balance as address\n");
for ( i = 0; i < 5; i++ ) {
printf("*(balance + %d) : %f\n", i, *(balance + i) );
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
Array values using pointer
*(p + 0) : 1000.000000
*(p + 1) : 2.000000
*(p + 2) : 3.400000
*(p + 3) : 17.000000
*(p + 4) : 50.000000
Array values using balance as address
*(balance + 0) : 1000.000000
*(balance + 1) : 2.000000
*(balance + 2) : 3.400000
*(balance + 3) : 17.000000
*(balance + 4) : 50.000000
In the above example, p is a pointer to double, which means it can store the address of a variable of double type. Once we have the address in p, *p will give us the value available at the address stored in p, as we have shown in the above example.
by Jesmin Akther | Sep 22, 2021 | C Programming
Function in C
A function declaration tells the compiler about a function’s name, return type, and parameters. A function definition provides the actual body of the function.
Defining a Function
The general form of a function definition in C programming language is as follows −
return_type function_name( parameter list )
{
body of the function
}
A function definition in C programming consists of a function header and a function body. Here are all the parts of a function −
- Return Type − A function may return a value. The return_type is the data type of the value the function returns. Some functions perform the desired operations without returning a value. In this case, the return_type is the keyword void.
- Function Name − This is the actual name of the function. The function name and the parameter list together constitute the function signature.
- Parameters − A parameter is like a placeholder. When a function is invoked, you pass a value to the parameter. This value is referred to as actual parameter or argument. The parameter list refers to the type, order, and number of the parameters of a function. Parameters are optional; that is, a function may contain no parameters.
- Function Body − The function body contains a collection of statements that define what the function does.
Example
Given below is the source code for a function called max(). This function takes two parameters num1 and num2 and returns the maximum value between the two −
/* function returning the max between two numbers */
int max(int num1, int num2) {
/* local variable declaration */
int result;
if (num1 > num2)
result = num1;
else
result = num2;
return result;
}
Function Declarations
A function declaration tells the compiler about a function name and how to call the function. The actual body of the function can be defined separately.
A function declaration has the following parts −
return_type function_name( parameter list );
For the above defined function max(), the function declaration is as follows −
int max(int num1, int num2);
Parameter names are not important in function declaration only their type is required, so the following is also a valid declaration −
int max(int, int);
Function declaration is required when you define a function in one source file and you call that function in another file. In such case, you should declare the function at the top of the file calling the function.
Calling a Function
When a program calls a function, the program control is transferred to the called function. A called function performs a defined task and when its return statement is executed or when its function-ending closing brace is reached, it returns the program control back to the main program.
To call a function, you simply need to pass the required parameters along with the function name, and if the function returns a value, then you can store the returned value. For example −
#include <stdio.h> /* function declaration */
int max(int num1, int num2);
int main () { /* local variable definition */
int a = 100;
int b = 200;
int ret; /* calling a function to get max value */
ret = max(a, b);
printf( "Max value is : %d\n", ret );
return 0;
}
/* function returning the max between two numbers */
int max(int num1, int num2) {
/* local variable declaration */
int result;
if (num1 > num2)
result = num1;
else result = num2;
return result;
}
We have kept max() along with main() and compiled the source code. While running the final executable, it would produce the following result −
Max value is : 200
Function Arguments
If a function is to use arguments, it must declare variables that accept the values of the arguments. These variables are called the formal parameters of the function. Formal parameters behave like other local variables inside the function and are created upon entry into the function and destroyed upon exit.
While calling a function, there are two ways in which arguments can be passed to a function
Function call by Value
By default, C programming uses call by value to pass arguments. In general, it means the code within a function cannot alter the arguments used to call the function. Consider the function swap() definition as follows.
/* function definition to swap the values */
void swap(int x, int y) {
int temp;
temp = x; /* save the value of x */
x = y; /* put y into x */
y = temp; /* put temp into y */
return;
}
Now, let us call the function swap() by passing actual values as in the following example
#include <stdio.h> /* function declaration */
void swap(int x, int y);
int main () { /* local variable definition */
int a = 100;
int b = 200;
printf("Before swap, value of a : %d\n", a );
printf("Before swap, value of b : %d\n", b );
/* calling a function to swap the values */
swap(a, b);
printf("After swap, value of a : %d\n", a );
printf("After swap, value of b : %d\n", b );
return 0;
}
void swap(int x, int y) {
int temp;
temp = x;
/* save the value of x */
x = y;
/* put y into x */
y = temp;
/* put temp into y */
return;
}
Let us put the above code in a single C file, compile and execute it, it will produce the following result −
Before swap, value of a : 100
Before swap, value of b : 200
After swap, value of a : 100
After swap, value of b : 200
It shows that there are no changes in the values, though they had been changed inside the function.
To pass a value by reference, argument pointers are passed to the functions just like any other value. So accordingly you need to declare the function parameters as pointer types as in the following function swap(), which exchanges the values of the two integer variables pointed to, by their arguments.
/* function definition to swap the values */
void swap(int *x, int *y) {
int temp;
temp = *x;
/* save the value at address x */
*x = *y;
/* put y into x */
*y = temp; /* put temp into y */
return;
}
Let us now call the function swap() by passing values by reference as in the following example:
#include <stdio.h>
int main () {
/* local variable definition */
int a = 100;
int b = 200;
printf("Before swap, value of a : %d\n", a );
printf("Before swap, value of b : %d\n", b ); /* calling a function to swap the values */
swap(&a, &b);
printf("After swap, value of a : %d\n", a );
printf("After swap, value of b : %d\n", b );
return 0;
}
void swap(int *x, int *y) {
int temp;
temp = *x;
/* save the value of x */
*x = *y;
/* put y into x */
*y = temp;
/* put temp into y */
return;
}
Let us put the above code in a single C file, compile and execute it, to produce the following result −
Before swap, value of a : 100
Before swap, value of b : 200
After swap, value of a : 200
After swap, value of b : 100
It shows that the change has reflected outside the function as well, unlike call by value where the changes do not reflect outside the function.
by Jesmin Akther | Sep 22, 2021 | C Programming
Loop in C
Anyone may encounter situations, when a block of code needs to be executed several number of times. In general, statements are executed sequentially: The first statement in a function is executed first, followed by the second, and so on.
Loop available in C
Apart these loop
- nested for loop
- nested while loop
while loop
A while loop in C programming repeatedly executes a target statement as long as a given condition is true.
Syntax
The syntax of a while loop in C programming language is −
while(condition) {
statement(s);
}
Here, statement(s) may be a single statement or a block of statements. The condition may be any expression, and true is any nonzero value. The loop iterates while the condition is true.
#include <stdio.h>
int main () {
/* local variable definition */
int a = 10;
/* while loop execution */
while( a < 20 ) {
printf("value of a: %d\n", a);
a++;
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of a: 10
value of a: 11
value of a: 12
value of a: 13
value of a: 14
value of a: 15
value of a: 16
value of a: 17
value of a: 18
value of a: 19
for loop
A for loop is a repetition control structure that allows you to efficiently write a loop that needs to execute a specific number of times.
Syntax
The syntax of a for loop in C programming language is −
for ( init; condition; increment ) {
statement(s);
}
Here is the flow of control in a ‘for’ loop −
- The init step is executed first, and only once. This step allows you to declare and initialize any loop control variables. You are not required to put a statement here, as long as a semicolon appears.
- Next, the condition is evaluated. If it is true, the body of the loop is executed. If it is false, the body of the loop does not execute and the flow of control jumps to the next statement just after the ‘for’ loop.
- After the body of the ‘for’ loop executes, the flow of control jumps back up to the increment statement. This statement allows you to update any loop control variables. This statement can be left blank, as long as a semicolon appears after the condition.
- The condition is now evaluated again. If it is true, the loop executes and the process repeats itself (body of loop, then increment step, and then again condition). After the condition becomes false, the ‘for’ loop terminates.
#include <stdio.h>
int main () {
int a;
/* for loop execution */
for( a = 10; a < 20; a = a + 1 ){
printf("value of a: %d\n", a);
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of a: 10
value of a: 11
value of a: 12
value of a: 13
value of a: 14
value of a: 15
value of a: 16
value of a: 17
value of a: 18
value of a: 19
Unlike for and while loops, which test the loop condition at the top of the loop, the do…while loop in C programming checks its condition at the bottom of the loop.
do…while loop
A do…while loop is similar to a while loop, except the fact that it is guaranteed to execute at least one time.
Syntax
The syntax of a do…while loop in C programming language is −
do {
statement(s);
} while( condition );
Notice that the conditional expression appears at the end of the loop, so the statement(s) in the loop executes once before the condition is tested.
#include <stdio.h>
int main () {
/* local variable definition */
int a = 10;
/* do loop execution */
do {
printf("value of a: %d\n", a);
a = a + 1;
}while( a < 20 );
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of a: 10
value of a: 11
value of a: 12
value of a: 13
value of a: 14
value of a: 15
value of a: 16
value of a: 17
value of a: 18
value of a: 19
C programming allows to use one loop inside another loop. The following section shows a few examples to illustrate the concept.
Syntax
The syntax for a nested for loop statement in C is as follows −
for ( init; condition; increment ) {
for ( init; condition; increment ) {
statement(s);
}
statement(s);
}
The syntax for a nested while loop statement in C programming language is as follows −
while(condition) {
while(condition) {
statement(s);
}
statement(s);
}
The syntax for a nested do…while loop statement in C programming language is as follows −
do {
statement(s);
do {
statement(s);
}while( condition );
}while( condition );
A final note on loop nesting is that you can put any type of loop inside any other type of loop. For example, a ‘for’ loop can be inside a ‘while’ loop or vice versa.
#include <stdio.h>
int main () {
/* local variable definition */
int i, j;
for(i = 2; i<100; i++) {
for(j = 2; j <= (i/j); j++)
if(!(i%j)) break; // if factor found, not prime
if(j > (i/j)) printf("%d is prime\n", i);
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
2 is prime
3 is prime
5 is prime
7 is prime
11 is prime
13 is prime
17 is prime
19 is prime
23 is prime
29 is prime
31 is prime
37 is prime
41 is prime
43 is prime
47 is prime
53 is prime
59 is prime
61 is prime
67 is prime
71 is prime
73 is prime
79 is prime
83 is prime
89 is prime
97 is prime
Loop Control Statements
Loop control statements change execution from its normal sequence. When execution leaves a scope, all automatic objects that were created in that scope are destroyed
break statement
The break statement in C programming has the following two usages −
- When a break statement is encountered inside a loop, the loop is immediately terminated and the program control resumes at the next statement following the loop.
- It can be used to terminate a case in the switch statement (covered in the next chapter).
#include <stdio.h>
int main () {
/* local variable definition */
int a = 10;
/* while loop execution */
while( a < 20 ) {
printf("value of a: %d\n", a);
a++;
if( a > 15) {
/* terminate the loop using break statement */
break;
}
}
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of a: 10
value of a: 11
value of a: 12
value of a: 13
value of a: 14
value of a: 15
For the for loop, continue statement causes the conditional test and increment portions of the loop to execute. For the while and do…while loops, continue statement causes the program control to pass to the conditional tests.
Syntax
The syntax for a continue statement in C is as follows −
continue;
#include <stdio.h>
int main () {
/* local variable definition */
int a = 10;
/* do loop execution */
do {
if( a == 15) {
/* skip the iteration */
a = a + 1;
continue;
}
printf("value of a: %d\n", a);
a++;
} while( a < 20 );
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of a: 10
value of a: 11
value of a: 12
value of a: 13
value of a: 14
value of a: 16
value of a: 17
value of a: 18
value of a: 19
goto statement
A goto statement in C programming provides an unconditional jump from the ‘goto’ to a labeled statement in the same function.
Syntax
The syntax for a goto statement in C is as follows −
goto label;
..
.
label: statement;
Here label can be any plain text except C keyword and it can be set anywhere in the C program above or below to goto statement.
#include <stdio.h>
int main () {
/* local variable definition */
int a = 10;
/* do loop execution */
LOOP:do {
if( a == 15) {
/* skip the iteration */
a = a + 1;
goto LOOP;
}
printf("value of a: %d\n", a);
a++;
}while( a < 20 );
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of a: 10
value of a: 11
value of a: 12
value of a: 13
value of a: 14
value of a: 16
value of a: 17
value of a: 18
value of a: 19
The Infinite Loop
A loop becomes an infinite loop if a condition never becomes false. The for loop is traditionally used for this purpose. Since none of the three expressions that form the ‘for’ loop are required, you can make an endless loop by leaving the conditional expression empty.
#include <stdio.h>
int main () {
for( ; ; ) {
printf("This loop will run forever.\n");
}
return 0;
}
When the conditional expression is absent, it is assumed to be true. You may have an initialization and increment expression, but C programmers more commonly use the for(;;) construct to signify an infinite loop.
by Jesmin Akther | Sep 22, 2021 | C Programming
Decision making in C
Decision making structures require that the programmer specifies one or more conditions to be evaluated or tested by the program, along with a statement or statements to be executed if the condition is determined to be true, and optionally, other statements to be executed if the condition is determined to be false.
An if statement consists of a Boolean expression followed by one or more statements.
Syntax
The syntax of an ‘if’ statement in C programming language is −
if(boolean_expression) {
/* statement(s) will execute if the boolean expression is true */
}
If the Boolean expression evaluates to true, then the block of code inside the ‘if’ statement will be executed. If the Boolean expression evaluates to false, then the first set of code after the end of the ‘if’ statement (after the closing curly brace) will be executed.
An if statement can be followed by an optional else statement, which executes when the Boolean expression is false.
Syntax
The syntax of an if…else statement in C programming language is −
if(boolean_expression) {
/* statement(s) will execute if the boolean expression is true */
} else {
/* statement(s) will execute if the boolean expression is false */
}
If the Boolean expression evaluates to true, then the if block will be executed, otherwise, the else block will be executed.
#include <stdio.h>
int main()
{
int age;
printf("Enter your age:");
scanf("%d",&age);
if(age >=18)
{
printf("You are eligible for voting");
}
else
{
printf("You are not eligible for voting");
}
return 0;
}
Output:
Enter your age:14
You are not eligible for voting
switch statement
A switch statement allows a variable to be tested for equality against a list of values. Each value is called a case, and the variable being switched on is checked for each switch case.
Syntax
The syntax for a switch statement in C programming language is as follows −
switch(expression) {
case constant-expression :
statement(s);
break; /* optional */
case constant-expression :
statement(s);
break; /* optional */
/* you can have any number of case statements */
default : /* Optional */
statement(s);
}
The following rules apply to a switch statement −
- The expression used in a switch statement must have an integral or enumerated type, or be of a class type in which the class has a single conversion function to an integral or enumerated type.
- You can have any number of case statements within a switch. Each case is followed by the value to be compared to and a colon.
- The constant-expression for a case must be the same data type as the variable in the switch, and it must be a constant or a literal.
- When the variable being switched on is equal to a case, the statements following that case will execute until a break statement is reached.
- When a break statement is reached, the switch terminates, and the flow of control jumps to the next line following the switch statement.
- Not every case needs to contain a break. If no break appears, the flow of control will fall through to subsequent cases until a break is reached.
- A switch statement can have an optional default case, which must appear at the end of the switch. The default case can be used for performing a task when none of the cases is true. No break is needed in the default case.
#include <stdio.h>
int main() {
int num = 8;
switch (num) {
case 7:
printf("Num variable Value is 7");
break;
case 8:
printf("Num variable Value is 8");
break;
case 9:
printf("Num variable Value is 9");
break;
default:
printf("Out of range");
break;
}
return 0;
}
Output:
Num variable Value is 8
Another switch statement example using char datatype.
#include <stdio.h>
int main()
{
char ch='b';
switch (ch)
{
case 'd':
printf("Case is d ");
break;
case 'b':
printf("Case is b ");
break;
case 'c':
printf("Case is c ");
break;
default:
printf("Default ecase");
}
return 0;
}
Output:
Case is b
When the above code is compiled and executed, it produces the following result −
Well done
Your grade is B
It is possible to have a switch as a part of the statement sequence of an outer switch. Even if the case constants of the inner and outer switch contain common values, no conflicts will arise.
Syntax
The syntax for a nested switch statement is as follows −
switch(ch1) {
case 'A':
printf("This A is part of outer switch" );
switch(ch2) {
case 'A':
printf("This A is part of inner switch" );
break;
case 'B': /* case code */
}
break;
case 'B': /* case code */
}
Example
#include <stdio.h>
int main () {
/* local variable definition */
int a = 100; int b = 200;
switch(a) {
case 100: printf("This is part of outer switch\n", a );
switch(b) { case 200: printf("This is part of inner switch\n", a ); }
}
printf("Exact value of a is : %d\n", a );
printf("Exact value of b is : %d\n", b );
return 0;
}
When the above code is compiled and executed, it produces the following result −
This is part of outer switch
This is part of inner switch
Exact value of a is : 100
Exact value of b is : 200
The Conditional( ? : )Operator
conditional operator ? : can be used to replace if…else statements. It has the following general form −
Exp1 ? Exp2 : Exp3;
Where Exp1, Exp2, and Exp3 are expressions. Notice the use and placement of the colon.
The value of a ? expression is determined like this −
- Exp1 is evaluated. If it is true, then Exp2 is evaluated and becomes the value of the entire ? expression.
- If Exp1 is false, then Exp3 is evaluated and its value becomes the value of the expression.
#include<stdio.h>
int main()
{
float num1, num2, max;
printf("Enter two numbers: ");
scanf("%f %f", &num1, &num2);
max = (num1 > num2) ? num1 : num2;
printf("Maximum of between %.2f and %.2f is = %.2f",
num1, num2, max);
return 0;
}
Output:-
Enter two numbers: 12.5 10.5
Maximum of between 12.50 and 10.50 is = 12.50
by Jesmin Akther | Sep 9, 2021 | C Programming
Build-in Function Constants and Literals
C programming Build-in Function will focus here with printf and scanf, Such as:
C printf and scanf functions: printf() and scanf() functions are inbuilt library functions in C programming language which are available in C library by default. These functions are declared and related macros are defined in “stdio.h” which is a header file in C language.
We have to include “stdio.h” file as shown in below C program to make use of these printf() and scanf() library functions in C language.
1. PRINTF() FUNCTION IN C LANGUAGE:
In C programming language, printf() function is used to print the (“character, string, float, integer, octal and hexadecimal values”) onto the output screen. We use printf() function with %d format specifier to display the value of an integer variable. Similarly %c is used to display character, %f for float variable, %s for string variable, %lf for double and %x for hexadecimal variable.
To generate a newline,we use “\n” in C printf() statement.
EXAMPLE PROGRAM FOR C PRINTF() FUNCTION:
#include <stdio.h>
#include <math.h>
int main()
{
char ch = 'A';
char str[20] = "draftsbook.com";
float flt = 10.234;
int no = 150;
double dbl = 20.123456;
printf("Character is %c \n", ch);
printf("String is %s \n" , str);
printf("Float value is %f \n", flt);
printf("Integer value is %d\n" , no);
printf("Double value is %lf \n", dbl);
printf("Octal value is %o \n", no);
printf("Hexadecimal value is %x \n", no);
return 0;
}
OUTPUT
Character is A
String is draftsbook.com
Float value is 10.234000
Integer value is 150
Double value is 20.123456
Octal value is 226
Hexadecimal value is 96
2. SCANF FUNCTION IN C LANGUAGE:
In C programming language, scanf() function is used to read character, string, numeric data from keyboard
Consider below example program where user enters a character. This value is assigned to the variable “ch” and then displayed. Then, user enters a string and this value is assigned to the variable “str” and then displayed.
EXAMPLE PROGRAM FOR C PRINTF AND SCANF FUNCTIONS IN C :
#include <stdio.h>
int main()
{
char ch;
char str[100];
printf("Enter any character \n");
scanf("%c", &ch);
printf("Entered character is %c \n", ch);
printf("Enter any string ( upto 100 character ) \n");
scanf("%s", &str);
printf("Entered string is %s \n", str);
}
OUTPUT :
Enter any character
a
Entered character is a
Enter any string ( upto 100 character )
hai
Entered string is hai
The format specifier %d is used in scanf() statement. So that, the value entered is received as an integer and %s for string.
| Function |
#include |
What It Does |
| sqrt() |
math.h |
Calculates the square root of a floating-point value |
| pow() |
math.h |
Returns the result of a floating-point value raised to a
certain power |
| abs() |
stdlib.h |
Returns the absolute value (positive value) of an integer |
| floor() |
math.h |
Rounds up a floating-point value to the next whole number
(nonfractional) value |
| ceil() |
math.h |
Rounds down a floating-point value to the next whole
number |
EXAMPLE: Program for Math function in C
#include <stdio.h>
#include <math.h>
int main()
{
float result,value;
printf("Input a float value: ");
scanf("%f",&value);
result = sqrt(value);
printf("The square root of %.2f is %.2f\n",
value,result);
result = pow(value,3);
printf("%.2f to the 3rd power is %.2f\n",
value,result);
result = floor(value);
printf("The floor of %.2f is %.2f\n",
value,result);
result = ceil(value);
printf("And the ceiling of %.2f is %.2f\n",
value,result);
return(0);
}
OUTPUT:
Input a float value: 4
The square root of 4.00 is 2.00
4.00 to the 3rd power is 64.00
The floor of 4.00 is 4.00
And the ceiling of 4.00 is 4.00
Write a C program to find distance travel by an object. ( s=ut+1/2at^2 )
#include <stdio.h>
#include <math.h>
void main()
{
float s;
int u, t, a;
printf("Please enter the initial velocity = ");
scanf("%d",&u);
printf("Please enter the time = ");
scanf("%d",&t);
printf("Please enter acceleration = ");
scanf("%d",&a);
s=(u*t)+(0.5*a*t*t);
printf("Total distance is %f",s);
}
OUTPUT
Please enter the initial velocity = 10
Please enter the time = 3
Please enter acceleration = 2
Total distance is 39.000000
Write a C program to find distance travel by an object where initial velocity is zero. ( s=vt)
#include <stdio.h>
int main()
{
float s;
int v, t;
printf("Please enter the initial velocity = ");
scanf("%d",&v);
printf("Please enter the time = ");
scanf("%d",&t);
s=(v*t);
printf("Total distance is %f",s);
return 0;
}
OUTPUT:
Please enter the initial velocity = 10
Please enter the time = 5
Total distance is 50.000000
Constants and Literals
Constants refer to fixed values that the program may not alter during its execution. These fixed values are also called literals. Constants can be of any of the basic data types like an integer constant, a floating constant, a character constant, or a string literal. There are enumeration constants as well.
Integer Literals
An integer literal can be a decimal, octal, or hexadecimal constant. An integer literal can also have a suffix that is a combination of U and L, for unsigned and long, respectively. The suffix can be uppercase or lowercase and can be in any order.
Here are some examples of integer literals −
212 /* Legal */
215u /* Legal */
0xFeeL /* Legal */
078 /* Illegal: 8 is not an octal digit */
032UU /* Illegal: cannot repeat a suffix */
Following are other examples of various types of integer literals −
75 /* decimal */
0223 /* octal */
0x2b /* hexadecimal */
40 /* int */
40u /* unsigned int */
40l /* long */
40ul /* unsigned long */
Floating-point Literals
A floating-point literal has an integer part, a decimal point, a fractional part, and an exponent part. You can represent floating point literals either in decimal form or exponential form. The signed exponent is introduced by e or E.
Here are some examples of floating-point literals −
3.14159 /* Legal */
314159E-5L /* Legal */
510E /* Illegal: incomplete exponent */
210f /* Illegal: no decimal or exponent */
.e55 /* Illegal: missing integer or fraction */
Character Constants
- Character literals are enclosed in single quotes, e.g., ‘x’ can be stored in a simple variable of char type.
- A character literal can be a plain character (e.g., ‘x’), an escape sequence (e.g., ‘\t’), or a universal character (e.g., ‘\u02C0’).
- There are certain characters in C that represent special meaning when preceded by a backslash for example, newline (\n) or tab (\t).
#include <stdio.h>
int main()
{
printf("Hello\tWorld\n\n");
return 0;
}
When the above code is compiled and executed, it produces the following result −
Hello World
String Literals
String literals or constants are enclosed in double quotes “”. A string contains characters that are similar to character literals: plain characters, escape sequences, and universal characters. You can break a long line into multiple lines using string literals and separating them using white spaces.
Here are some examples of string literals. All the three forms are identical strings.
"hello, dear"
"hello, \
dear"
"hello, " "d" "ear"
Defining Constants
There are two simple ways in C to define constants −
- Using #define preprocessor.
- Using const keyword.
The #define Preprocessor
Given below is the form to use #define preprocessor to define a constant −
#define identifier value
The following example explains it in detail:
#include <stdio.h>
#define LENGTH 10
#define WIDTH 5
#define NEWLINE '\n'
int main() {
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE); return 0;
}
When the above code is compiled and executed, it produces the following result :
value of area : 50
The const Keyword
You can use const prefix to declare constants with a specific type as follows −
const type variable = value;
The following example explains it in detail :
#include <stdio.h>
int main() {
const int LENGTH = 10;
const int WIDTH = 5;
const char NEWLINE = '\n';
int area;
area = LENGTH * WIDTH;
printf("value of area : %d", area);
printf("%c", NEWLINE); return 0;
}
When the above code is compiled and executed, it produces the following result:
value of area : 50
Note that it is a good programming practice to define constants in CAPITALS.
A storage class defines the scope (visibility) and life-time of variables and/or functions within a C Program. They precede the type that they modify. We have four different storage classes in a C program −
- auto
- register
- static
- extern
The auto Storage Class
The auto storage class is the default storage class for all local variables.
{
int mount;
auto int month;
}
The example above defines two variables with in the same storage class. ‘auto’ can only be used within functions, i.e., local variables.
The register Storage Class
The register storage class is used to define local variables that should be stored in a register instead of RAM. This means that the variable has a maximum size equal to the register size (usually one word) and can’t have the unary ‘&’ operator applied to it (as it does not have a memory location).
{
register int miles;
}
The register should only be used for variables that require quick access such as counters. Variable MIGHT be stored in a register depending on hardware and implementation restrictions.
The static Storage Class
The static storage class instructs the compiler to keep a local variable in existence during the life-time of the program instead of creating and destroying it each time it comes into and goes out of scope. Therefore, making local variables static allows them to maintain their values between function calls. In C programming, when static is used on a global variable, it causes only one copy of that member to be shared by all the objects of its class.
#include <stdio.h>
/* function declaration */
void func(void); static int count = 5;
/* global variable */
main() {
while(count--) {
func();
}
return 0;
}
/* function definition */
void func( void ) {
static int i = 5;
/* local static variable */
i++;
printf("i is %d and count is %d\n", i, count);
}
When the above code is compiled and executed, it produces the following result −
i is 6 and count is 4
i is 7 and count is 3
i is 8 and count is 2
i is 9 and count is 1
i is 10 and count is 0
The extern Storage Class
When you have multiple files and you define a global variable or function, which will also be used in other files, then extern will be used in another file to provide the reference of defined variable or function. Just for understanding, extern is used to declare a global variable or function in another file.
The extern modifier is most commonly used when there are two or more files sharing the same global variables or functions as explained below.
First File: main.c
#include <stdio.h>
int count ;
extern void write_extern();
main() {
count = 5;
write_extern();
}
Second File: support.c
#include <stdio.h>
extern int count;
void write_extern(void) {
printf("count is %d\n", count);
}
Here, extern is being used to declare count in the second file, where as it has its definition in the first file, main.c. Now, compile these two files as follows −
$gcc main.c support.c
It will produce the executable program a.out. When this program is executed, it produces the following result −
count is 5
by Jesmin Akther | Sep 2, 2021 | C Programming
C Programming
C programming language is a MUST for students and working professionals to become a great Software Engineer specially when they are working in Software Development Domain. I will list down some of the key advantages of learning C Programming:
- Easy to learn
- Structured language
- It produces efficient programs
- It can handle low-level activities
- It can be compiled on a variety of computer platforms
Hello World Programming.
Just to give you a little excitement about C programming, I’m going to give you a small conventional C Programming Hello World program,
#include <stdio.h>
int main() {
/* my first program in C */
printf("Hello, World! \n");
return 0;
}
Let us take a look at the various parts of the above program −
- The first line of the program #include <stdio.h> is a preprocessor command, which tells a C compiler to include stdio.h file before going to actual compilation.
- The next line int main() is the main function where the program execution begins.
- The next line /*…*/ will be ignored by the compiler and it has been put to add additional comments in the program. So such lines are called comments in the program.
- The next line printf(…) is another function available in C which causes the message “Hello, World!” to be displayed on the screen.
- The next line return 0; terminates the main() function and returns the value 0.
Tokens in C
A C program consists of various tokens and a token is either a keyword, an identifier, a constant, a string literal, or a symbol. For example, the following C statement consists of five tokens −
printf("Hello, World! \n");
The individual tokens are −
printf
(
"Hello, World! \n"
)
;
Semicolons
In a C program, the semicolon is a statement terminator. That is, each individual statement must be ended with a semicolon. It indicates the end of one logical entity.
Given below are two different statements −
printf("Hello, World! \n");
return 0;
Comments
Comments are like helping text in your C program and they are ignored by the compiler. They start with /* and terminate with the characters */ as shown below −
/* my first program in C */
You cannot have comments within comments and they do not occur within a string or character literals.
Identifiers
A C identifier is a name used to identify a variable, function, or any other user-defined item. An identifier starts with a letter A to Z, a to z, or an underscore ‘_’ followed by zero or more letters, underscores, and digits (0 to 9). C does not allow punctuation characters such as @, $, and % within identifiers. C is a case-sensitive programming language. Thus, Manpower and manpower are two different identifiers in C. Here are some examples of acceptable identifiers −
mohd zara abc move_name a_123
myname50 _temp j a23b9 retVal
Keywords
The following list shows the reserved words in C. These reserved words may not be used as constants or variables or any other identifier names.
| auto |
else |
long |
switch |
| break |
enum |
register |
typedef |
| case |
extern |
return |
union |
| char |
float |
short |
unsigned |
| const |
for |
signed |
void |
| continue |
goto |
sizeof |
volatile |
| default |
if |
static |
while |
| do |
int |
struct |
_Packed |
| double |
|
|
|
Whitespace in C
A line containing only whitespace, possibly with a comment, is known as a blank line, and a C compiler totally ignores it.
Whitespace is the term used in C to describe blanks, tabs, newline characters and comments. Whitespace separates one part of a statement from another and enables the compiler to identify where one element in a statement, such as int, ends and the next element begins. Therefore, in the following statement −
int age;
there must be at least one whitespace character (usually a space) between int and age for the compiler to be able to distinguish them. On the other hand, in the following statement −
fruit = apples + oranges; // get the total fruit
no whitespace characters are necessary between fruit and =, or between = and apples, although you are free to include some if you wish to increase readability.
Data types in c refer to an extensive system used for declaring variables or functions of different types. The type of a variable determines how much space it occupies in storage and how the bit pattern stored is interpreted.
The types in C can be classified as follows −
| Sr.No. |
Types & Description |
| 1 |
Basic Types
They are arithmetic types and are further classified into: (a) integer types and (b) floating-point types. |
| 2 |
Enumerated types
They are again arithmetic types and they are used to define variables that can only assign certain discrete integer values throughout the program. |
| 3 |
The type void
The type specifier void indicates that no value is available. |
| 4 |
Derived types
They include (a) Pointer types, (b) Array types, (c) Structure types, (d) Union types and (e) Function types. |
The array types and structure types are referred collectively as the aggregate types. The type of a function specifies the type of the function’s return value. We will see the basic types in the following section, where as other types will be covered in the upcoming chapters.
Integer Types
The following table provides the details of standard integer types with their storage sizes and value ranges −
| Type |
Storage size |
Value range |
| char |
1 byte |
-128 to 127 or 0 to 255 |
| unsigned char |
1 byte |
0 to 255 |
| signed char |
1 byte |
-128 to 127 |
| int |
2 or 4 bytes |
-32,768 to 32,767 or -2,147,483,648 to 2,147,483,647 |
| unsigned int |
2 or 4 bytes |
0 to 65,535 or 0 to 4,294,967,295 |
| short |
2 bytes |
-32,768 to 32,767 |
| unsigned short |
2 bytes |
0 to 65,535 |
| long |
8 bytes or (4bytes for 32 bit OS) |
-9223372036854775808 to 9223372036854775807 |
| unsigned long |
8 bytes |
0 to 18446744073709551615 |
To get the exact size of a type or a variable on a particular platform, you can use the sizeof operator. The expressions sizeof(type) yields the storage size of the object or type in bytes.
Floating-Point Types
The following table provide the details of standard floating-point types with storage sizes and value ranges and their precision −
| Type |
Storage size |
Value range |
Precision |
| float |
4 byte |
1.2E-38 to 3.4E+38 |
6 decimal places |
| double |
8 byte |
2.3E-308 to 1.7E+308 |
15 decimal places |
| long double |
10 byte |
3.4E-4932 to 1.1E+4932 |
19 decimal places |
The header file float.h defines macros that allow you to use these values and other details about the binary representation of real numbers in your programs.
The void Type
The void type specifies that no value is available. It is used in three kinds of situations −
| Sr.No. |
Types & Description |
| 1 |
Function returns as void
There are various functions in C which do not return any value or you can say they return void. A function with no return value has the return type as void. For example, void exit (int status); |
| 2 |
Function arguments as void
There are various functions in C which do not accept any parameter. A function with no parameter can accept a void. For example, int rand(void); |
| 3 |
Pointers to void
A pointer of type void * represents the address of an object, but not its type. For example, a memory allocation function void *malloc( size_t size ); returns a pointer to void which can be casted to any data type. |
A variable is nothing but a name given to a storage area that our programs can manipulate. Each variable in C has a specific type, which determines the size and layout of the variable’s memory; the range of values that can be stored within that memory; and the set of operations that can be applied to the variable.
The name of a variable can be composed of letters, digits, and the underscore character. It must begin with either a letter or an underscore. Upper and lowercase letters are distinct because C is case-sensitive. Based on the basic types explained in the previous chapter, there will be the following basic variable types −
| Sr.No. |
Type & Description |
| 1 |
char
Typically a single octet(one byte). It is an integer type. |
| 2 |
int
The most natural size of integer for the machine. |
| 3 |
float
A single-precision floating point value. |
| 4 |
double
A double-precision floating point value. |
| 5 |
void
Represents the absence of type. |
C programming language also allows to define various other types of variables, which we will cover in subsequent chapters like Enumeration, Pointer, Array, Structure, Union, etc. For this chapter, let us study only basic variable types.
Variable Definition in C
A variable definition tells the compiler where and how much storage to create for the variable. A variable definition specifies a data type and contains a list of one or more variables of that type as follows −
type variable_list;
Here, type must be a valid C data type including char, w_char, int, float, double, bool, or any user-defined object; and variable_list may consist of one or more identifier names separated by commas. Some valid declarations are shown here −
int i, j, k;
char c, ch;
float f, salary;
double d;
The line int i, j, k; declares and defines the variables i, j, and k; which instruct the compiler to create variables named i, j and k of type int.
Variables can be initialized (assigned an initial value) in their declaration. The initializer consists of an equal sign followed by a constant expression as follows −
type variable_name = value;
Some examples are −
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.
For definition without an initializer: variables with static storage duration are implicitly initialized with NULL (all bytes have the value 0); the initial value of all other variables are undefined.
Variable Declaration in C
A variable declaration provides assurance to the compiler that there exists a variable with the given type and name so that the compiler can proceed for further compilation without requiring the complete detail about the variable. A variable definition has its meaning at the time of compilation only, the compiler needs actual variable definition at the time of linking the program.
A variable declaration is useful when you are using multiple files and you define your variable in one of the files which will be available at the time of linking of the program. You will use the keyword extern to declare a variable at any place. Though you can declare a variable multiple times in your C program, it can be defined only once in a file, a function, or a block of code.
Example
Try the following example, where variables have been declared at the top, but they have been defined and initialized inside the main function:
#include <stdio.h>
// Variable declaration:
extern int a, b;
extern int c;
extern float f;
int main () {
/* variable definition: */
int a, b;
int c;
float f;
/* actual initialization */
a = 10;
b = 20;
c = a + b;
printf("value of c : %d \n", c);
f = 70.0/3.0;
printf("value of f : %f \n", f);
return 0;
}
When the above code is compiled and executed, it produces the following result −
value of c : 30
value of f : 23.333334